Clear Sky Science · en
A multimodal embedding model for sepsis data representation
Why this matters for patients with severe infections
Sepsis is a fast-moving and often deadly reaction to infection, and doctors must make life-or-death decisions based on messy, incomplete hospital data. This study introduces a new way to turn everything the hospital knows about a sepsis patient—numbers from lab tests and free‑text reports from doctors and scanners—into a single, rich digital portrait. That portrait can then be reused to sort patients into biologically meaningful groups and to predict who is most at risk of dying, even when only a small training set of labeled cases is available.
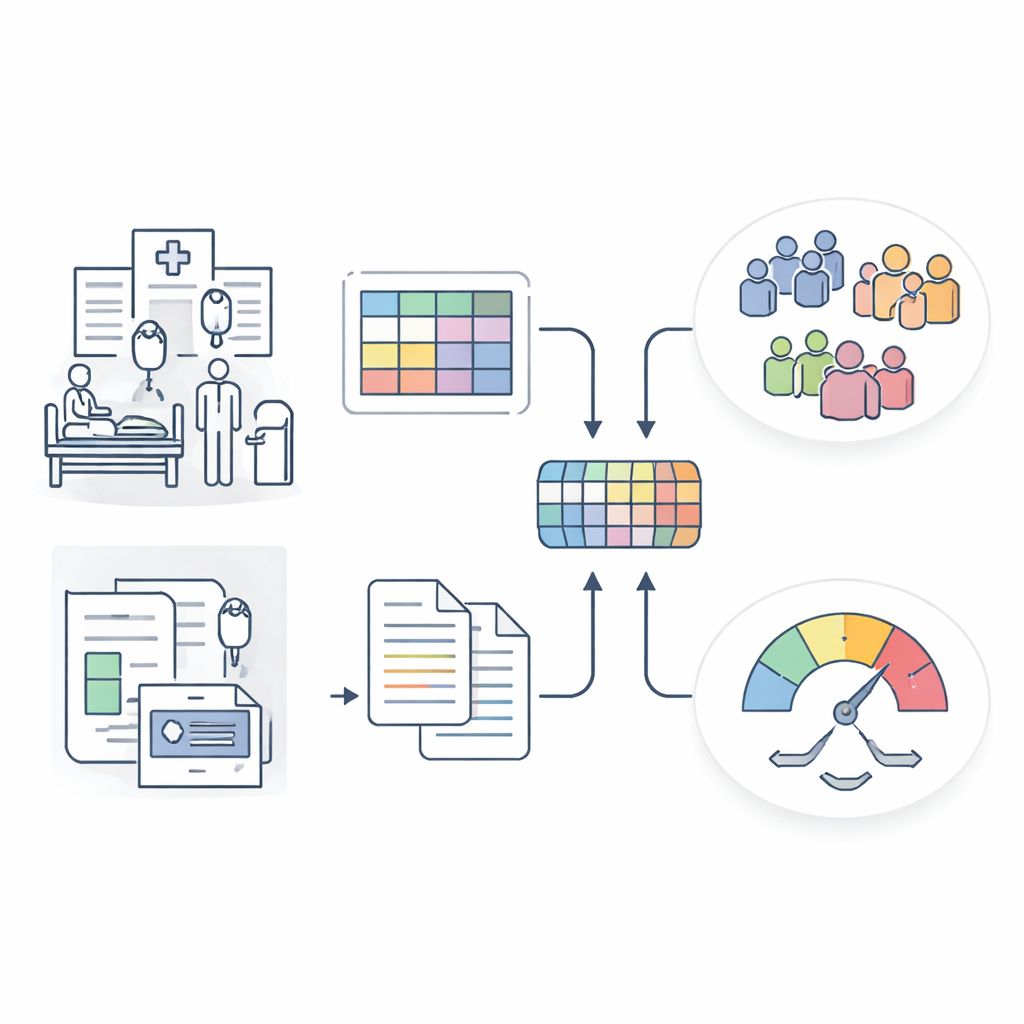
A smarter picture of sepsis from mixed hospital data
The researchers built the Sepsis Data Representation Model, or SepsisDRM, using records from 19,526 sepsis patients treated at Guangdong Provincial Hospital of Chinese Medicine and its branches. Each patient contributed two kinds of information. First were structured entries, such as age, pre‑existing illnesses, organ failure scores, and 31 routine laboratory measurements like markers of inflammation, blood clotting, liver and kidney function, and blood lipids. Second were unstructured text sources, including microbiology culture results and radiologists’ CT scan reports. Instead of treating these streams separately, SepsisDRM processes the tables with a neural network designed for numbers and the text with a modern language model, then fuses both into a shared representation for each patient.
Learning without labels to uncover hidden patient types
To avoid the need for large amounts of expert labeling, SepsisDRM uses an approach called contrastive learning. The model generates slightly different "views" of the same patient record and learns to pull those views closer together in its internal space, while pushing away records from other patients. Once trained, each patient is represented as a single point in this space. The team then applied clustering and found that four groups best captured the structure of the data: a high‑inflammation group, a low‑inflammation group, an intermediate group, and a multiple‑organ‑failure group. These clusters differed clearly in lab results, burden of chronic disease, and in‑hospital death rates, with the multiple‑organ‑failure group doing worst and the low‑inflammation group doing best.
Linking digital groups to real treatment responses
The authors went beyond description to ask whether these data‑driven groups could guide therapy. They examined use of Xuebijing, a traditional Chinese medicine–based injection widely used as an add‑on treatment for sepsis in China. After carefully matching treated and untreated patients on age, organ failure, and co‑existing illnesses, they compared death rates within each phenotype. In the overall sepsis population and in three of the four groups, Xuebijing did not show a clear benefit. But in the high‑inflammation group, patients who received the drug were significantly less likely to die in the hospital than similar patients who did not, suggesting that this therapy may be most helpful for a specific biological subtype rather than for everyone with sepsis.
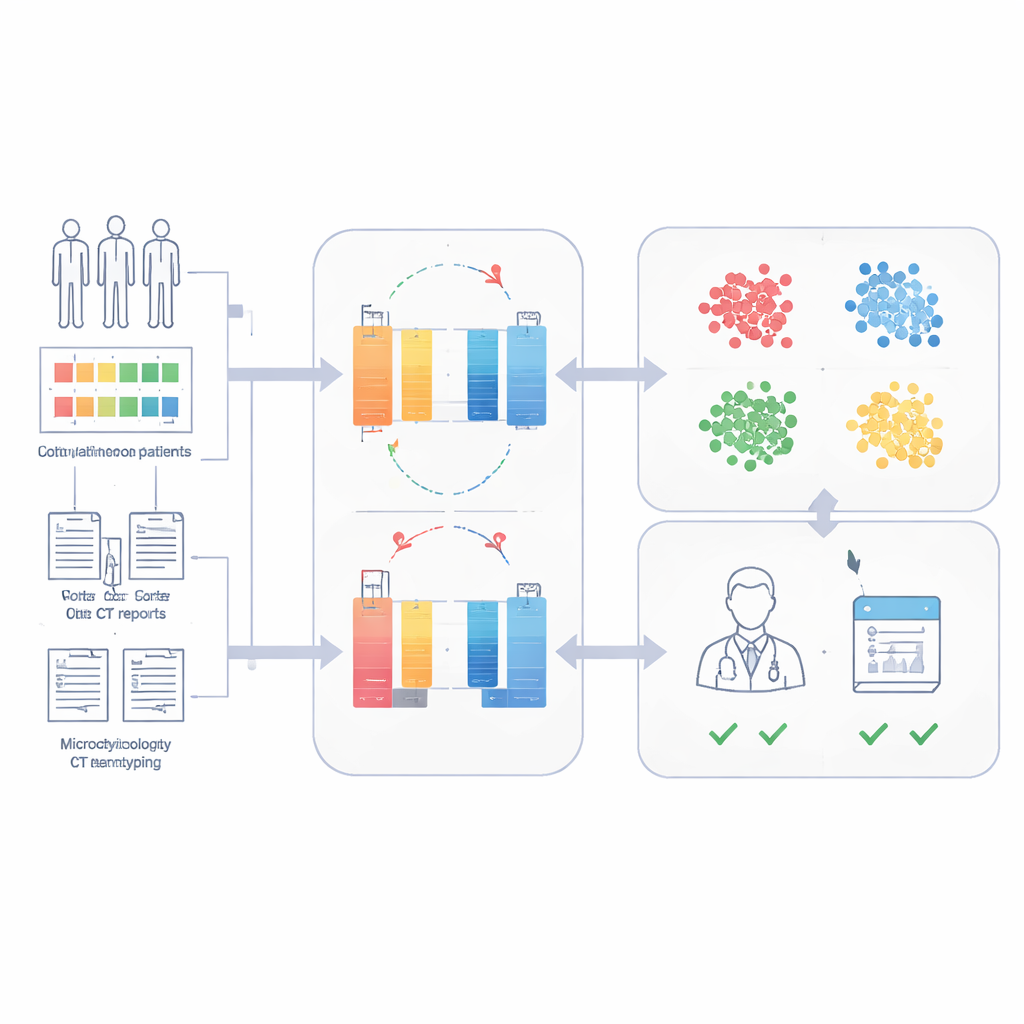
Predicting 28‑day survival with few labeled cases
Because SepsisDRM already encodes a detailed portrait of each patient, the team could train a simple classifier on top of these portraits to predict whether someone would be alive 28 days after admission. Using only small labeled datasets, the model reached high accuracy: areas under the ROC curve of 0.83 and 0.82 on retrospective and prospective test sets from the same hospital, and 0.69 on an external hospital with different practices and documentation styles. In head‑to‑head comparison on a prospective cohort, SepsisDRM was more sensitive and more consistent than 11 human physicians of varying seniority, missing fewer patients who went on to die while still maintaining a high rate of correct "safe" classifications.
What this means for the future of sepsis care
In plain terms, this work shows that a single, reusable digital representation of sepsis patients—built jointly from lab numbers and free‑text notes—can both reveal meaningful subtypes of the disease and power accurate outcome prediction tools. SepsisDRM does not replace clinicians, but it can act as a decision aid: flagging high‑risk patients, highlighting who might benefit from specific treatments such as Xuebijing, and doing so even in settings with limited labeled data. The same strategy could be adapted to other conditions where hospitals collect a mix of structured measurements and narrative reports, opening a path toward more precise and data‑driven critical care.
Citation: Liu, T., Li, Y., Chen, H. et al. A multimodal embedding model for sepsis data representation. npj Digit. Med. 9, 272 (2026). https://doi.org/10.1038/s41746-026-02446-3
Keywords: sepsis phenotypes, multimodal embeddings, clinical prediction, critical care AI, treatment stratification