Clear Sky Science · es
Un modelo de incrustación multimodal para la representación de datos de sepsis
Por qué esto importa para pacientes con infecciones graves
La sepsis es una reacción rápida y a menudo mortal a una infección, y los médicos deben tomar decisiones de vida o muerte basadas en datos hospitalarios desordenados e incompletos. Este estudio presenta una nueva forma de convertir todo lo que el hospital sabe sobre un paciente con sepsis —valores de pruebas de laboratorio y textos libres de los médicos y de los escáneres— en un único retrato digital rico. Ese retrato puede reutilizarse para clasificar a los pacientes en grupos biológicamente significativos y para predecir quién tiene mayor riesgo de morir, incluso cuando solo hay disponible un pequeño conjunto de casos etiquetados para entrenamiento.
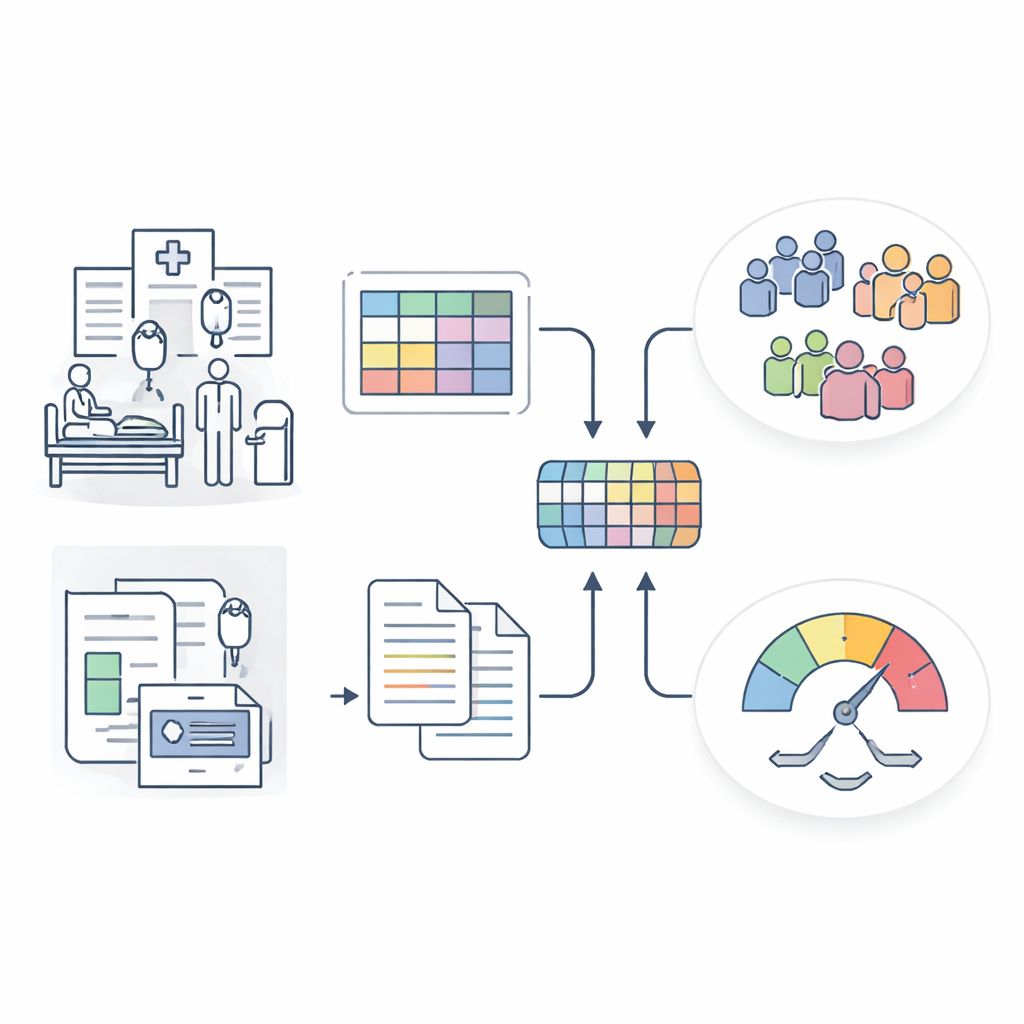
Una imagen más inteligente de la sepsis a partir de datos hospitalarios mixtos
Los investigadores construyeron el Modelo de Representación de Datos de Sepsis, o SepsisDRM, empleando registros de 19.526 pacientes con sepsis tratados en el Hospital Provincial de Guangdong de Medicina China y sus sucursales. Cada paciente aportó dos tipos de información. Primero, entradas estructuradas, como edad, enfermedades previas, puntuaciones de fallo orgánico y 31 mediciones rutinarias de laboratorio como marcadores de inflamación, coagulación sanguínea, función hepática y renal, y lípidos sanguíneos. Segundo, fuentes de texto no estructurado, incluidos resultados de cultivos microbiológicos e informes de TC de radiólogos. En lugar de tratar estas corrientes por separado, SepsisDRM procesa las tablas con una red neuronal diseñada para datos numéricos y el texto con un modelo de lenguaje moderno, para luego fusionar ambos en una representación compartida por cada paciente.
Aprender sin etiquetas para descubrir tipos ocultos de pacientes
Para evitar la necesidad de grandes cantidades de etiquetado experto, SepsisDRM emplea un enfoque llamado aprendizaje contrastivo. El modelo genera vistas ligeramente diferentes del mismo registro de paciente y aprende a acercar esas vistas en su espacio interno, mientras aleja los registros de otros pacientes. Una vez entrenado, cada paciente queda representado como un único punto en ese espacio. El equipo aplicó luego clustering y encontró que cuatro grupos capturaban mejor la estructura de los datos: un grupo de alta inflamación, un grupo de baja inflamación, un grupo intermedio y un grupo con fallo multiorgánico. Estos clústeres diferían claramente en resultados de laboratorio, carga de enfermedad crónica y tasas de muerte hospitalaria, siendo el grupo de fallo multiorgánico el que presentó peores resultados y el de baja inflamación el que presentó mejores.
Vincular grupos digitales con respuestas reales al tratamiento
Los autores fueron más allá de la descripción y se preguntaron si estos grupos basados en datos podían orientar la terapia. Examinaron el uso de Xuebijing, una inyección basada en medicina tradicional china ampliamente utilizada como tratamiento complementario para la sepsis en China. Tras emparejar cuidadosamente pacientes tratados y no tratados por edad, fallo orgánico y enfermedades coexistentes, compararon las tasas de muerte dentro de cada fenotipo. En la población general con sepsis y en tres de los cuatro grupos, Xuebijing no mostró un beneficio claro. Pero en el grupo de alta inflamación, los pacientes que recibieron el fármaco tuvieron una probabilidad significativamente menor de morir en el hospital que pacientes similares que no lo recibieron, lo que sugiere que esta terapia puede ser más útil para un subtipo biológico específico en lugar de para todos los pacientes con sepsis.
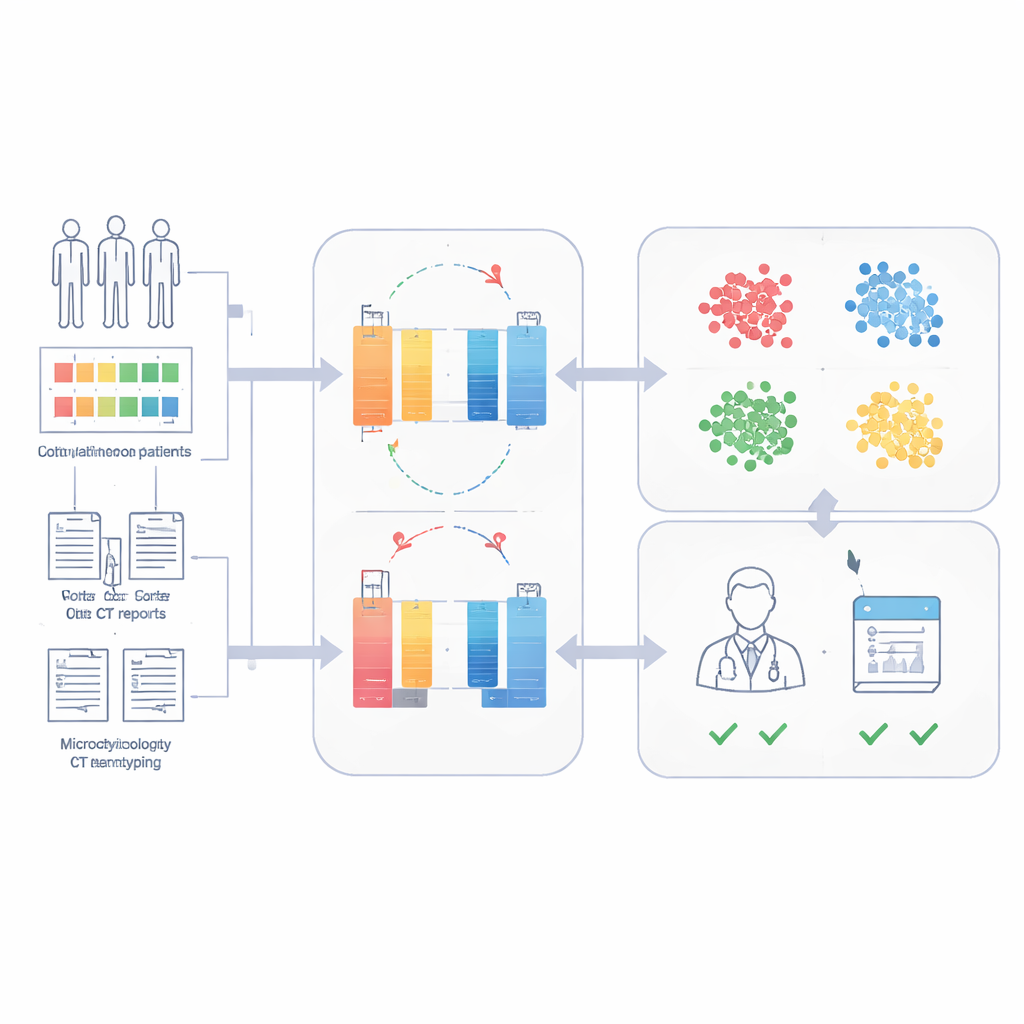
Predecir la supervivencia a 28 días con pocos casos etiquetados
Puesto que SepsisDRM ya codifica un retrato detallado de cada paciente, el equipo pudo entrenar un clasificador simple sobre esas representaciones para predecir si alguien estaría vivo 28 días después del ingreso. Usando solo pequeños conjuntos de datos etiquetados, el modelo alcanzó alta precisión: áreas bajo la curva ROC de 0,83 y 0,82 en conjuntos de prueba retrospectivos y prospectivos del mismo hospital, y 0,69 en un hospital externo con prácticas y estilos de documentación diferentes. En una comparación directa sobre una cohorte prospectiva, SepsisDRM fue más sensible y más consistente que 11 médicos humanos de distinta experiencia, pasando por alto a menos pacientes que luego murieron, manteniendo al mismo tiempo una alta tasa de clasificaciones "seguras" correctas.
Qué significa esto para el futuro del cuidado de la sepsis
Dicho de forma simple, este trabajo demuestra que una representación digital única y reutilizable de pacientes con sepsis —construida conjuntamente a partir de cifras de laboratorio y notas de texto libre— puede tanto revelar subtipos significativos de la enfermedad como alimentar herramientas precisas de predicción de resultados. SepsisDRM no sustituye a los clínicos, pero puede actuar como ayuda para la toma de decisiones: señalar pacientes de alto riesgo, resaltar quién podría beneficiarse de tratamientos concretos como Xuebijing y hacerlo incluso en entornos con datos etiquetados limitados. La misma estrategia podría adaptarse a otras condiciones en las que los hospitales recopilan una mezcla de mediciones estructuradas e informes narrativos, abriendo un camino hacia una atención crítica más precisa y basada en datos.
Cita: Liu, T., Li, Y., Chen, H. et al. A multimodal embedding model for sepsis data representation. npj Digit. Med. 9, 272 (2026). https://doi.org/10.1038/s41746-026-02446-3
Palabras clave: fenotipos de sepsis, incrustaciones multimodales, predicción clínica, IA en cuidados críticos, estratificación del tratamiento