Clear Sky Science · it
Un modello di embedding multimodale per la rappresentazione dei dati sulla sepsi
Perché questo è importante per i pazienti con infezioni gravi
La sepsi è una reazione all’infezione che progredisce rapidamente e può essere fatale, e i medici devono prendere decisioni cruciali sulla base di dati ospedalieri disordinati e spesso incompleti. Questo studio presenta un nuovo metodo per trasformare tutto ciò che l’ospedale sa su un paziente con sepsi — numeri provenienti da test di laboratorio e referti in testo libero di medici e apparecchiature — in un unico ritratto digitale ricco. Quel ritratto può poi essere riutilizzato per raggruppare i pazienti in classi biologicamente significative e per prevedere chi è più a rischio di morte, anche quando è disponibile solo un piccolo insieme di casi etichettati per l’addestramento.
Un quadro più intelligente della sepsi dai dati ospedalieri misti
I ricercatori hanno costruito il Sepsis Data Representation Model, o SepsisDRM, utilizzando i record di 19.526 pazienti con sepsi trattati al Guangdong Provincial Hospital of Chinese Medicine e nelle sue sedi affiliate. Ogni paziente ha fornito due tipi di informazioni. Il primo sono voci strutturate, come età, malattie preesistenti, punteggi di insufficienza d’organo e 31 misurazioni di laboratorio di routine come marcatori di infiammazione, coagulazione del sangue, funzione epatica e renale e lipidi ematici. Il secondo sono fonti testuali non strutturate, inclusi risultati di colture microbiologiche e referti TC dei radiologi. Invece di trattare questi flussi separatamente, SepsisDRM elabora le tabelle con una rete neurale progettata per i numeri e il testo con un moderno modello di linguaggio, quindi fonde entrambi in una rappresentazione condivisa per ogni paziente.
Apprendere senza etichette per scoprire tipi di pazienti nascosti
Per evitare la necessità di grandi quantità di annotazioni esperte, SepsisDRM utilizza un approccio chiamato apprendimento contrastivo. Il modello genera «visioni» leggermente diverse dello stesso record paziente e impara ad avvicinare queste visioni nel suo spazio interno, mentre allontana i record di altri pazienti. Una volta addestrato, ogni paziente è rappresentato come un singolo punto in questo spazio. Il gruppo ha quindi applicato algoritmi di clustering e ha osservato che quattro gruppi catturavano al meglio la struttura dei dati: un gruppo ad alta infiammazione, un gruppo a bassa infiammazione, un gruppo intermedio e un gruppo con insufficienza multiorgano. Questi cluster differivano chiaramente nei risultati di laboratorio, nel carico di malattie croniche e nei tassi di mortalità ospedaliera, con il gruppo a insufficienza multiorgano con esiti peggiori e il gruppo a bassa infiammazione con esiti migliori.
Collegare i gruppi digitali alle risposte reali al trattamento
Gli autori sono andati oltre la descrizione per chiedersi se questi gruppi guidati dai dati potessero orientare la terapia. Hanno esaminato l’uso dello Xuebijing, un’infusione a base di medicina tradizionale cinese ampiamente impiegata come trattamento aggiuntivo per la sepsi in Cina. Dopo aver accuratamente abbinato pazienti trattati e non trattati per età, insufficienza d’organo e comorbilità, hanno confrontato i tassi di morte all’interno di ciascun fenotipo. Nella popolazione complessiva di pazienti con sepsi e in tre dei quattro gruppi, lo Xuebijing non ha mostrato un beneficio chiaro. Ma nel gruppo ad alta infiammazione, i pazienti che hanno ricevuto il farmaco avevano una probabilità significativamente inferiore di morire in ospedale rispetto a pazienti simili che non lo avevano ricevuto, suggerendo che questa terapia potrebbe essere utile soprattutto per un sottotipo biologico specifico piuttosto che per tutti i pazienti con sepsi.
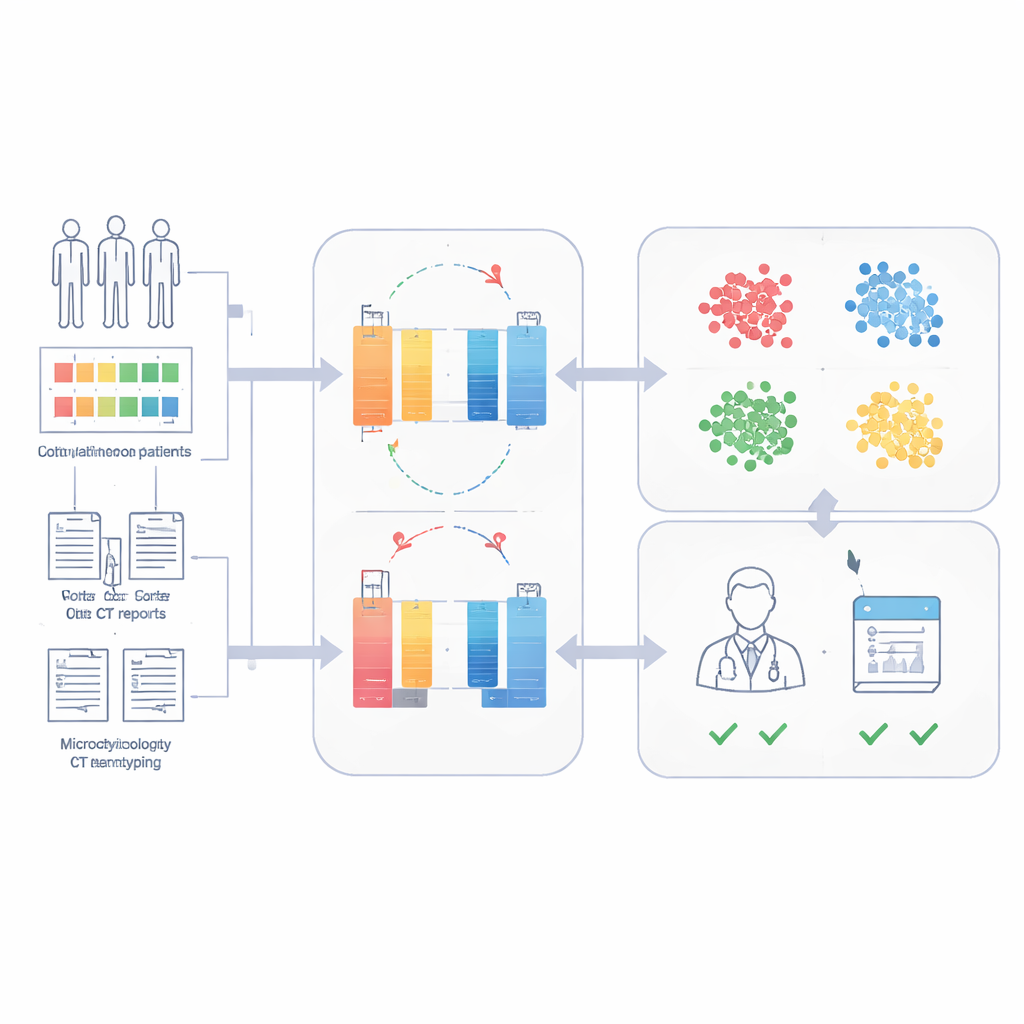
Prevedere la sopravvivenza a 28 giorni con pochi casi etichettati
Poiché SepsisDRM codifica già un ritratto dettagliato di ogni paziente, il team ha potuto addestrare un semplice classificatore sopra questi ritratti per prevedere se un paziente sarebbe stato vivo 28 giorni dopo il ricovero. Utilizzando solo piccoli set di dati etichettati, il modello ha raggiunto un’elevata accuratezza: aree sotto la curva ROC di 0,83 e 0,82 su set di test retrospettivi e prospettici dello stesso ospedale, e 0,69 su un ospedale esterno con pratiche e stili di documentazione diversi. In un confronto diretto su una coorte prospettica, SepsisDRM è stato più sensibile e più coerente rispetto a 11 medici umani di diversa anzianità, mancandone meno che poi sono deceduti pur mantenendo un elevato tasso di classificazioni «sicure» corrette.
Cosa significa per il futuro della cura della sepsi
In termini pratici, questo lavoro mostra che una singola rappresentazione digitale riutilizzabile dei pazienti con sepsi — costruita congiuntamente da numeri di laboratorio e note in testo libero — può sia rivelare sottotipi significativi della malattia sia alimentare strumenti di previsione degli esiti accurati. SepsisDRM non sostituisce i clinici, ma può agire come supporto decisionale: segnalando i pazienti ad alto rischio, evidenziando chi potrebbe beneficiare di trattamenti specifici come lo Xuebijing e facendo ciò anche in contesti con dati etichettati limitati. La stessa strategia potrebbe essere adattata ad altre condizioni in cui gli ospedali raccolgono una combinazione di misurazioni strutturate e referti narrativi, aprendo la strada a una terapia intensiva più precisa e guidata dai dati.
Citazione: Liu, T., Li, Y., Chen, H. et al. A multimodal embedding model for sepsis data representation. npj Digit. Med. 9, 272 (2026). https://doi.org/10.1038/s41746-026-02446-3
Parole chiave: fenotipi della sepsi, embedding multimodali, predizione clinica, IA per terapia intensiva, stratificazione del trattamento