Clear Sky Science · zh
一种用于败血症数据表示的多模态嵌入模型
这对重症感染患者为何重要
败血症是对感染的快速且常致命的反应,医生必须基于杂乱且不完整的医院数据做出生死攸关的决定。本研究提出了一种新方法,将医院关于败血症患者的所有信息——来自化验的数值和医生与影像报告的自由文本——转化为单一且丰富的数字画像。此画像可以重复使用,用于将患者按生物学上有意义的群体分类,并在仅有少量带标签样本的情况下预测谁最有生命危险。
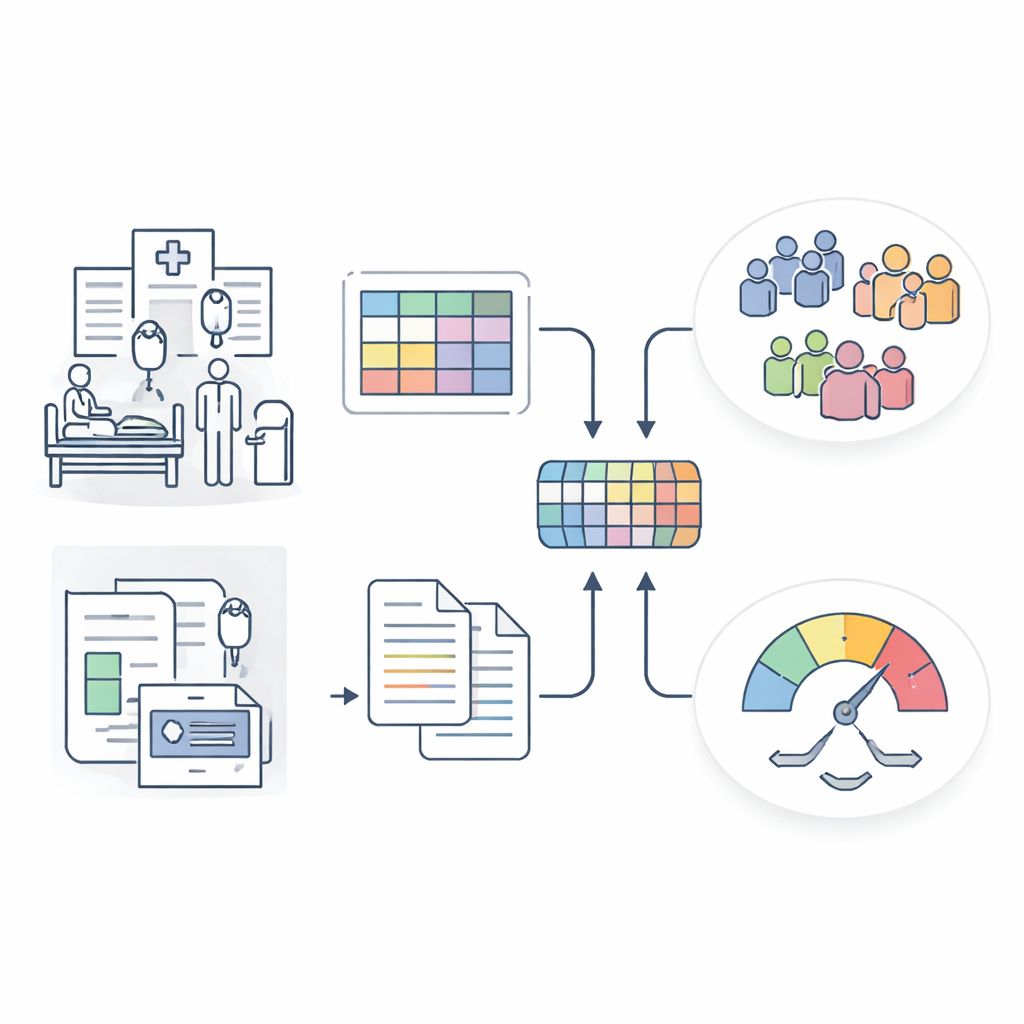
从混合医院数据构建更智能的败血症画像
研究者构建了败血症数据表示模型(SepsisDRM),使用了广东省中医院及其分支机构收治的19,526例败血症患者的病历。每位患者贡献了两类信息。第一类是结构化条目,如年龄、既往疾病、器官功能评分以及31项常规实验室检测(包括炎症标志、凝血、肝肾功能和血脂等)。第二类是非结构化文本来源,包括微生物培养结果和放射科医生的CT扫描报告。SepsisDRM并非将这些数据流分开处理,而是用为数值设计的神经网络处理表格数据,用现代语言模型处理文本,然后将两者融合为每位患者的共享表示。
无需标签学习以发现潜在的患者类型
为避免大量专家标注的需求,SepsisDRM采用了一种称为对比学习的方法。模型生成同一患者记录的略有不同“视图”,并学习在其内部空间中将这些视图拉近,同时将来自其他患者的记录推远。训练完成后,每位患者在该空间中被表示为一个点。研究团队随后进行聚类,发现四类群体最能捕捉数据结构:高炎症组、低炎症组、中间组和多器官衰竭组。这些聚类在化验结果、慢性病负担和院内死亡率上明显不同,其中多器官衰竭组预后最差,低炎症组预后最好。
将数字分群与真实治疗反应联系起来
作者不仅做描述性分析,还探讨这些数据驱动的分群是否能指导治疗。他们考察了血必净注射液(一种在中国广泛用作败血症辅助治疗的中药制剂)的使用情况。在按年龄、器官衰竭和共病情况对接受治疗和未接受治疗的患者进行精确匹配后,他们比较了各表型内的死亡率。在总体败血症人群以及四个组中的三个组里,血必净并未显示明确获益。但在高炎症组中,接受该药的患者院内死亡率显著低于未接受但条件相似的患者,这表明该疗法可能对某一特定生物学亚型更有益,而非对所有败血症患者都适用。
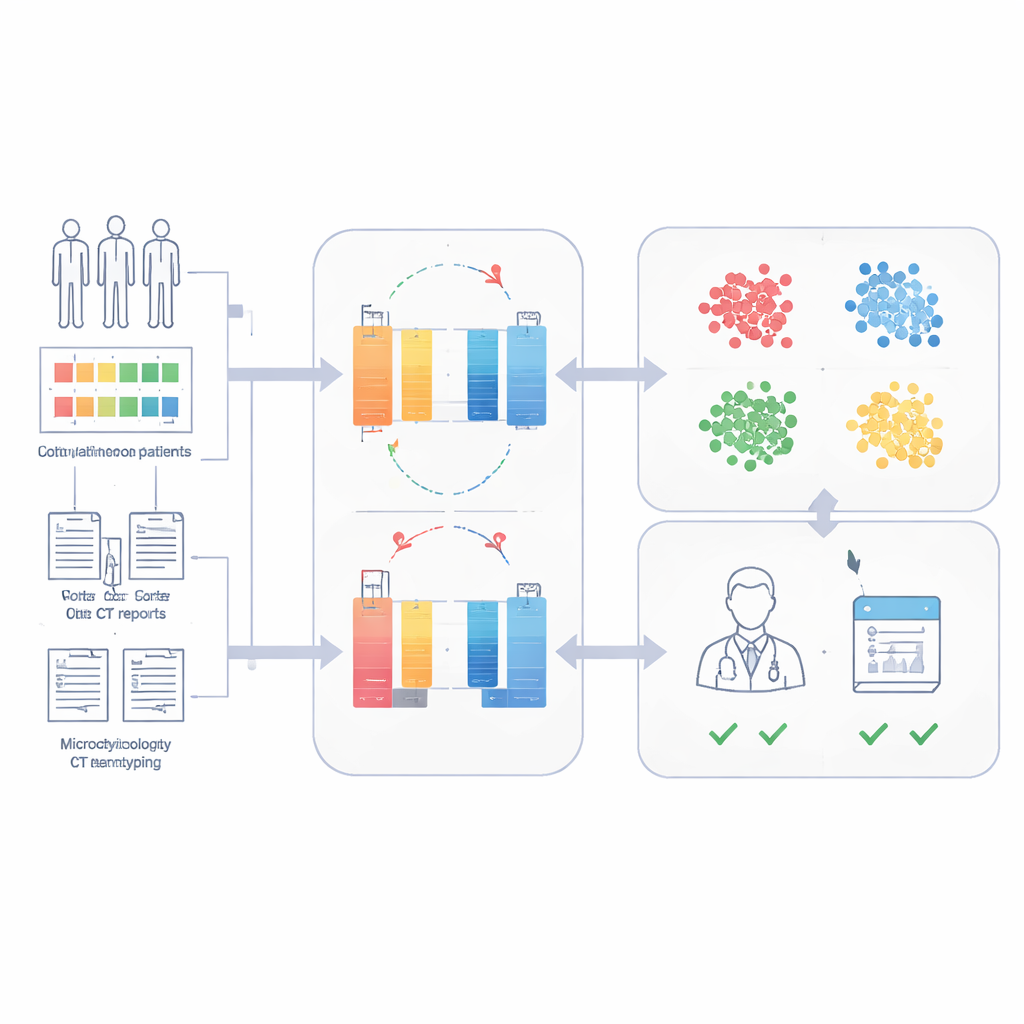
用少量带标签病例预测28天生存
由于SepsisDRM已对每位患者编码为详细的画像,团队可以在这些画像上训练一个简单分类器来预测患者入院后28天是否存活。仅用少量带标签的数据集,模型就达到了较高准确度:在同一医院的回顾性和前瞻性测试集上,ROC曲线下面积分别为0.83和0.82;在一家有不同规范和记录风格的外部医院上为0.69。在一项前瞻性队列的直接比较中,SepsisDRM比11位不同资历的临床医生更敏感且更稳定,漏诊后来死亡患者更少,同时仍保持较高的“安全”正确分类率。
这对败血症护理的未来意味着什么
简单来说,这项工作表明:由化验数值和自由文本共同构建的单一可重用数字表示,既能揭示疾病的有意义亚型,又能驱动准确的结局预测工具。SepsisDRM并非取代临床医生,但可作为决策辅助手段:标记高危患者、提示可能从特定治疗(如血必净)中受益的人群,即便在带标签数据有限的环境中也能发挥作用。同样的策略可被推广到其他医院同时收集结构化测量和叙事报告的疾病,为更精确和数据驱动的重症护理开辟道路。
引用: Liu, T., Li, Y., Chen, H. et al. A multimodal embedding model for sepsis data representation. npj Digit. Med. 9, 272 (2026). https://doi.org/10.1038/s41746-026-02446-3
关键词: 败血症表型, 多模态嵌入, 临床预测, 重症护理人工智能, 治疗分层