Clear Sky Science · de
Ein multimodales Einbettungsmodell zur Darstellung von Sepsisdaten
Warum das für Patientinnen und Patienten mit schweren Infektionen wichtig ist
Sepsis ist eine schnell verlaufende und oft tödliche Reaktion auf eine Infektion, und Ärztinnen und Ärzte müssen lebenswichtige Entscheidungen auf Basis unvollständiger, unordentlicher Krankenhausdaten treffen. Diese Studie stellt eine neue Methode vor, um alles, was das Krankenhaus über einen Sepsispatienten weiß — Zahlen aus Laboruntersuchungen und freie Textberichte von Ärzten und bildgebenden Verfahren — in ein einziges, reichhaltiges digitales Porträt zu überführen. Dieses Porträt lässt sich dann wiederverwenden, um Patientinnen und Patienten in biologisch sinnvolle Gruppen zu ordnen und um vorherzusagen, wer am ehesten zu sterben droht, selbst wenn nur ein kleiner Trainingssatz mit gelabelten Fällen verfügbar ist.
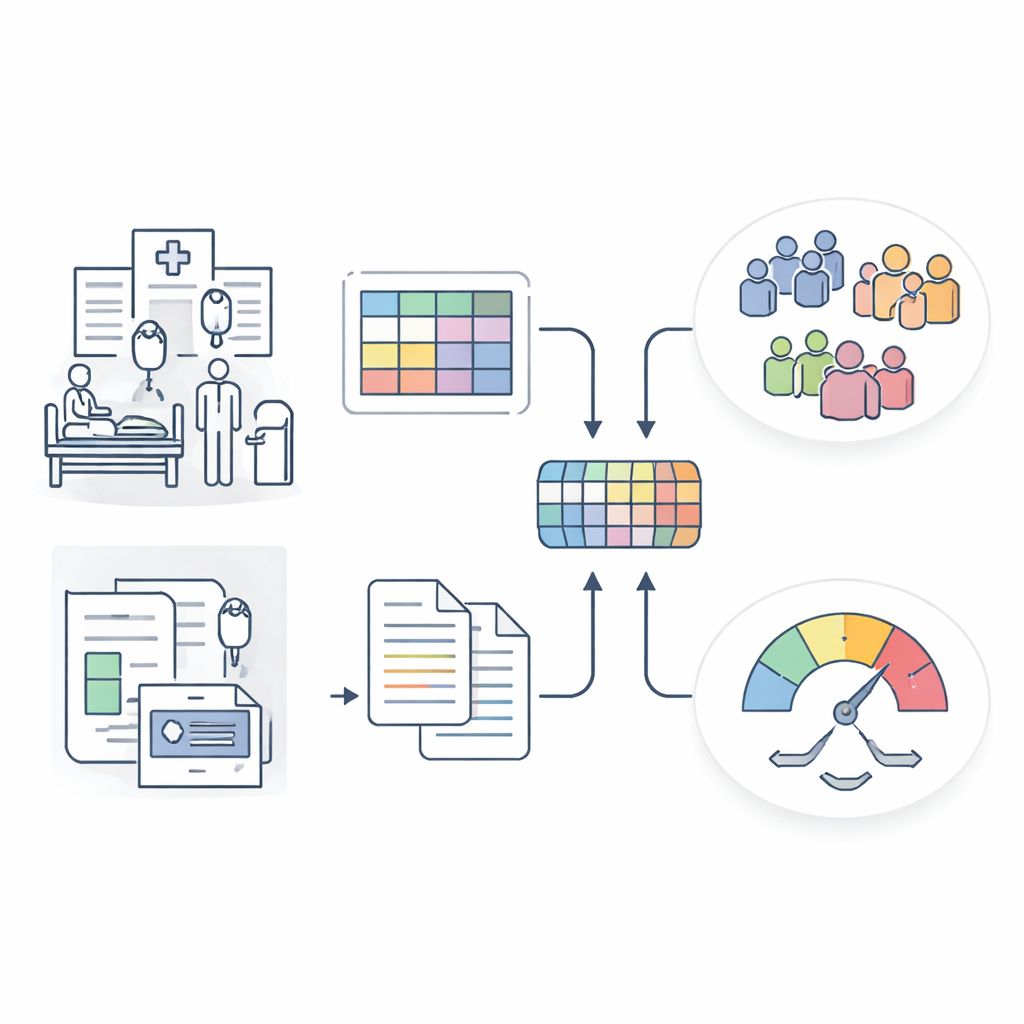
Ein schärferes Bild der Sepsis aus gemischten Krankenhausdaten
Die Forschenden entwickelten das Sepsis Data Representation Model, kurz SepsisDRM, anhand von Daten von 19.526 Sepsispatienten, die im Guangdong Provincial Hospital of Chinese Medicine und dessen Zweigstellen behandelt wurden. Jeder Patient lieferte zwei Arten von Informationen. Erstens strukturierte Einträge wie Alter, Vorerkrankungen, Organversagenscores und 31 routinemäßige Laborwerte wie Entzündungsmarker, Gerinnungsparameter, Leber- und Nierenfunktion sowie Blutfette. Zweitens unstrukturierte Textquellen, darunter mikrobiologische Kulturbefunde und radiologische CT‑Befunde. Anstatt diese Datenströme getrennt zu behandeln, verarbeitet SepsisDRM die Tabellendaten mit einem für Zahlen ausgelegten neuronalen Netzwerk und den Text mit einem modernen Sprachmodell und führt beides dann zu einer gemeinsamen Repräsentation für jede Patientin bzw. jeden Patienten zusammen.
Lernen ohne Labels, um verborgene Patiententypen aufzudecken
Um den Bedarf an umfangreicher Expertenkennzeichnung zu vermeiden, nutzt SepsisDRM einen Ansatz namens contrastive learning. Das Modell erzeugt leicht unterschiedliche "Ansichten" desselben Patientenrecords und lernt, diese Ansichten in seinem internen Raum näher zusammenzubringen, während es Datensätze anderer Patienten auseinanderdrückt. Nach dem Training wird jede Patientin bzw. jeder Patient als ein einzelner Punkt in diesem Raum dargestellt. Das Team wendete dann Clustering an und fand heraus, dass vier Gruppen die Struktur der Daten am besten abbilden: eine Hochentzündungs-Gruppe, eine Niedrigentzündungs-Gruppe, eine Zwischenstufe und eine Mehrorganversagens-Gruppe. Diese Cluster unterschieden sich deutlich in den Laborwerten, der Last chronischer Erkrankungen und den Sterberaten im Krankenhaus, wobei die Gruppe mit Mehrorganversagen am schlechtesten und die Niedrigentzündungs‑Gruppe am besten abschnitt.
Verknüpfung digitaler Gruppen mit realen Therapieantworten
Die Autorinnen und Autoren gingen über die reine Beschreibung hinaus und prüften, ob diese datengetriebenen Gruppen Therapien leiten könnten. Sie untersuchten den Einsatz von Xuebijing, einer auf traditioneller chinesischer Medizin basierenden Injektion, die in China häufig als Zusatztherapie bei Sepsis verwendet wird. Nach sorgfältigem Abgleich von behandelten und unbehandelten Patienten hinsichtlich Alter, Organversagen und Begleiterkrankungen verglichen sie die Sterberaten innerhalb jedes Phänotyps. In der gesamten Sepsispopulation und in drei der vier Gruppen zeigte Xuebijing keinen klaren Nutzen. In der Hochentzündungs‑Gruppe jedoch hatten Patienten, die das Medikament erhielten, eine signifikant geringere Wahrscheinlichkeit, im Krankenhaus zu sterben, als ähnliche nicht behandelte Patienten. Das deutet darauf hin, dass diese Therapie für einen bestimmten biologischen Subtyp am hilfreichsten sein könnte und nicht zwangsläufig für alle Sepsispatienten.
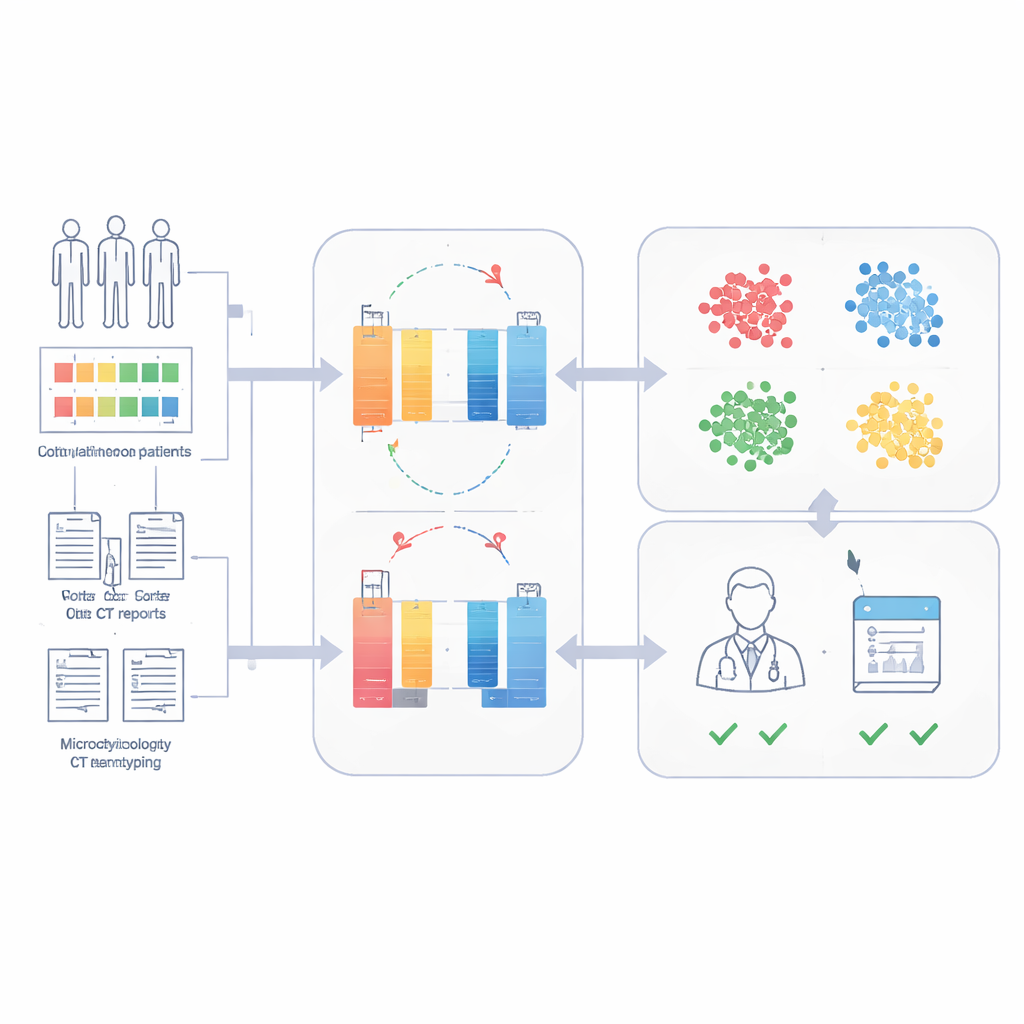
Vorhersage des 28‑Tage‑Überlebens mit wenigen gelabelten Fällen
Da SepsisDRM bereits ein detailliertes Porträt jeder Patientin bzw. jedes Patienten kodiert, konnte das Team einen einfachen Klassifikator auf Basis dieser Porträts trainieren, um vorherzusagen, ob jemand 28 Tage nach der Aufnahme noch leben würde. Mit nur kleinen gelabelten Datensätzen erreichte das Modell hohe Genauigkeit: Flächen unter der ROC‑Kurve von 0,83 bzw. 0,82 in retrospektiven und prospektiven Testsets desselben Krankenhauses und 0,69 in einem externen Krankenhaus mit anderen Praxis‑ und Dokumentationsstilen. In einem direkten Vergleich in einer prospektiven Kohorte war SepsisDRM sensitiver und konsistenter als 11 behandelnde Ärztinnen und Ärzte mit unterschiedlicher Erfahrung: Es übersah weniger Patienten, die später starben, und behielt gleichzeitig eine hohe Rate an korrekten "sicheren" Einschätzungen bei.
Was das für die Zukunft der Sepsisversorgung bedeutet
Einfach gesagt zeigt diese Arbeit, dass eine einzelne, wiederverwendbare digitale Repräsentation von Sepsispatienten — gemeinsam erstellt aus Laborwerten und freien Textnotizen — sowohl bedeutsame Subtypen der Erkrankung aufdecken als auch genaue Outcome‑Vorhersageinstrumente antreiben kann. SepsisDRM ersetzt keine Klinikerinnen und Kliniker, kann aber als Entscheidungsunterstützung dienen: es markiert Hochrisikopatienten, hebt hervor, wer möglicherweise von bestimmten Behandlungen wie Xuebijing profitiert, und tut dies selbst in Umgebungen mit begrenzten gelabelten Daten. Die gleiche Strategie ließe sich auf andere Krankheitsbilder übertragen, bei denen Krankenhäuser eine Mischung aus strukturierten Messungen und narrativen Berichten erfassen, und eröffnet einen Weg zu präziserer und datengetriebener Intensivmedizin.
Zitation: Liu, T., Li, Y., Chen, H. et al. A multimodal embedding model for sepsis data representation. npj Digit. Med. 9, 272 (2026). https://doi.org/10.1038/s41746-026-02446-3
Schlüsselwörter: Sepsis-Phänotypen, multimodale Einbettungen, klinische Vorhersage, KI in der Intensivmedizin, Therapiestratifizierung