Clear Sky Science · zh
用于从呼吸声音诊断哮喘的混合深度学习与 YAMNet 特征
倾听呼吸而非对着管子用力吹气
对于数以百万计的哮喘患者来说,获得明确诊断通常意味着去诊所做肺功能检查,这既费力又耗时,而且难以定期重复。本研究探索了一个截然不同的思路:使用用手机麦克风或数字听诊器等简单设备录下的呼吸与咳嗽声音,来判断某人是患有哮喘还是其他肺部疾病。通过将这些声音转化为计算机可以识别的模式,研究人员旨在构建一种准确且廉价的工具,未来可为远程检查和移动健康应用提供支持。
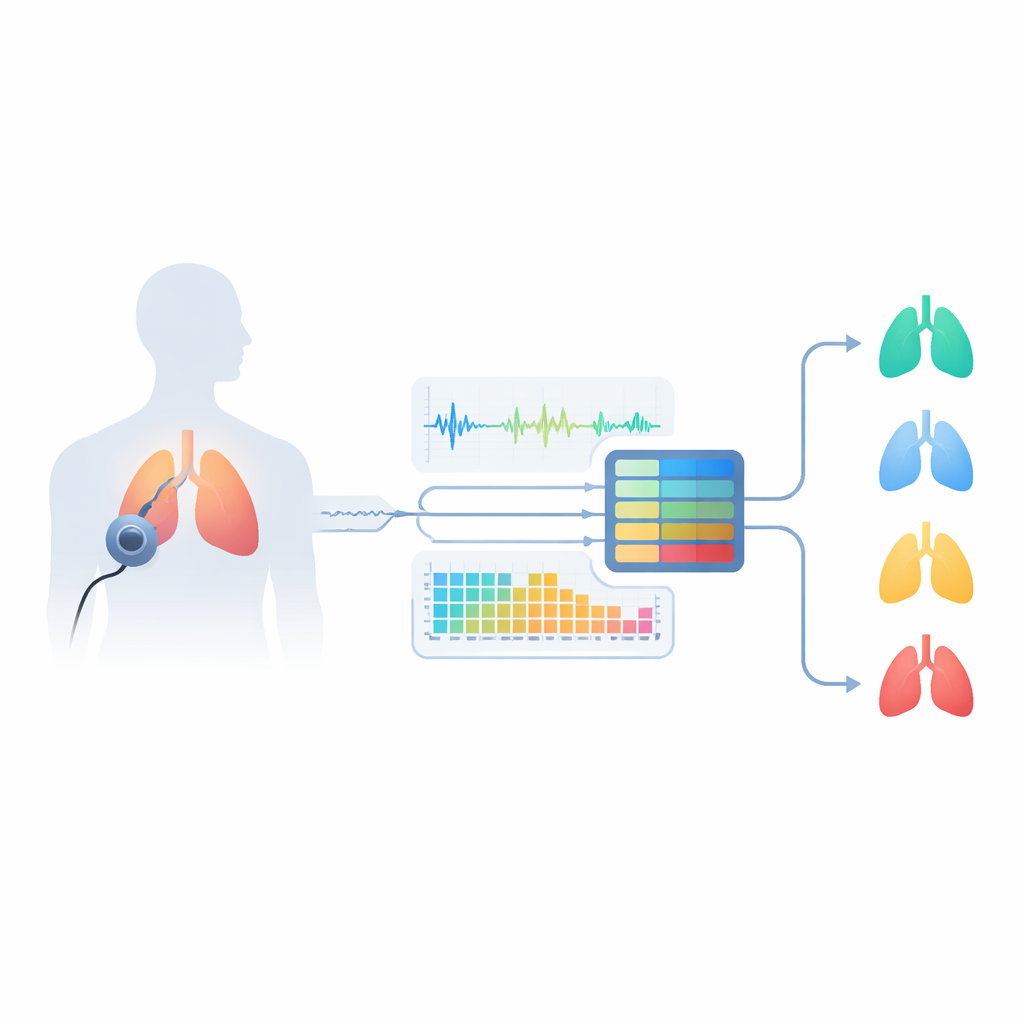
为什么呼吸声音蕴含隐秘线索
哮喘影响气道,使其变窄并导致气流不稳定。这会产生典型噪声,如喘息声(类似口哨音的音调)和爆裂声(短促的爆破声),传统上医生使用听诊器来听这些声音。然而,慢性阻塞性肺疾病(COPD)、支气管炎或肺炎等其他肺部疾病也可能产生类似声音,这使得即便是专家也难以诊断。像肺活量测定这样的标准检测需要到诊所、依赖受过训练的人员与专用设备,并可能遗漏哮喘的多样类型。作者认为,仔细分析录制的呼吸声音可以更便捷地捕捉这些微妙差异,并有助于区分多种肺部疾病与健康呼吸。
为肺部声音构建智能“听者”
研究团队设计了一个“智能听者”系统,始于来自公开 Kaggle 数据集 Asthma Detection Dataset v2 的真实世界录音。这些是用普通手机在日常环境中收集的短音频片段,包含咳嗽与呼吸,并标注为哮喘、COPD、肺炎、支气管炎或健康。由于录音在时长和质量上存在差异,研究人员首先对其清理:统一音量、去除长时间静音、滤除过低和过高频率,并将音频切成固定的六秒片段以捕捉完整的呼吸周期。他们还制造了真实的变化——稍微加速或减速、移调以及添加轻度背景噪声——以训练系统应对杂乱的真实环境,而不仅仅适用于洁净的实验室录音。
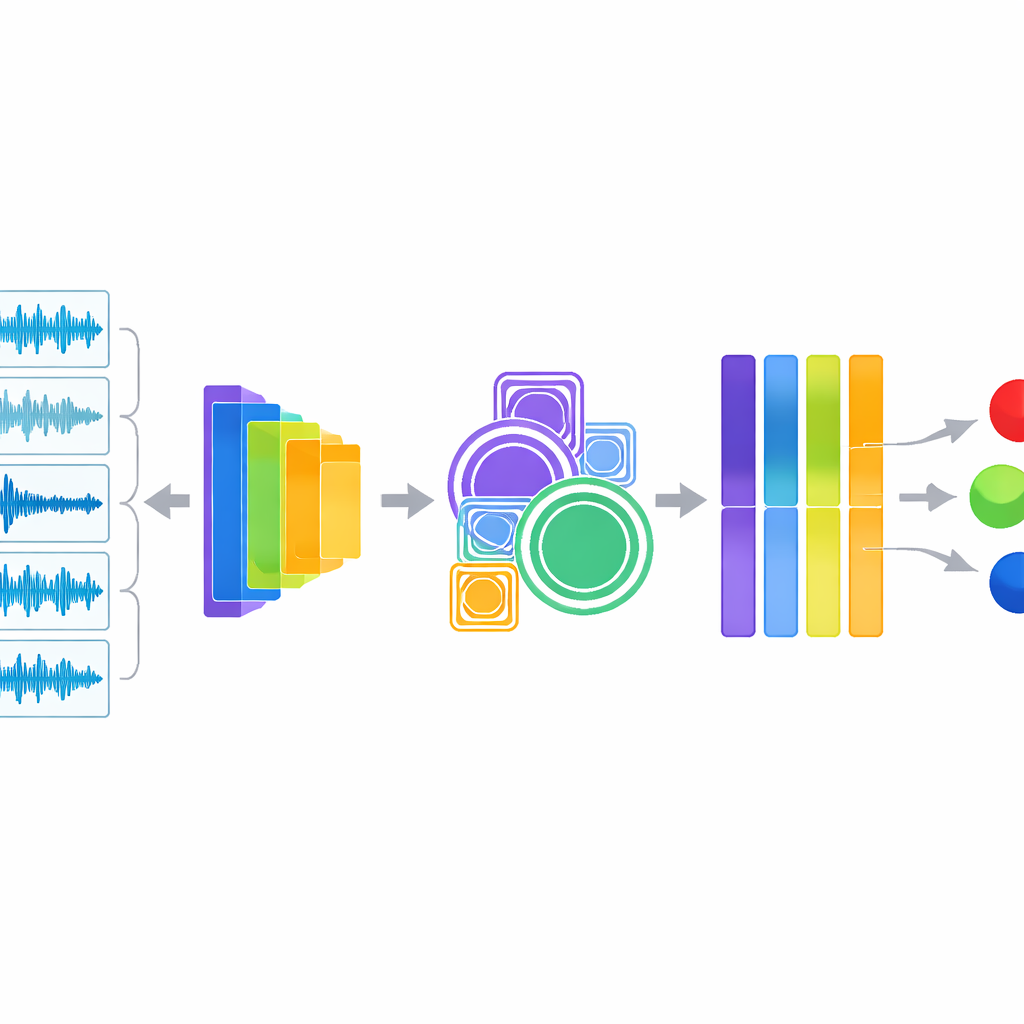
结合可理解的特征与深度模式
该系统的核心是一种同时采用两种听法的混合方法。一条分支提取音频工程师和临床医生熟悉的经典音频描述符,例如能量在各个音高的分布、信号过零率以及声音能量随时间的升降,这些度量已知能突出显示喘息和爆裂声。第二条分支将相同音频输入 YAMNet——这是 Google 在大量日常声音上训练出的紧凑深度学习模型。YAMNet 将每秒的呼吸转成丰富的数值“指纹”,捕捉手工难以描述的复杂模式。研究人员随后融合这两种声音视角,并将组合信息通过额外模块处理,这些模块在多尺度上放大模式并自动强调最具信息量的通道,最终由分类器给出诊断。
测试准确性并揭示“黑箱”内部
为评估系统性能,作者采用了称为分层五折交叉验证的严谨测试策略,确保每种肺部疾病在训练和测试阶段得到公平代表。模型达到约 98.6% 的准确率,并取得相近的高 F1 分数与曲线下面积,明显优于若干强基线方法,包括传统机器学习模型、在频谱图图像上训练的标准卷积网络,以及仅使用 YAMNet 的简化版本。更重要的是,团队并未满足于表面数字,而是使用可视化工具展示不同病情如何产生独特的波形和频谱图模式,并采用来自博弈论的 SHAP 方法突出哪些特征与网络中的隐含单元对每次预测影响最大。这些分析表明,模型关注的有临床意义的线索,如持续的高频带和对应喘息或爆裂声的突发能量爆发。
这对日常护理可能意味着什么
通俗地说,研究表明,一个精心构建的深度学习系统能以接近专家的准确度“听懂”呼吸,即便录音是在普通设备和嘈杂环境下采集的。通过将可解释的音频特征与强大的学习表征相结合,并通过可视化图与特征重要性评分解释其决策,系统更接近可信赖的数字助理,而非神秘的黑箱。尽管仍需在更多、更大规模的数据集上验证并在临床实践中验证,该方法指向了可在手机或轻量硬件上运行的未来工具,帮助医生与患者快速、无创且低成本地监测哮喘及相关肺病。
引用: Shatat, G.A.EL., Moustafa, H.ED., Saraya, M.S. et al. Hybrid deep learning and YAMNet features for asthma diagnosis from respiratory sounds. Sci Rep 16, 13781 (2026). https://doi.org/10.1038/s41598-026-49247-y
关键词: 哮喘诊断, 呼吸声音, 深度学习, 移动健康, 医学音频分析