Clear Sky Science · fr
Un modèle d'encodage multimodal pour la représentation des données de sepsie
Pourquoi c'est important pour les patients atteints d'infections sévères
La sepsie est une réaction rapide et souvent mortelle à une infection, et les médecins doivent prendre des décisions vitales à partir de données hospitalières désordonnées et incomplètes. Cette étude présente une nouvelle manière de transformer tout ce que l'hôpital sait d'un patient atteint de sepsie — des chiffres issus des analyses de laboratoire aux comptes rendus en texte libre des médecins et des scanners — en un portrait numérique unique et riche. Ce portrait peut ensuite être réutilisé pour classer les patients en groupes biologiquement pertinents et pour prédire qui court le plus de risque de mourir, même lorsqu'on ne dispose que d'un petit ensemble d'exemples annotés pour l'entraînement.
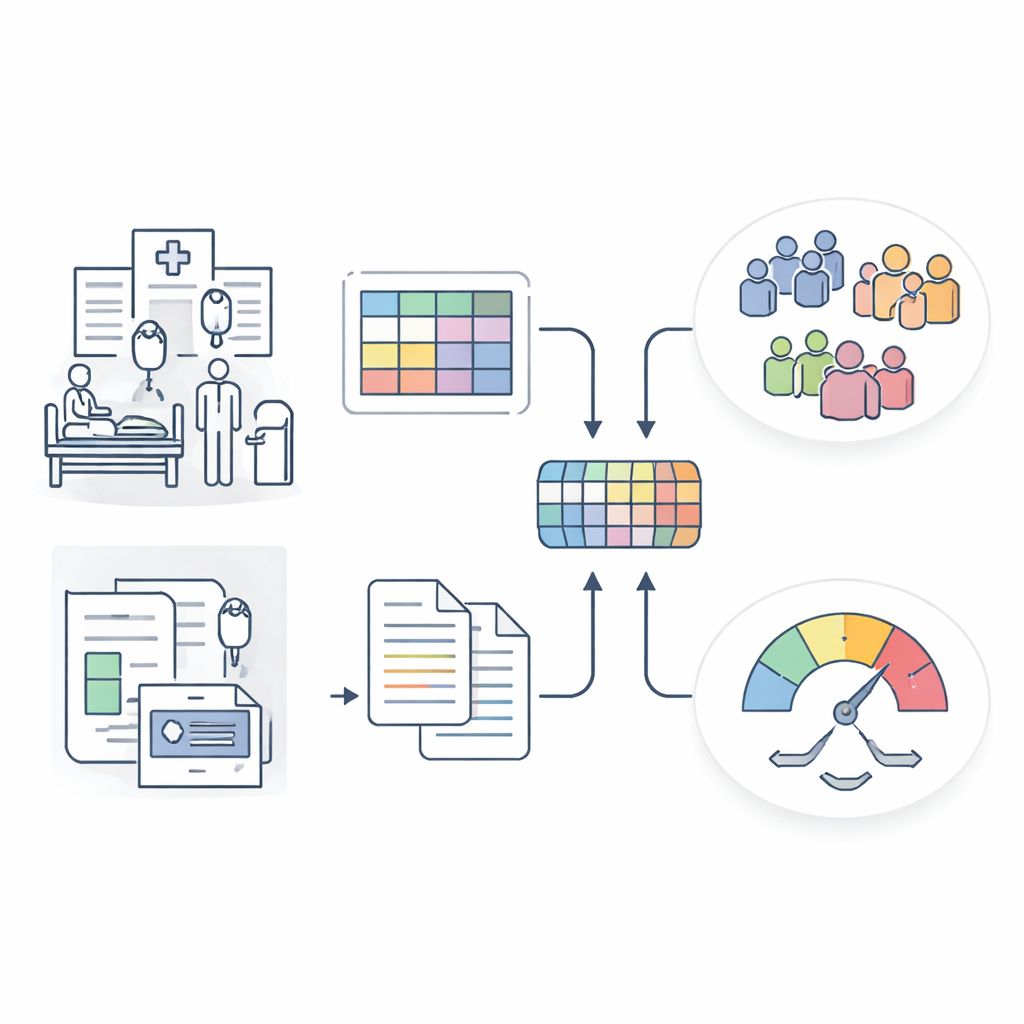
Une image plus intelligente de la sepsie à partir de données hospitalières mixtes
Les chercheurs ont construit le Sepsis Data Representation Model, ou SepsisDRM, en utilisant les dossiers de 19 526 patients atteints de sepsie traités au Guangdong Provincial Hospital of Chinese Medicine et dans ses établissements affiliés. Chaque patient a fourni deux types d'informations. D'une part, des entrées structurées, comme l'âge, les maladies préexistantes, les scores de défaillance d'organes et 31 mesures de laboratoire de routine telles que des marqueurs d'inflammation, de coagulation, la fonction hépatique et rénale, et les lipides sanguins. D'autre part, des sources textuelles non structurées, y compris les résultats de cultures microbiologiques et les comptes rendus de scanners par les radiologues. Plutôt que de traiter ces flux séparément, SepsisDRM traite les tableaux avec un réseau neuronal conçu pour les nombres et le texte avec un modèle de langage moderne, puis fusionne les deux en une représentation partagée pour chaque patient.
Apprendre sans étiquettes pour révéler des types de patients cachés
Pour éviter le besoin d'un grand volume d'annotations expertes, SepsisDRM utilise une approche appelée apprentissage contrastif. Le modèle génère des « vues » légèrement différentes du même dossier patient et apprend à rapprocher ces vues dans son espace interne, tout en repoussant les dossiers d'autres patients. Une fois entraîné, chaque patient est représenté par un point unique dans cet espace. L'équipe a ensuite appliqué un regroupement et a constaté que quatre groupes capturaient au mieux la structure des données : un groupe à forte inflammation, un groupe à faible inflammation, un groupe intermédiaire et un groupe en défaillance multiorganique. Ces grappes différaient nettement dans les résultats des analyses, la charge de maladies chroniques et les taux de décès hospitaliers, le groupe en défaillance multiorganique présentant les pires résultats et le groupe à faible inflammation les meilleurs.
Relier les groupes numériques aux réponses réelles au traitement
Les auteurs sont allés au‑delà de la simple description pour se demander si ces groupes définis par les données pouvaient orienter la thérapie. Ils ont examiné l'utilisation du Xuebijing, une injection issue de la médecine traditionnelle chinoise largement utilisée en Chine comme traitement complémentaire de la sepsie. Après avoir apparié avec soin les patients traités et non traités sur l'âge, la défaillance d'organes et les comorbidités, ils ont comparé les taux de mortalité au sein de chaque phénotype. Dans la population sepsie globale et dans trois des quatre groupes, le Xuebijing n'a pas montré de bénéfice net clair. Mais dans le groupe à forte inflammation, les patients ayant reçu le médicament avaient significativement moins de risques de mourir à l'hôpital que des patients similaires non traités, ce qui suggère que cette thérapie pourrait être la plus utile pour un sous‑type biologique spécifique plutôt que pour tous les patients atteints de sepsie.
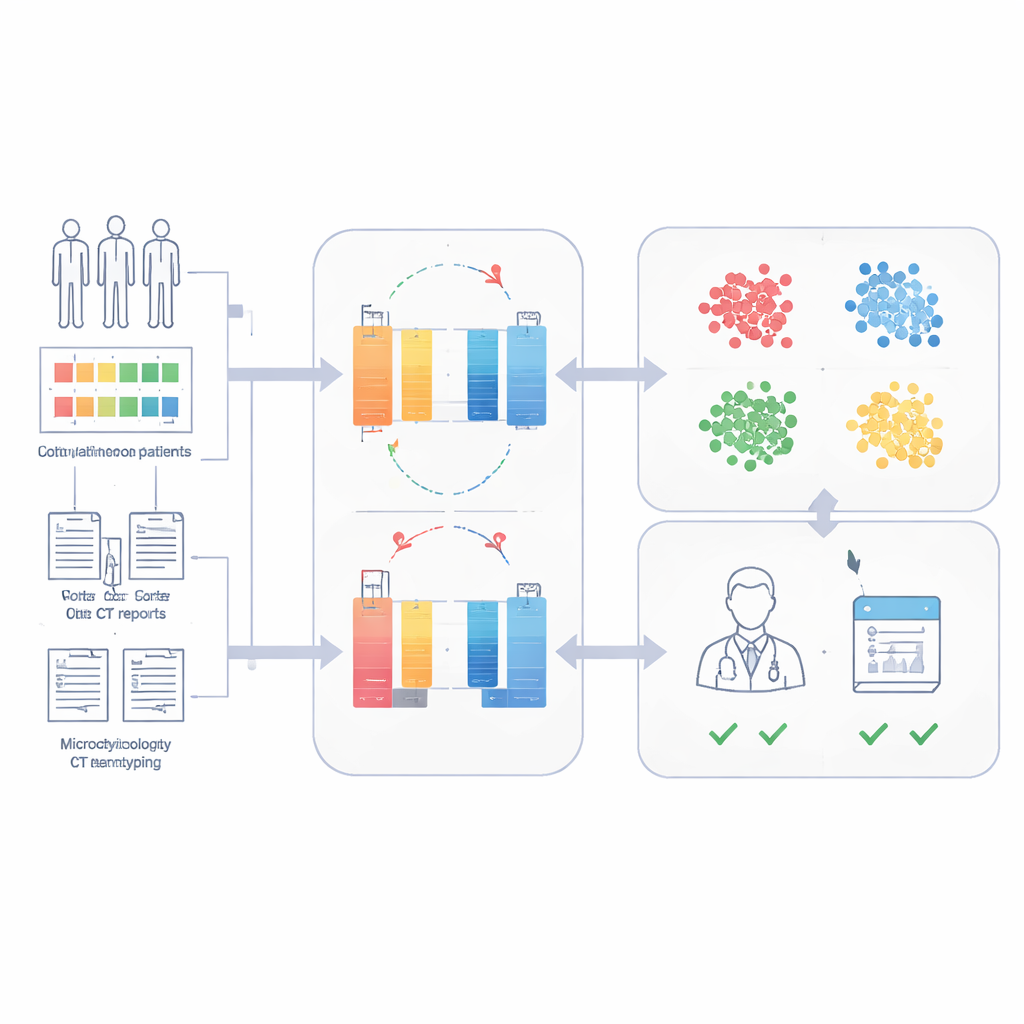
Prédire la survie à 28 jours avec peu de cas étiquetés
Parce que SepsisDRM encode déjà un portrait détaillé de chaque patient, l'équipe a pu entraîner un classificateur simple sur ces portraits pour prédire si un patient serait vivant 28 jours après l'admission. En n'utilisant que de petits jeux de données étiquetés, le modèle a atteint une grande précision : des aires sous la courbe ROC de 0,83 et 0,82 sur des jeux de test rétrospectif et prospectif du même hôpital, et 0,69 sur un hôpital externe ayant des pratiques et des styles de documentation différents. Dans une comparaison directe sur une cohorte prospective, SepsisDRM était plus sensible et plus cohérent que 11 médecins humains de niveaux d'ancienneté variés, manquant moins de patients qui ont ensuite décédé tout en maintenant un taux élevé de classifications « sûres » correctes.
Ce que cela signifie pour l'avenir des soins en cas de sepsie
En termes simples, ce travail montre qu'une représentation numérique unique et réutilisable des patients atteints de sepsie — construite conjointement à partir des chiffres de laboratoire et des notes en texte libre — peut à la fois révéler des sous‑types significatifs de la maladie et alimenter des outils de prédiction des résultats précis. SepsisDRM ne remplace pas les cliniciens, mais il peut servir d'aide à la décision : signaler les patients à haut risque, mettre en évidence ceux qui pourraient bénéficier de traitements spécifiques tels que le Xuebijing, et ce, même dans des contextes où les données étiquetées sont limitées. La même stratégie pourrait être adaptée à d'autres affections pour lesquelles les hôpitaux recueillent un mélange de mesures structurées et de rapports narratifs, ouvrant la voie à des soins critiques plus précis et fondés sur les données.
Citation: Liu, T., Li, Y., Chen, H. et al. A multimodal embedding model for sepsis data representation. npj Digit. Med. 9, 272 (2026). https://doi.org/10.1038/s41746-026-02446-3
Mots-clés: phénotypes de sepsie, encodages multimodaux, prédiction clinique, IA en soins critiques, stratification du traitement