Clear Sky Science · pl
Model osadzania multimodalnego do reprezentacji danych o sepsie
Dlaczego to ma znaczenie dla pacjentów z ciężkimi zakażeniami
Sepsa to gwałtowna i często śmiertelna reakcja na infekcję, w której lekarze muszą podejmować decyzje o życiu i śmierci na podstawie chaotycznych, niepełnych danych szpitalnych. W tym badaniu przedstawiono nowy sposób przekształcania wszystkiego, co szpital wie o pacjencie z sepsą — liczb z badań laboratoryjnych oraz tekstów swobodnych od lekarzy i opisów badań obrazowych — w jedną, bogatą cyfrową reprezentację. Ta reprezentacja może następnie służyć do grupowania pacjentów w biologicznie sensowne typy oraz do przewidywania, kto jest najbardziej narażony na śmierć, nawet gdy dostępny jest tylko niewielki zbiór oznakowanych przypadków do uczenia.
Mądrzejszy obraz sepsy z mieszanych danych szpitalnych
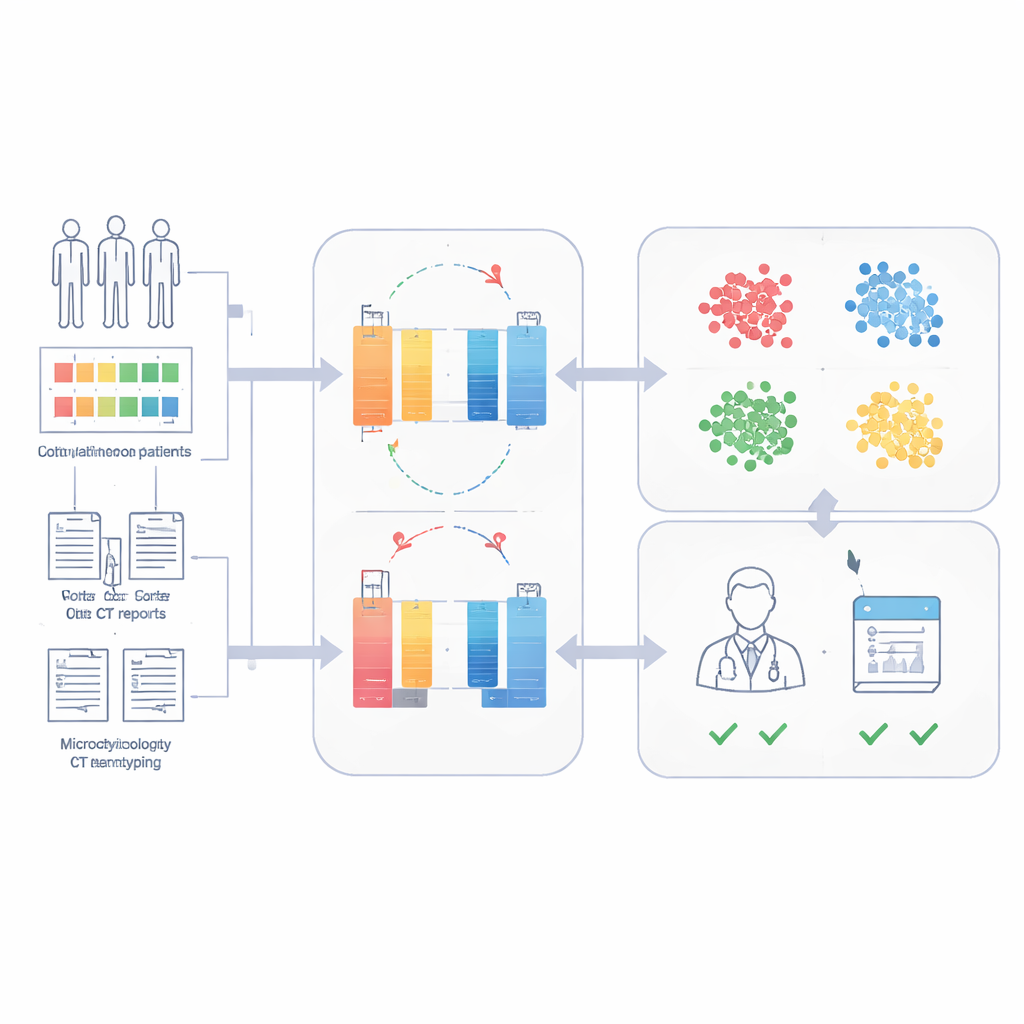
Naukowcy stworzyli Sepsis Data Representation Model, czyli SepsisDRM, korzystając z zapisów 19 526 pacjentów z sepsą leczonych w Guangdong Provincial Hospital of Chinese Medicine i jego oddziałach. Każdy pacjent dostarczył dwa rodzaje informacji. Pierwsze to dane ustrukturyzowane, takie jak wiek, choroby współistniejące, wyniki oceny niewydolności narządów oraz 31 rutynowych badań laboratoryjnych, obejmujących markery zapalenia, krzepnięcia krwi, funkcji wątroby i nerek oraz lipidy krwi. Drugie to źródła nieustrukturyzowane w postaci tekstów, w tym wyniki posiewów mikrobiologicznych i opisy tomografii komputerowej sporządzone przez radiologów. Zamiast traktować te strumienie osobno, SepsisDRM przetwarza tabele za pomocą sieci neuronowej zaprojektowanej do liczb, a teksty za pomocą nowoczesnego modelu językowego, a następnie łączy oba rodzaje danych w wspólną reprezentację dla każdego pacjenta.
Uczenie bez etykiet w celu odkrycia ukrytych typów pacjentów
Aby uniknąć konieczności posiadania dużej ilości ekspertyzy w postaci etykiet, SepsisDRM wykorzystuje podejście zwane uczeniem kontrastowym. Model generuje nieco różne „widoki” tego samego rekordu pacjenta i uczy się przyciągać te widoki bliżej siebie w swojej przestrzeni wewnętrznej, jednocześnie odsuwając zapisy innych pacjentów. Po wytrenowaniu każdy pacjent jest reprezentowany jako pojedynczy punkt w tej przestrzeni. Zespół zastosował następnie grupowanie i stwierdził, że cztery grupy najlepiej odzwierciedlają strukturę danych: grupa o wysokim zapaleniu, grupa o niskim zapaleniu, grupa pośrednia oraz grupa z niewydolnością wielonarządową. Te klastry wyraźnie różniły się wynikami badań laboratoryjnych, obciążeniem chorobami przewlekłymi oraz śmiertelnością w szpitalu — najgorzej wypadała grupa z niewydolnością wielonarządową, a najlepiej grupa o niskim zapaleniu.
Powiązanie cyfrowych grup z rzeczywistymi reakcjami na leczenie
Autorzy poszli dalej niż opis i sprawdzili, czy te grupy wyodrębnione z danych mogą kierować terapią. Zbadali stosowanie Xuebijing, tradycyjnego chińskiego leku w postaci wstrzyknięcia, powszechnie używanego jako leczenie dodatkowe w sepsie w Chinach. Po starannym dopasowaniu leczonych i nieleczonych pacjentów pod kątem wieku, niewydolności narządów i chorób współistniejących, porównali wskaźniki zgonów w ramach każdego fenotypu. W całej populacji septycznej oraz w trzech z czterech grup Xuebijing nie wykazało wyraźnej korzyści. Jednak w grupie o wysokim zapaleniu pacjenci, którzy otrzymali lek, mieli istotnie mniejsze prawdopodobieństwo zgonu w szpitalu niż podobni pacjenci, którzy go nie otrzymali, co sugeruje, że terapia ta może być najbardziej pomocna dla określonego podtypu biologicznego, a nie dla wszystkich chorych na sepsę.
Predykcja przeżycia 28 dni przy niewielu oznakowanych przypadkach
Ponieważ SepsisDRM już zakodował szczegółowy portret każdego pacjenta, zespół mógł wytrenować prosty klasyfikator na podstawie tych portretów, aby przewidywać, czy pacjent będzie żywy 28 dni po przyjęciu. Korzystając jedynie z małych zestawów oznakowanych danych, model osiągnął wysoką dokładność: pola pod krzywą ROC 0,83 i 0,82 na retrospektywnych i prospektywnych zestawach testowych z tego samego szpitala oraz 0,69 w zewnętrznym szpitalu o odmiennych praktykach i stylach dokumentacji. W bezpośrednim porównaniu na kohorcie prospektywnej SepsisDRM był bardziej czuły i bardziej spójny niż 11 lekarzy o różnym stopniu doświadczenia, przeoczając mniej pacjentów, którzy potem zmarli, zachowując jednocześnie wysoki odsetek prawidłowych klasyfikacji „bezpiecznych”.
Co to oznacza dla przyszłości opieki nad sepsą
Mówiąc wprost, praca ta pokazuje, że jedna, wielokrotnego użytku cyfrowa reprezentacja pacjentów z sepsą — zbudowana łącznie z danych laboratoryjnych i notatek tekstowych — może zarówno ujawniać znaczące podtypy choroby, jak i napędzać dokładne narzędzia do przewidywania wyników. SepsisDRM nie zastępuje klinicystów, ale może pełnić funkcję wsparcia w podejmowaniu decyzji: sygnalizować pacjentów wysokiego ryzyka, wskazywać, kto może skorzystać ze specyficznych terapii takich jak Xuebijing, i robić to nawet w warunkach z ograniczonymi danymi oznakowanymi. Ta sama strategia może zostać zaadaptowana do innych schorzeń, w których szpitale gromadzą mieszankę ustrukturyzowanych pomiarów i raportów narracyjnych, otwierając drogę do bardziej precyzyjnej i opartej na danych opieki intensywnej.
Cytowanie: Liu, T., Li, Y., Chen, H. et al. A multimodal embedding model for sepsis data representation. npj Digit. Med. 9, 272 (2026). https://doi.org/10.1038/s41746-026-02446-3
Słowa kluczowe: fenotypy sepsy, osadzenia multimodalne, predykcja kliniczna, Sztuczna inteligencja w intensywnej opiece, stratyfikacja leczenia