Clear Sky Science · nl
Een multimodaal embeddingmodel voor representatie van sepsisgegevens
Waarom dit belangrijk is voor patiënten met ernstige infecties
Sepsis is een snel voortschrijdende en vaak dodelijke reactie op een infectie, waarbij artsen levensreddende beslissingen moeten nemen op basis van rommelige, onvolledige ziekenhuisgegevens. Deze studie introduceert een nieuwe manier om alles wat het ziekenhuis over een sepsispatiënt weet — zowel cijfers uit laboratoriumtests als vrije‑tekstverslagen van artsen en scanners — om te zetten in een enkele, rijke digitale portrettering. Dat portret kan vervolgens hergebruikt worden om patiënten in biologisch betekenisvolle groepen te verdelen en om te voorspellen wie het grootste risico loopt te overlijden, zelfs wanneer er slechts een kleine getrainde set met gelabelde gevallen beschikbaar is.
Een slimmer beeld van sepsis uit gemengde ziekenhuisgegevens
De onderzoekers bouwden het Sepsis Data Representation Model, of SepsisDRM, met gegevens van 19.526 sepsispatiënten behandeld in het Guangdong Provincial Hospital of Chinese Medicine en zijn vestigingen. Elke patiënt leverde twee soorten informatie. Ten eerste gestructureerde vermeldingen, zoals leeftijd, bestaande ziekten, scores voor orgaanfalen en 31 routinematige laboratoriummetingen zoals markers voor ontsteking, bloedstolling, lever‑ en nierfunctie en bloedlipiden. Ten tweede ongestructureerde tekstbronnen, waaronder microbiologische kweekresultaten en radiologenverslagen van CT‑scans. In plaats van deze stromen apart te behandelen, verwerkt SepsisDRM de tabellen met een neuraal netwerk voor numerieke gegevens en de tekst met een modern taalmodel, en versmelt beide vervolgens tot een gedeelde representatie voor elke patiënt.
Leren zonder labels om verborgen patiënttypen te ontdekken
Om de behoefte aan grote aantallen expertlabels te vermijden, gebruikt SepsisDRM een benadering genaamd contrastief leren. Het model genereert licht verschillende "beelden" van hetzelfde patiëntenrecord en leert die beelden dichter bij elkaar te trekken in zijn interne ruimte, terwijl records van andere patiënten weggehouden worden. Eenmaal getraind wordt elke patiënt weergegeven als één punt in die ruimte. Het team paste vervolgens clustering toe en ontdekte dat vier groepen het best de structuur van de gegevens vingen: een hoog‑ontstekingsgroep, een laag‑ontstekingsgroep, een intermediaire groep en een groep met meervoudig orgaanfalen. Deze clusters verschilden duidelijk in laboratoriumuitslagen, ziektedruk van chronische aandoeningen en ziekenhuissterftecijfers, waarbij de groep met meervoudig orgaanfalen het slechtst af was en de laag‑ontstekingsgroep het best.
Digitale groepen koppelen aan werkelijke behandelreacties
De auteurs gingen verder dan beschrijving en onderzochten of deze datagedreven groepen therapiekeuzes konden sturen. Ze bekeken het gebruik van Xuebijing, een injectie gebaseerd op traditionele Chinese geneeskunde die veel wordt ingezet als aanvullende behandeling voor sepsis in China. Na zorgvuldige matching van behandelde en onbehandelde patiënten op leeftijd, orgaanfalen en co‑bestaande aandoeningen, vergeleken ze de sterftecijfers binnen elk fenotype. In de totale sepsispopulatie en in drie van de vier groepen liet Xuebijing geen duidelijk voordeel zien. Maar in de hoog‑ontstekingsgroep waren patiënten die het middel kregen significant minder vaak in het ziekenhuis overleden dan vergelijkbare patiënten die het niet kregen, wat suggereert dat deze therapie het meest behulpzaam kan zijn voor een specifiek biologisch subtype in plaats van voor alle sepsispatiënten.
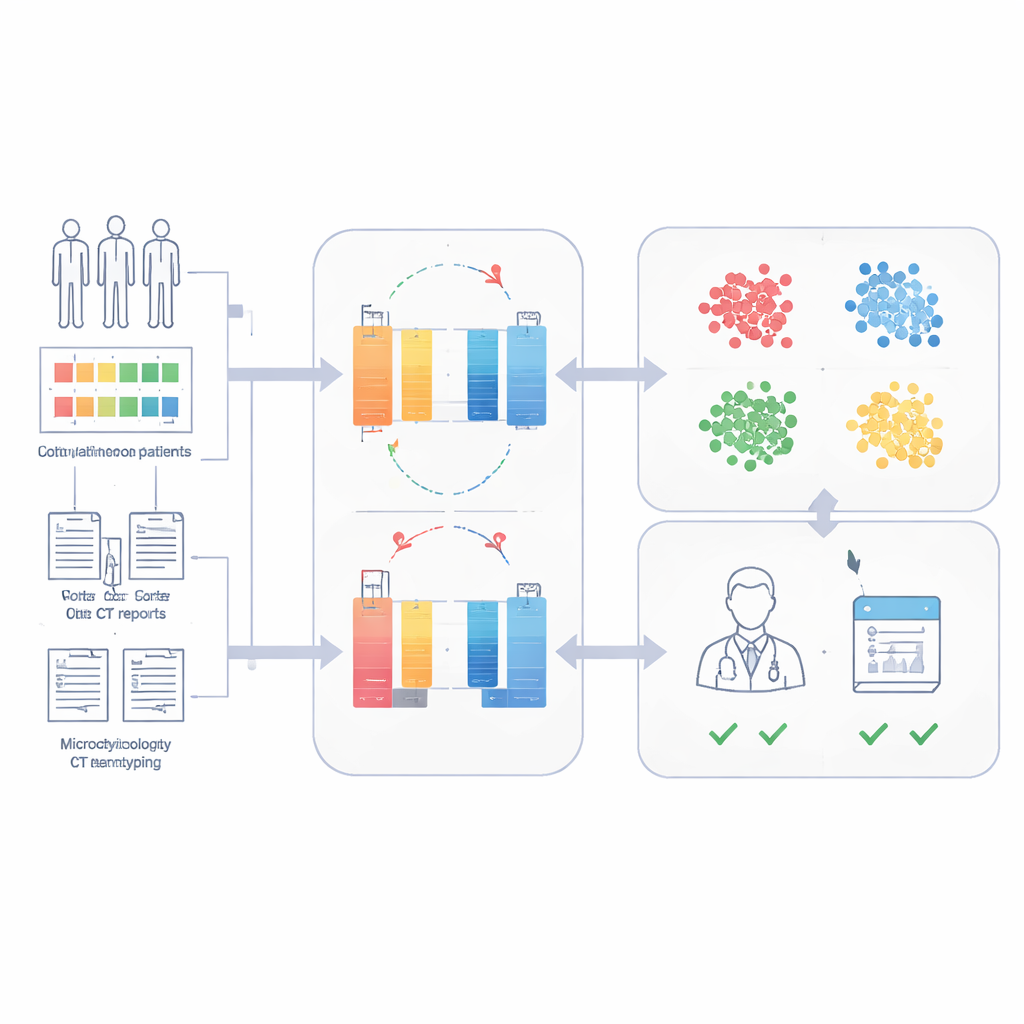
Voorspellen van 28‑daags overleven met weinig gelabelde gevallen
Omdat SepsisDRM al een gedetailleerd portret van elke patiënt codeert, kon het team een eenvoudige classifier trainen bovenop die portretten om te voorspellen of iemand 28 dagen na opname nog in leven zou zijn. Met slechts kleine gelabelde datasets behaalde het model hoge nauwkeurigheid: gebieden onder de ROC‑curve van 0,83 en 0,82 op retrospectieve en prospectieve testsets van hetzelfde ziekenhuis, en 0,69 op een extern ziekenhuis met andere werkwijzen en documentatiestijlen. In een directe vergelijking op een prospectieve cohorte was SepsisDRM gevoeliger en consistenter dan 11 menselijke artsen van verschillende senioriteit, waarbij het minder patiënten miste die later zouden overlijden en tegelijk een hoog percentage juiste "veilige" classificaties behield.
Wat dit betekent voor de toekomst van sepsiszorg
In eenvoudige bewoordingen laat dit werk zien dat een enkele, herbruikbare digitale representatie van sepsispatiënten — gezamenlijk opgebouwd uit laboratoriumcijfers en vrije‑tekstnotities — zowel betekenisvolle subtypes van de ziekte kan onthullen als accurate voorspellingsinstrumenten voor uitkomsten kan aandrijven. SepsisDRM vervangt clinici niet, maar kan functioneren als een besluitvormingshulp: het markeren van hoogrisicopatiënten, het aangeven wie baat kan hebben bij specifieke behandelingen zoals Xuebijing, en dat zelfs in omgevingen met beperkte gelabelde data. Dezelfde strategie zou aangepast kunnen worden voor andere aandoeningen waarbij ziekenhuizen een mix van gestructureerde metingen en narratieve rapporten verzamelen, en opent zo een weg naar meer precieze en datagedreven intensivecarezorg.
Bronvermelding: Liu, T., Li, Y., Chen, H. et al. A multimodal embedding model for sepsis data representation. npj Digit. Med. 9, 272 (2026). https://doi.org/10.1038/s41746-026-02446-3
Trefwoorden: sepsisfenotypen, multimodale embeddings, klinische voorspelling, AI voor intensive care, behandelingsstratificatie