Clear Sky Science · tr
Optik kohere tomografi için retina temel modelleri paradigmasını dilimlerden hacimlere kaydırmak
Göz sağlığı için bunun önemi
Göz taramaları, bir kişi henüz belirtileri fark etmeden görmeyi tehdit eden hastalıkları tespit etmek için ilk savunma hattı haline geliyor. Bu çalışma, yapay zekânın (AI) elimizdeki en güçlü göz taramalarından biri olan optik koherens tomografiyi (OCT) tek bir resim olarak değil, tam bir 3B film benzeri hacim olarak ele alarak okuması için yeni bir yolu araştırıyor. Bu yaklaşım, AI’nın körlüğe yol açan başlıca nedenleri daha iyi tanımasını sağlıyor gibi görünüyor ve daha erken ve daha güvenilir taramaların dünyanın birçok kliniğine ulaşma potansiyelini taşıyor.
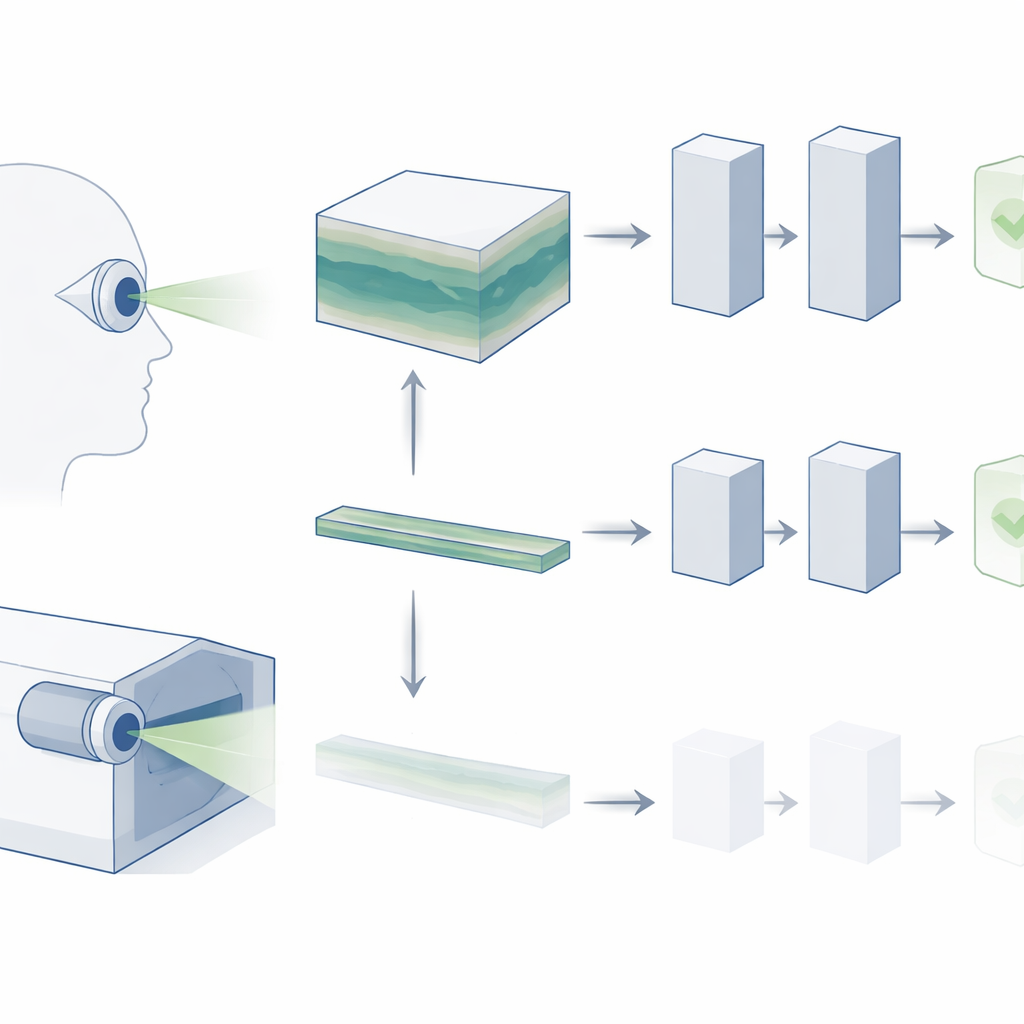
Düz anlık görüntülerden 3B görünümlere
OCT, birçok ince kesitten oluşturulmuş üç boyutlu bir retina bloğu üretir. Günlük klinik uygulamada göz doktorları hastalığın belirtilerini aramak için bu hacmi baştan sona kaydırır; örneğin yaşa bağlı makula dejenerasyonunda (AMD) küçük birikintiler veya glokomda ince yapısal değişiklikler gibi. Ancak mevcut retina görüntüleri için geliştirilmiş temel AI modellerinin çoğu bu zengin 3B yapıyı görmezden geliyor. Genellikle en önemli bilgiyi içerdiği varsayılan tek bir merkezi kesite bakıyorlar. Yazarlar, bu kestirme yolun klinisyenlerin gerçekte kullandıklarının büyük bir kısmını yok saydığını ve AI sistemlerinin gerçek dünya tanı ihtiyaçlarına hâlâ yetişememesinin bir nedeni olabileceğini savunuyor.
Video analizinden ödünç alınan fikirler
Araştırmacılar OCT’u tek bir resim gibi işlemek yerine onu kısa bir video gibi ele alıyor: retinanın derinliği boyunca ilerleyen bir kesit dizisi. Günlük doğal videolar üzerinde önceden eğitilmiş, V-JEPA adında son teknoloji bir video temel modelini benimseyip OCT’ye uyarlıyorlar. Diğer modern AI sistemleri gibi V-JEPA da önce etiket gerekmeden eksik bilgileri tahmin edip doldurmaya çalışarak kendi kendine denetimli şekilde eğitiliyor. Bu, modelin daha sonra yeniden kullanabileceği güçlü bir genel "görsel sözlük" oluşturuyor. Araştırmacılar daha sonra V-JEPA’yı küçük, etiketli OCT veri setleri üzerinde ince ayar yaparak sağlıklı ve hastalıklı gözleri ayırt edebilmesini sağlıyorlar.
Ülkeler ve hastalıklar arasında test
Bu 3B yaklaşımın gerçekten yardımcı olup olmadığını görmek için ekip, V-JEPA’yı görüntü tabanlı üç güçlü temel modelle karşılaştırdı; bunların ikisi özellikle retina görüntüleri üzerinde, biri ise doğal fotoğraflar üzerinde eğitilmişti. Tüm modeller benzer temel sinir ağı mimarilerini kullandığından performanstaki farklar büyük ölçüde veriyi nasıl kullandıklarını yansıtıyor, boyut veya karmaşıklıktan ziyade. Modellerden iki önemli göz hastalığını—glokomun bir türü olan glaukomatöz optik nöropati ile AMD—ABD, Çin, İsrail ve İran’da toplanmış, farklı tarayıcıları, popülasyonları ve hastalık örüntülerini kapsayan beş bağımsız OCT veri seti kullanarak tespit etmeleri istendi.
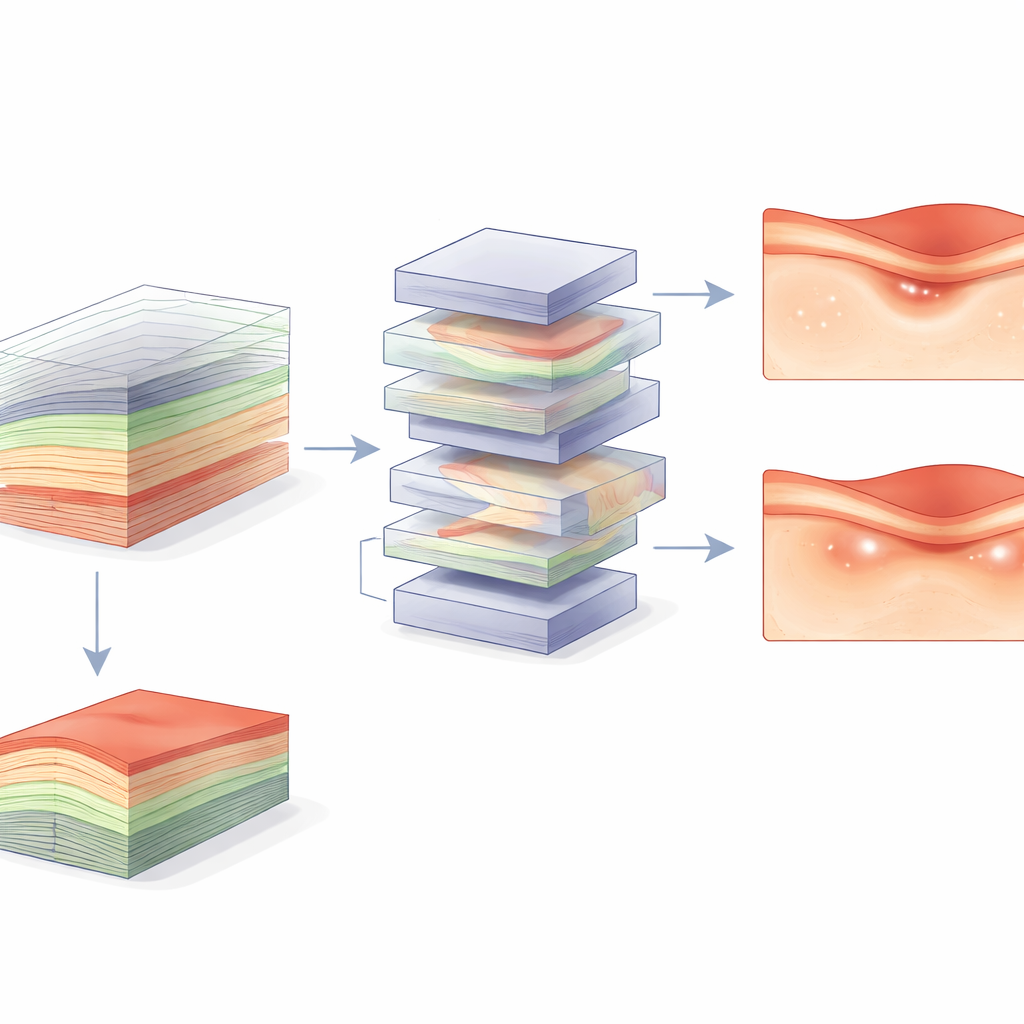
Tam 3B bilgiden daha net yanıtlar
Bu veri setlerinde video tabanlı V-JEPA, görüntü tabanlı tüm modellerle karşılaştırıldığında ya onlara eşit performans gösterdi ya da daha iyi oldu; ROC eğrisi altındaki ortalama alanı 0,94’e ulaştı; en iyi tek kesit model için bu değer 0,90 idi—istatistiksel olarak anlamlı bir artış. Avantaj bazı daha zor veri kümelerinde en büyüktü; burada hastalık ve sağlıklı vakaları ayırt etmek daha zordu. Modelin dikkat (attention) haritaları analizleri, V-JEPA’nın sadece merkezi kesitte değil, birden çok kesit arasında dağılmış ilgili yapılara odaklandığını gösterdi. Hata analizleri, tek kesit modellerin sık sık patolojinin orta kesitte yok veya ince olduğu ama hacmin başka yerlerinde var olduğu durumları kaçırdığını ortaya koydu. Mekânsal kapsama alanını etkili şekilde artırıp kesitlerin birbirleriyle ilişkisini öğrenerek 3B model bu örüntüleri daha iyi yakalayabildi.
Performans ile uygulanabilirlik arasında denge
Yazarlar ayrıca V-JEPA’yı, sıfırdan eğitilen klasik üç boyutlu konvolüsyonel ağlar ve birçok kesiti tek tek bir görüntü modeliyle işleyip sonuçları birleştiren "2.5D" yöntemi gibi diğer 3B bilgi kullanma yollarıyla karşılaştırdı. V-JEPA genellikle bu alternatiflerden daha iyi performans gösterirken 2.5D stratejisinden daha az hesaplama gerektirdi. Önemli olarak, faydaları sadece sınırlı miktarda etiketli veri olduğunda bile devam etti ve eğitim verisi arttıkça performansı iyileşmeye devam etti; oysa görüntü tabanlı modeller genellikle doygunluğa ulaştı. Hacimleri analiz etmek tek bir kesiti okumaktan daha yavaş olsa da, ek işlem süresi modern donanımda tarama başına yüzde birkaç ondalık saniye mertebesinde kaldı.
Geleceğin göz bakımında bunun anlamı
Uzman olmayanlar için çıkarım açık: AI’ya retinayı klinisyenlerin gördüğü gibi 3B olarak göstermek, yaygın körlüğe yol açan hastalıkların daha doğru otomatik tespitine yol açar. Bu çalışma, gelecekteki göz görüntüleme “temel modellerinin” baştan itibaren yalnızca tek tek anlık görüntülerle değil, tam OCT hacimlerini işleyebilecek şekilde tasarlanması gerektiğini öne sürüyor. Daha geniş veri paylaşımıyla ve nihayetinde diğer klinik bilgilerle entegrasyonla birleştiğinde, bu tür modeller glokom ve makula dejenerasyonu için tutarlı, yüksek kaliteli taramaları dünya çapında çok daha fazla klinik ve hastaya ulaştırmaya yardımcı olabilir.
Atıf: Judkiewicz, R., Berkowitz, E., Meisel, M. et al. Shifting the retinal foundation models paradigm from slices to volumes for optical coherence tomography. npj Digit. Med. 9, 314 (2026). https://doi.org/10.1038/s41746-026-02496-7
Anahtar kelimeler: optik koherens tomografi, retina görüntüleme AI, yaşa bağlı makula dejenerasyonu, glokom tespiti, video temel modeller