Clear Sky Science · pl
Hybrydowe cechy głębokiego uczenia i YAMNet do diagnozowania astmy na podstawie dźwięków oddechowych
Słuchanie oddechów zamiast dmuchania w rurkę
Dla milionów osób z astmą jasna diagnoza często oznacza wizytę w przychodni i wykonanie testów czynnościowych płuc, które mogą być męczące, czasochłonne i trudne do powtarzania regularnie. Badanie to eksploruje zupełnie inne podejście: wykorzystanie dźwięku oddechu i kaszlu, nagranego czymś tak prostym jak mikrofon telefonu lub cyfrowy stetoskop, by określić, czy dana osoba ma astmę czy inne schorzenie płuc. Przekształcając te dźwięki w wzorce rozpoznawalne przez komputer, autorzy dążą do stworzenia dokładnego, taniego narzędzia, które mogłoby w przyszłości wspierać zdalne kontrole i aplikacje zdrowia mobilnego.
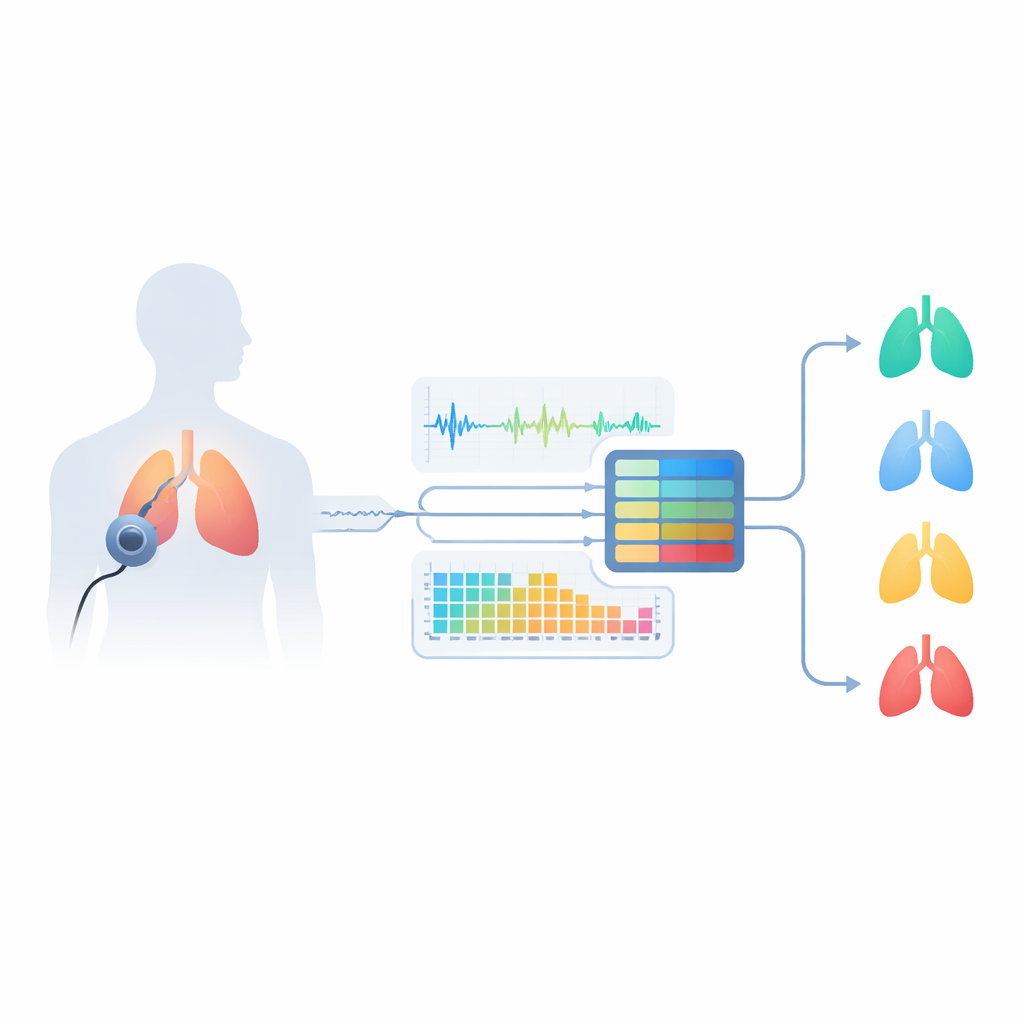
Dlaczego dźwięki oddechowe kryją ukryte wskazówki
Astma wpływa na drogi oddechowe, zwężając je i utrudniając przepływ powietrza. Powoduje to charakterystyczne odgłosy, takie jak świsty (gwizdowe tony) i trzeszczenia (krótkie dźwięki pęknięć), których lekarze tradycyjnie szukają za pomocą stetoskopu. Jednak osoby z innymi chorobami płuc — takimi jak przewlekła obturacyjna choroba płuc (POChP), zapalenie oskrzeli czy zapalenie płuc — mogą wydawać podobne dźwięki, co utrudnia diagnozę nawet specjalistom. Standardowe testy, takie jak spirometria, wymagają wizyt w placówce, przeszkolonego personelu i specjalistycznego sprzętu, a ponadto mogą nie wychwycić całej różnorodności typów astmy. Autorzy argumentują, że staranna analiza nagranych dźwięków oddechowych mogłaby wygodniej uchwycić subtelne różnice i pomóc rozróżnić kilka chorób płuc oraz zdrowe oddychanie.
Budowa inteligentnego słuchacza dźwięków płuc
Zespół zaprojektował system „inteligentnego słuchacza”, który zaczyna od rzeczywistych nagrań z publicznego zbioru danych na Kaggle o nazwie Asthma Detection Dataset v2. To krótkie klipy kaszlu i oddechu zebrane zwykłymi telefonami komórkowymi w codziennych warunkach, oznaczone jako astma, POChP, zapalenie płuc, zapalenie oskrzeli lub zdrowe. Ponieważ nagrania różnią się długością i jakością, badacze najpierw je oczyszczają: standaryzują głośność, usuwają długie cisze, filtrują bardzo niskie i bardzo wysokie częstotliwości oraz dzielą audio na stałe sześciosekundowe fragmenty wystarczająco długie, by uchwycić pełne cykle oddechowe. Tworzą także realistyczne wariacje — nieznaczne przyspieszenie lub spowolnienie dźwięku, przesunięcie wysokości tonu i dodanie łagodnego szumu tła — by nauczyć system radzenia sobie z nieporządkiem codziennych nagrań, a nie tylko idealnych próbek laboratoryjnych.
Łączenie czytelnych dla człowieka i głębokich wzorców
Rdzeń systemu to podejście hybrydowe, które nasłuchuje na dwa sposoby jednocześnie. Jeden moduł wydobywa klasyczne deskryptory audio znane inżynierom dźwięku i klinicystom, takie jak rozkład energii w różnych wysokościach dźwięku, częstotliwość przekraczania zera czy zmiany energii w czasie. Te miary pomagają uwypuklić świsty i trzeszczenia. Drugi moduł podaje to samo nagranie do YAMNet — kompaktowego modelu głębokiego uczenia opracowanego przez Google i wytrenowanego na ogromnej różnorodności codziennych dźwięków. YAMNet przekształca każdą sekundę oddechu w bogaty numeryczny „odcisk palca”, który wychwytuje wzorce zbyt skomplikowane, by opisać je ręcznie. Badacze łączą te dwa spojrzenia na dźwięk i przekazują zintegrowane informacje przez dodatkowe moduły, które analizują wzorce na różnych skalach i automatycznie wzmacniają najbardziej informacyjne kanały, zanim końcowy klasyfikator postawi diagnozę.
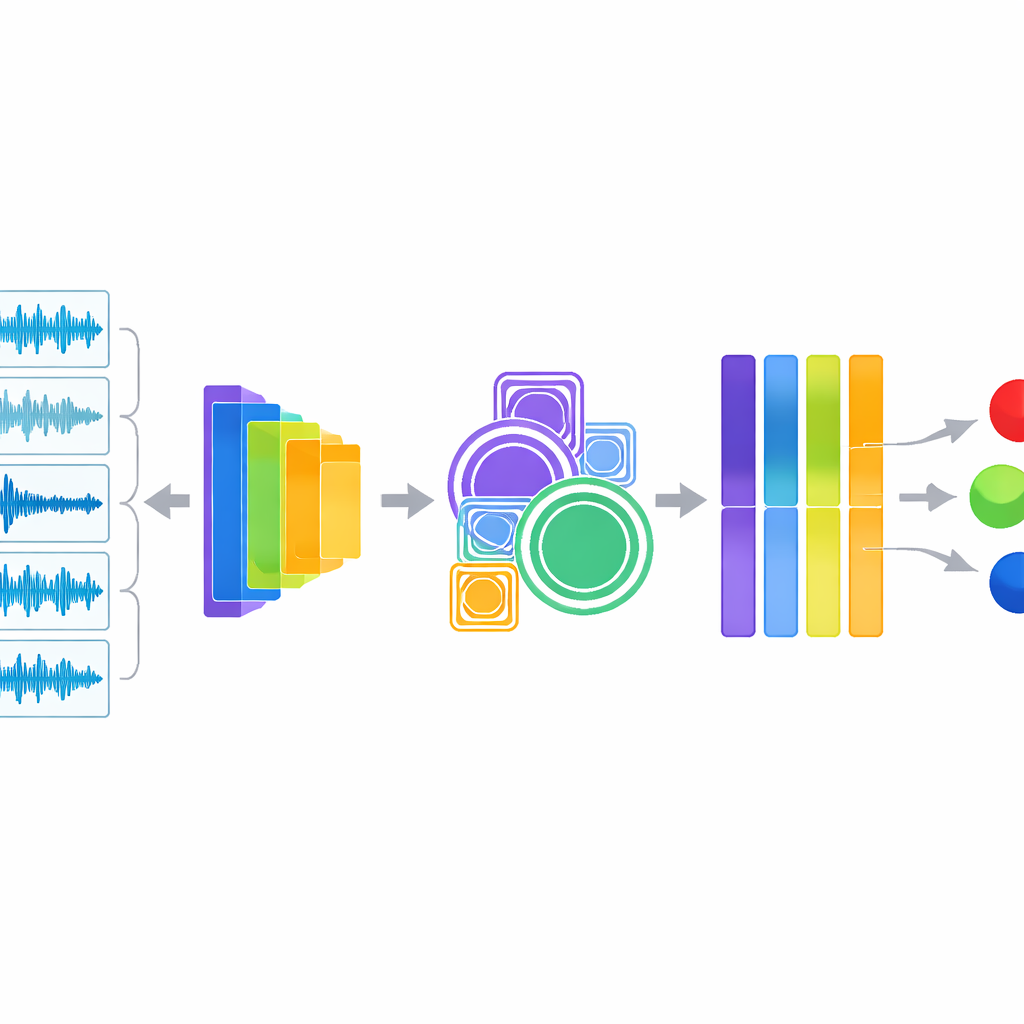
Testowanie dokładności i przejrzystość czarnej skrzynki
Aby sprawdzić skuteczność systemu, autorzy zastosowali staranną strategię testowania nazwaną warstwową walidacją krzyżową pięciu podziałów (stratified five‑fold cross‑validation), co zapewnia uczciwe reprezentowanie każdej choroby płuc w etapach treningu i testowania. Model osiągnął około 98,6% dokładności oraz podobnie wysokie wartości F1 i pola pod krzywą (AUC), zdecydowanie przewyższając kilka silnych alternatyw, w tym konwencjonalne modele uczenia maszynowego, standardowe sieci konwolucyjne pracujące na spektrogramach oraz prostszą wersję opartą wyłącznie na YAMNet. Co ważne, zespół nie poprzestał na efektownych liczbach. Użyli narzędzi wizualizacyjnych, by pokazać, jak różne schorzenia generują odrębne kształty fal i wzory spektrogramów, oraz zastosowali SHAP — metodę zapożyczoną z teorii gier — by uwypuklić, które cechy i ukryte jednostki w sieci najmocniej wpływają na poszczególne przewidywania. Analizy te wykazały, że model koncentruje się na klinicznie istotnych sygnałach, takich jak utrzymujące się pasma wysokiej częstotliwości i nagłe wybuchy odpowiadające świstom i trzeszczeniom.
Co to może znaczyć dla codziennej opieki
Mówiąc prościej, badanie pokazuje, że starannie zbudowany system głębokiego uczenia potrafi „słuchać” oddechu z dokładnością zbliżoną do eksperta, nawet gdy nagrania pochodzą z powszechnych urządzeń w hałaśliwym otoczeniu. Poprzez połączenie zrozumiałych cech audio z potężnymi reprezentacjami uczonymi przez model oraz poprzez wyjaśnianie decyzji za pomocą map wizualnych i rankingów istotności cech, system przybliża się do roli zaufanego asystenta cyfrowego, zamiast tajemniczej czarnej skrzynki. Choć wymaga jeszcze testów na większych i bardziej zróżnicowanych zbiorach danych oraz walidacji w praktyce klinicznej, podejście to wskazuje kierunek rozwoju narzędzi, które mogłyby działać na telefonach lub lekkim sprzęcie, pomagając lekarzom i pacjentom w szybkim, nieinwazyjnym i niedrogim monitorowaniu astmy i pokrewnych chorób płuc.
Cytowanie: Shatat, G.A.EL., Moustafa, H.ED., Saraya, M.S. et al. Hybrid deep learning and YAMNet features for asthma diagnosis from respiratory sounds. Sci Rep 16, 13781 (2026). https://doi.org/10.1038/s41598-026-49247-y
Słowa kluczowe: diagnoza astmy, dźwięki oddechowe, głębokie uczenie, zdrowie mobilne, analiza dźwięku medycznego