Clear Sky Science · pt
Um modelo de incorporação multimodal para representação de dados de sepse
Por que isso importa para pacientes com infecções graves
Sepse é uma reação rápida e frequentemente letal à infecção, e os médicos precisam tomar decisões de vida ou morte com base em dados hospitalares confusos e incompletos. Este estudo apresenta uma nova forma de transformar tudo o que o hospital sabe sobre um paciente com sepse — números de exames laboratoriais e relatórios em texto livre de médicos e imagens — em um único retrato digital rico. Esse retrato pode então ser reutilizado para agrupar pacientes em categorias biologicamente significativas e para prever quem está em maior risco de morrer, mesmo quando há apenas um pequeno conjunto de treino com casos rotulados.
Uma visão mais inteligente da sepse a partir de dados hospitalares mistos
Os pesquisadores construíram o Sepsis Data Representation Model, ou SepsisDRM, usando registros de 19.526 pacientes com sepse tratados no Guangdong Provincial Hospital of Chinese Medicine e suas filiais. Cada paciente contribuiu com dois tipos de informação. Primeiro, entradas estruturadas, como idade, doenças pré‑existentes, escores de falência orgânica e 31 medidas laboratoriais de rotina, como marcadores de inflamação, coagulação sanguínea, função hepática e renal e lipídios sanguíneos. Segundo, fontes de texto não estruturado, incluindo resultados de culturas microbiológicas e laudos de tomografia computadorizada de radiologistas. Em vez de tratar essas correntes separadamente, o SepsisDRM processa as tabelas com uma rede neural projetada para números e o texto com um modelo de linguagem moderno, então funde ambos em uma representação compartilhada para cada paciente.
Aprender sem rótulos para descobrir tipos ocultos de pacientes
Para evitar a necessidade de grandes quantidades de rotulagem especializada, o SepsisDRM utiliza uma abordagem chamada aprendizado contrastivo. O modelo gera «visões» ligeiramente diferentes do mesmo registro do paciente e aprende a aproximar essas visões no seu espaço interno, enquanto afasta registros de outros pacientes. Uma vez treinado, cada paciente é representado como um único ponto nesse espaço. A equipe então aplicou agrupamento e descobriu que quatro grupos capturavam melhor a estrutura dos dados: um grupo de alta inflamação, um de baixa inflamação, um grupo intermediário e um grupo com falência múltipla de órgãos. Esses aglomerados diferiram claramente em resultados laboratoriais, carga de doenças crônicas e taxas de óbito intra‑hospitalar, com o grupo de falência múltipla de órgãos apresentando os piores desfechos e o grupo de baixa inflamação os melhores.
Vinculando grupos digitais a respostas reais a tratamentos
Os autores foram além da descrição e perguntaram se esses grupos orientados por dados poderiam guiar a terapia. Eles examinaram o uso de Xuebijing, uma injeção à base de medicina tradicional chinesa amplamente usada como tratamento adjuvante para sepse na China. Depois de emparelhar cuidadosamente pacientes tratados e não tratados por idade, falência orgânica e comorbidades, compararam as taxas de óbito dentro de cada fenótipo. Na população geral de sepse e em três dos quatro grupos, o Xuebijing não mostrou benefício claro. Mas no grupo de alta inflamação, pacientes que receberam o medicamento tiveram probabilidade significativamente menor de morrer no hospital do que pacientes semelhantes que não o receberam, sugerindo que essa terapia pode ser mais útil para um subtipo biológico específico do que para todos com sepse.
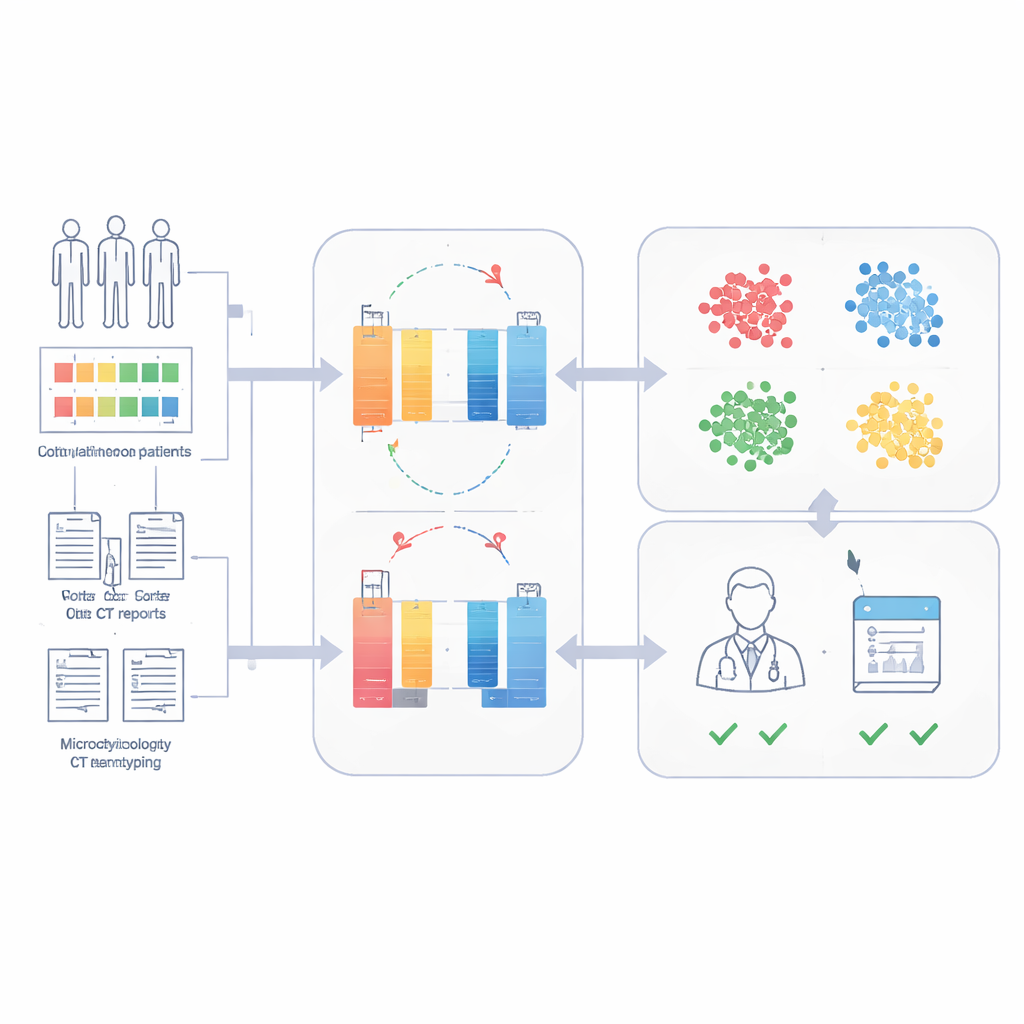
Prevendo sobrevivência em 28 dias com poucos casos rotulados
Como o SepsisDRM já codifica um retrato detalhado de cada paciente, a equipe pôde treinar um classificador simples sobre essas representações para prever se alguém estaria vivo 28 dias após a admissão. Usando apenas pequenos conjuntos de dados rotulados, o modelo alcançou alta precisão: áreas sob a curva ROC de 0,83 e 0,82 em conjuntos de teste retrospectivo e prospectivo do mesmo hospital, e 0,69 em um hospital externo com práticas e estilos de documentação diferentes. Em comparação direta em uma coorte prospectiva, o SepsisDRM foi mais sensível e mais consistente do que 11 médicos humanos de diferentes níveis de senioridade, deixando de identificar menos pacientes que posteriormente morreram, mantendo ao mesmo tempo uma alta taxa de classificações "seguros" corretas.
O que isso significa para o futuro do cuidado da sepse
Em termos simples, este trabalho mostra que uma representação digital única e reutilizável de pacientes com sepse — construída conjuntamente a partir de números laboratoriais e notas em texto livre — pode tanto revelar subtipos significativos da doença quanto alimentar ferramentas precisas de predição de desfechos. O SepsisDRM não substitui os clínicos, mas pode atuar como auxílio à decisão: sinalizando pacientes de alto risco, destacando quem pode se beneficiar de tratamentos específicos como o Xuebijing, e fazendo isso mesmo em ambientes com poucos dados rotulados. A mesma estratégia poderia ser adaptada a outras condições em que os hospitais coletam uma mistura de medições estruturadas e relatórios narrativos, abrindo um caminho para cuidados críticos mais precisos e orientados por dados.
Citação: Liu, T., Li, Y., Chen, H. et al. A multimodal embedding model for sepsis data representation. npj Digit. Med. 9, 272 (2026). https://doi.org/10.1038/s41746-026-02446-3
Palavras-chave: fenótipos de sepse, incorporações multimodais, previsão clínica, IA em cuidados críticos, estratificação de tratamento