Clear Sky Science · sv
En multimodal inbäddningsmodell för representation av sepsisdata
Varför detta är viktigt för patienter med svåra infektioner
Sepsis är en snabbt förlöpande och ofta dödlig reaktion på infektion, och läkare måste fatta livsavgörande beslut utifrån röriga, ofullständiga sjukhusdata. Denna studie presenterar ett nytt sätt att omvandla allt sjukhuset vet om en sepsispatient — siffror från laboratorietester och fri-textutlåtanden från läkare och avbildningar — till ett enda, rikt digitalt porträtt. Det porträttet kan sedan återanvändas för att dela in patienter i biologiskt meningsfulla grupper och för att förutsäga vilka som löper störst risk att avlida, även när endast en liten träningssats med märkta fall finns tillgänglig.
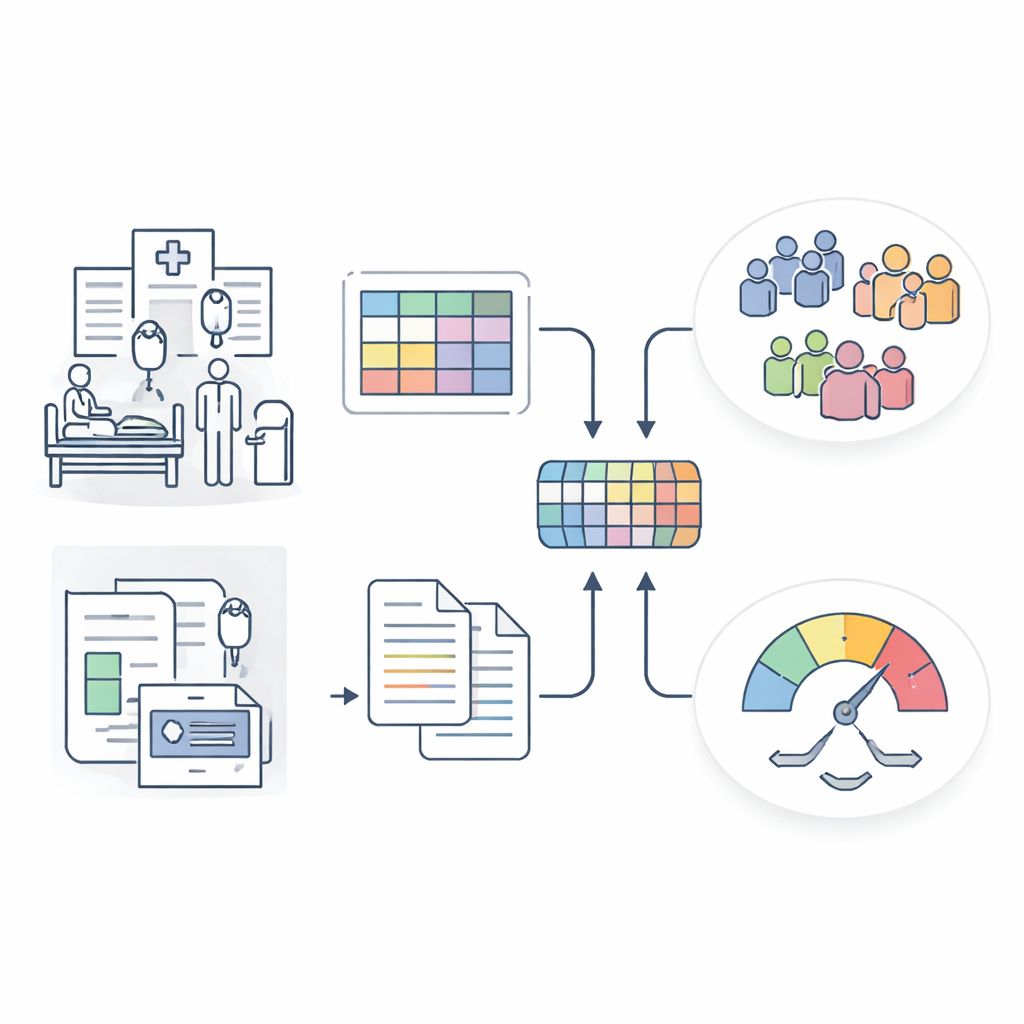
En klarare bild av sepsis från blandade sjukhusdata
Forskarna byggde Sepsis Data Representation Model, eller SepsisDRM, med journaler från 19 526 sepsispatienter som behandlats vid Guangdong Provincial Hospital of Chinese Medicine och dess filialer. Varje patient bidrog med två typer av information. Först fanns strukturerade poster, som ålder, tidigare sjukdomar, organsviktpoäng och 31 rutinmässiga laboratoriemätningar som markörer för inflammation, blodets koagulation, lever‑ och njurfunktion samt blodfetter. Sedan fanns ostrukturerade textkällor, inklusive mikrobiologiska odlingssvar och radiologers CT‑undersökningsrapporter. Istället för att behandla dessa informationsströmmar separat, bearbetar SepsisDRM tabellerna med ett neuralt nätverk avsett för numeriska data och texten med en modern språkmodell, och förenar sedan båda till en gemensam representation för varje patient.
Lära utan etiketter för att upptäcka dolda patienttyper
För att undvika behovet av stora mängder expertmärkning använder SepsisDRM en metod som kallas kontrastiv inlärning. Modellen genererar något olika ”vyer” av samma patientjournal och lär sig att dra dessa vyer närmare varandra i sitt interna rum, samtidigt som den skjuter ifrån sig journaler från andra patienter. När träningen är klar representeras varje patient som en enda punkt i detta rum. Teamet tillämpade därefter klustring och fann att fyra grupper bäst fångade datans struktur: en hög‑inflammationsgrupp, en låg‑inflammationsgrupp, en intermediär grupp och en grupp med multisystemorgansvikt. Dessa kluster skilde sig tydligt åt i laboratorieresultat, börda av kronisk sjukdom och dödlighet under sjukhusvistelsen, där gruppen med multisystemorgansvikt hade sämst utfall och låg‑inflammationsgruppen bäst.
Koppla digitala grupper till verkliga behandlingssvar
Författarna gick längre än beskrivning och undersökte om dessa datadrivna grupper kunde vägleda terapi. De granskade användningen av Xuebijing, en injektion baserad på traditionell kinesisk medicin som ofta används som tilläggsbehandling vid sepsis i Kina. Efter noggrann matchning av behandlade och obehandlade patienter avseende ålder, organsvikt och samsjuklighet jämförde de dödsfall inom varje fenotyp. I den totala sepsispopulationen och i tre av de fyra grupperna visade Xuebijing ingen tydlig nytta. Men i hög‑inflammationsgruppen var patienter som fått läkemedlet signifikant mindre benägna att dö på sjukhus än liknande patienter som inte fick det, vilket tyder på att denna terapi kan vara mest hjälpsam för en specifik biologisk undertyp snarare än för alla med sepsis.
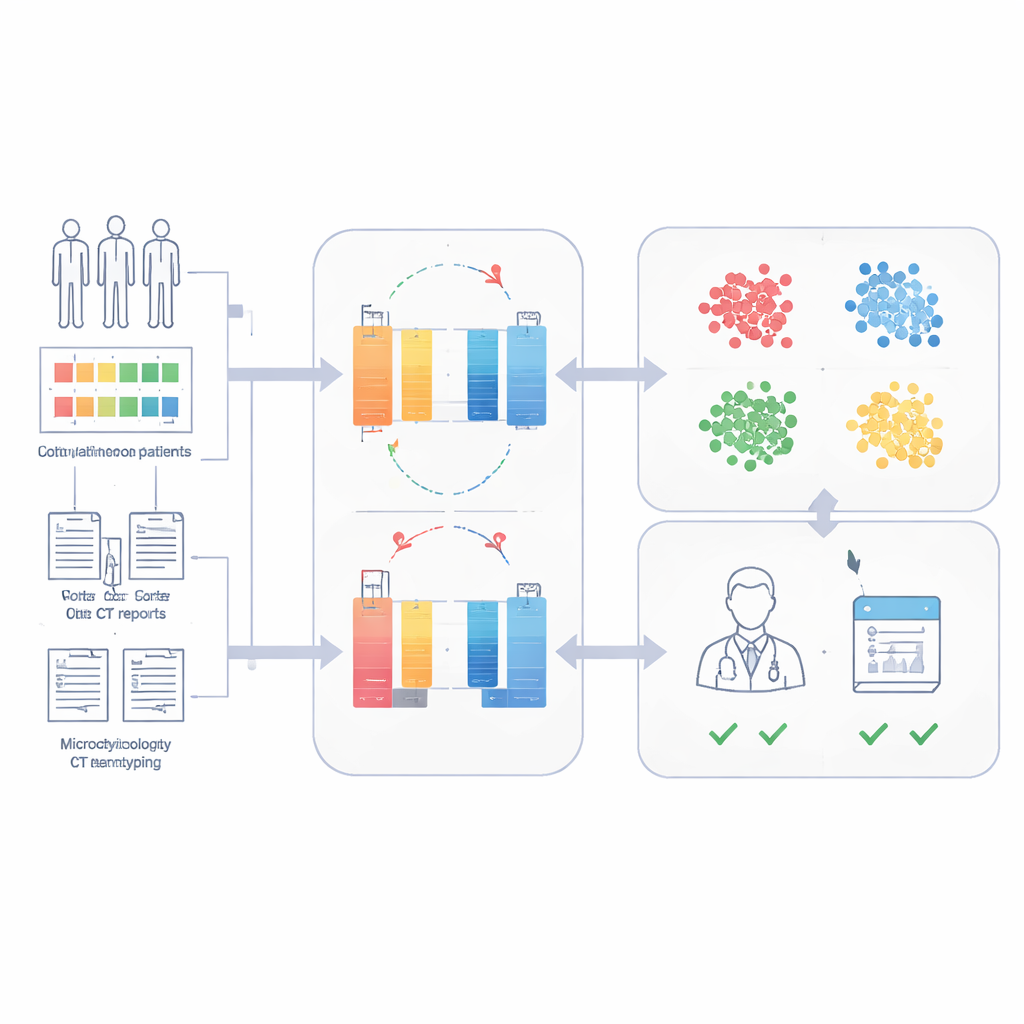
Förutsäga 28‑dagars överlevnad med få märkta fall
Eftersom SepsisDRM redan kodar ett detaljerat porträtt av varje patient kunde teamet träna en enkel klassificerare ovanpå dessa porträtt för att förutsäga om en person skulle vara vid liv 28 dagar efter intagning. Med endast små märkta datamängder uppnådde modellen hög noggrannhet: AUC (area under ROC‑kurvan) på 0,83 respektive 0,82 på retrospektiva och prospektiva testset från samma sjukhus, och 0,69 på ett externt sjukhus med andra arbetsrutiner och dokumentationsstilar. I en huvud‑till‑huvud‑jämförelse på en prospektiv kohort var SepsisDRM mer sensitiv och mer konsekvent än 11 läkare med varierande erfarenhet, och missade färre patienter som senare avled samtidigt som den behöll en hög andel korrekta ”säkra” klassificeringar.
Vad detta betyder för sepsisvårdens framtid
Enkelt uttryckt visar detta arbete att en enda, återanvändbar digital representation av sepsispatienter — byggd gemensamt från laboratorievärden och fri‑textanteckningar — både kan avslöja meningsfulla undertyper av sjukdomen och driva precisa prognosverktyg. SepsisDRM ersätter inte kliniker, men kan fungera som ett beslutsstöd: flagga högriskpatienter, lyfta fram vilka som kan ha nytta av specifika behandlingar som Xuebijing, och göra detta även i miljöer med begränsade märkta data. Samma strategi skulle kunna anpassas till andra tillstånd där sjukhus samlar en blandning av strukturerade mått och narrative rapporter, och bana väg mot mer precis och datadriven intensivvård.
Citering: Liu, T., Li, Y., Chen, H. et al. A multimodal embedding model for sepsis data representation. npj Digit. Med. 9, 272 (2026). https://doi.org/10.1038/s41746-026-02446-3
Nyckelord: sepsisfenotyper, multimodala inbäddningar, klinisk prediktion, AI för intensivvård, behandlingsstratifiering