Clear Sky Science · fr
Faire passer le paradigme des modèles fondamentaux rétiniens des coupes aux volumes pour la tomographie par cohérence optique
Pourquoi cela compte pour la santé oculaire
Les examens oculaires deviennent un outil de première ligne pour repérer des maladies menaçant la vision bien avant que la personne ne remarque des symptômes. Cette étude explore une nouvelle façon pour l’intelligence artificielle (IA) d’interpréter l’un des examens les plus puissants dont nous disposons — la tomographie par cohérence optique (OCT) — en le traitant non pas comme une image isolée, mais comme un volume 3D proche d’un court film. Ce changement améliore la capacité de l’IA à reconnaître les principales causes de cécité, et pourrait permettre un dépistage plus précoce et plus fiable dans les cliniques du monde entier.
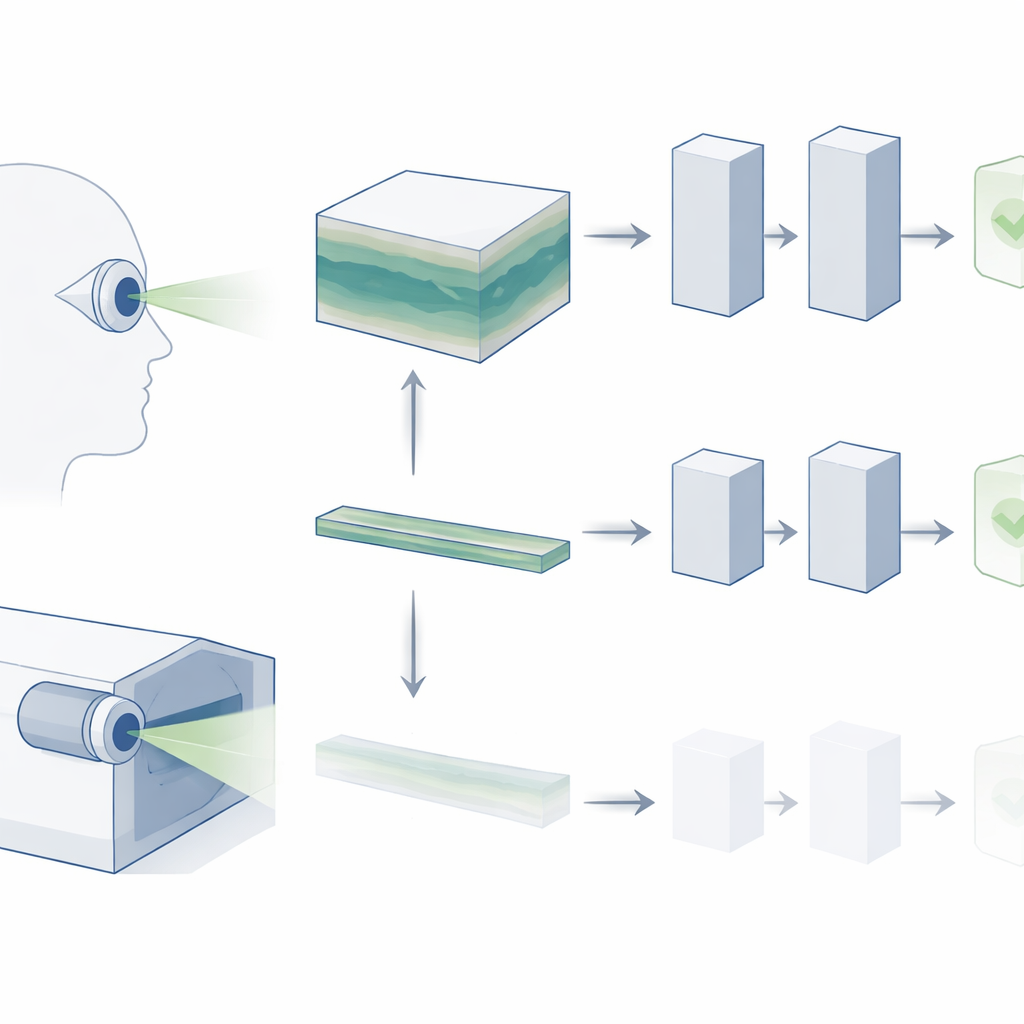
Des instantanés plats aux vues 3D
L’OCT génère un bloc tridimensionnel de la rétine, composé de nombreuses coupes transversales fines. En pratique clinique, les ophtalmologistes parcourent ce volume complet pour rechercher des signes de maladie, comme de minuscules dépôts dans la dégénérescence maculaire liée à l’âge (DMLA) ou des modifications structurelles subtiles dans le glaucome. Pourtant, la plupart des « modèles fondamentaux » existants pour images rétiniennes ignorent cette riche structure 3D. Ils se contentent généralement d’une seule coupe centrale, en partant du principe qu’elle contient l’information la plus importante. Les auteurs soutiennent que ce raccourci élimine une grande partie de ce que les cliniciens utilisent réellement, et pourrait expliquer pourquoi les systèmes d’IA peinent encore à répondre aux besoins diagnostiques du monde réel.
Emprunter des idées à l’analyse vidéo
Plutôt que de traiter l’OCT comme une image isolée, les chercheurs le considèrent comme une courte vidéo : une séquence de coupes parcourant la profondeur de la rétine. Ils adoptent un modèle fondamental vidéo de pointe appelé V-JEPA, initialement entraîné sur des vidéos « naturelles » du quotidien, et l’adaptent à l’OCT. Comme d’autres systèmes d’IA modernes, V-JEPA subit d’abord un entraînement auto-supervisé, apprenant à prédire et à reconstituer des informations manquantes sans avoir besoin d’étiquettes. Cela crée un puissant « vocabulaire visuel » général que le modèle peut réutiliser. Les chercheurs affinent ensuite V-JEPA sur des jeux de données OCT étiquetés plus petits afin qu’il puisse distinguer yeux sains et yeux malades.
Tests à travers pays et pathologies
Pour savoir si cette approche 3D aide vraiment, l’équipe a comparé V-JEPA à trois solides modèles fondamentaux basés sur des images, dont deux entraînés spécifiquement sur des images rétiniennes et un entraîné sur des photographies naturelles. Tous les modèles utilisaient des architectures de réseaux neuronaux sous-jacentes similaires, de sorte que les différences de performance reflètent principalement la manière dont ils exploitent les données, et non leur taille ou complexité. Les modèles devaient détecter deux maladies oculaires majeures — la neuropathie optique glaucomateuse (une forme de glaucome) et la DMLA — en utilisant cinq jeux de données OCT indépendants collectés aux États-Unis, en Chine, en Israël et en Iran, couvrant différents appareils, populations et profils de maladie.
Des réponses plus nettes grâce à l’information 3D complète
Sur l’ensemble de ces jeux de données, le modèle vidéo V-JEPA a égalé ou surpassé tous les modèles basés sur des images, atteignant une aire sous la courbe ROC moyenne de 0,94 contre 0,90 pour le meilleur modèle mono-coupe — un gain statistiquement significatif. L’avantage était le plus marqué sur certains des jeux de données les plus difficiles, où il était plus dur de distinguer cas malades et non malades. L’analyse des cartes d’attention du modèle a montré que V-JEPA se concentre sur des structures pertinentes réparties sur plusieurs coupes, et pas seulement la coupe centrale. L’analyse des erreurs a révélé que les modèles mono-coupe manquaient souvent des cas où la pathologie était absente ou discrète dans la coupe médiane mais présente ailleurs dans le volume. En augmentant efficacement la couverture spatiale et en apprenant comment les coupes se relient entre elles, le modèle 3D a mieux saisi ces motifs.
Équilibrer performance et praticité
Les auteurs ont également comparé V-JEPA à d’autres manières d’exploiter l’information 3D, comme les réseaux convolutionnels tridimensionnels classiques entraînés depuis zéro et une méthode « 2,5D » qui traite de nombreuses coupes une par une avec un modèle d’image puis combine les résultats. V-JEPA a généralement surpassé ces alternatives tout en nécessitant moins de calcul que la stratégie 2,5D. Fait important, ses bénéfices demeuraient même lorsque seules des quantités modestes de données étiquetées étaient disponibles, et ses performances continuaient de s’améliorer avec l’augmentation des données d’entraînement, alors que les modèles basés sur des images avaient tendance à plafonner. Bien qu’analyser des volumes soit plus lent que lire une seule coupe, le temps de traitement supplémentaire restait faible — de l’ordre de quelques centièmes de seconde par examen sur du matériel moderne.
Ce que cela signifie pour les soins oculaires futurs
Pour les non-spécialistes, la conclusion est simple : laisser l’IA voir la rétine en 3D, comme le font les cliniciens, conduit à une détection automatisée plus précise des maladies aveuglantes courantes. Ce travail suggère que les futurs « modèles fondamentaux » pour l’imagerie oculaire devraient être conçus dès le départ pour traiter des volumes OCT complets, et non des instantanés individuels. Associés à un partage de données plus large et, à terme, à une intégration avec d’autres informations cliniques, ces modèles pourraient contribuer à offrir un dépistage cohérent et de haute qualité du glaucome et de la dégénérescence maculaire à beaucoup plus de cliniques et de patients dans le monde.
Citation: Judkiewicz, R., Berkowitz, E., Meisel, M. et al. Shifting the retinal foundation models paradigm from slices to volumes for optical coherence tomography. npj Digit. Med. 9, 314 (2026). https://doi.org/10.1038/s41746-026-02496-7
Mots-clés: tomographie par cohérence optique, IA pour l’imagerie rétinienne, dégénérescence maculaire liée à l’âge, détection du glaucome, modèles fondamentaux vidéo