Clear Sky Science · nl
Hybride deep learning- en YAMNet‑kenmerken voor astmadiagnose op basis van respiratoire geluiden
Ademgeluiden beluisteren in plaats van in een buis blazen
Voor miljoenen mensen met astma betekent een betrouwbare diagnose vaak een bezoek aan een kliniek en longfunctietests die vermoeiend, tijdrovend en moeilijk regelmatig te herhalen zijn. Deze studie onderzoekt een heel ander idee: het geluid van iemands ademhaling en hoesten gebruiken — opgenomen met iets eenvoudigs als een telefoonmicrofoon of digitale stethoscoop — om te bepalen of die persoon astma of een andere longziekte heeft. Door deze geluiden om te zetten in patronen die een computer kan herkennen, streven de onderzoekers ernaar een nauwkeurig, betaalbaar hulpmiddel te bouwen dat ooit ondersteuning kan bieden bij afstandsconsulten en mobiele gezondheidsapps.
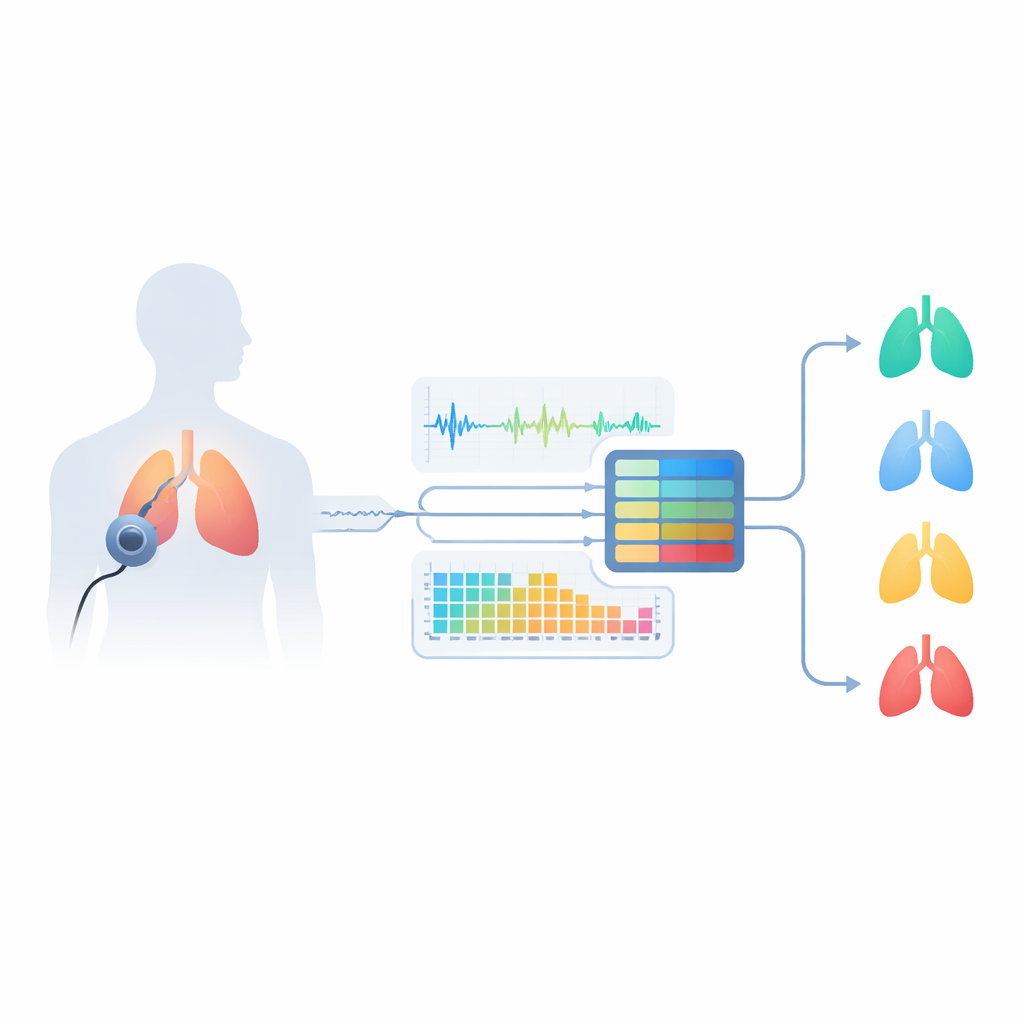
Waarom ademgeluiden verborgen aanwijzingen bevatten
Astma treft de luchtwegen, vernauwt ze en maakt de luchtstroom onregelmatig. Dat produceert karakteristieke geluiden zoals piepende tonen (wheezes) en knisperende geluiden (crackles), die artsen traditioneel met een stethoscoop beluisteren. Mensen met andere longaandoeningen — zoals chronische obstructieve longziekte (COPD), bronchitis of longontsteking — kunnen echter vergelijkbare geluiden produceren, wat de diagnose zelfs voor specialisten lastig maakt. Standaardtests zoals spirometrie vereisen kliniekbezoeken, getraind personeel en speciale apparatuur, en ze kunnen niet alle varianten van astma detecteren. De auteurs betogen dat het zorgvuldig analyseren van opgenomen respiratoire geluiden deze subtiele verschillen handzamer kan vastleggen en kan helpen om onderscheid te maken tussen meerdere longziekten en gezond ademhalen.
Een slimme luisteraar voor longgeluiden bouwen
Het team ontwierp een "slimme luisteraar"-systeem dat begint met realtime-opnamen uit een openbaar Kaggle-dataset genaamd Asthma Detection Dataset v2. Dit zijn korte fragmenten van hoesten en ademhaling verzameld met gewone mobiele telefoons in alledaagse omgevingen, gelabeld als astma, COPD, longontsteking, bronchitis of gezond. Omdat de opnamen in lengte en kwaliteit variëren, schonen de onderzoekers ze eerst op: ze standaardiseren het volume, verwijderen lange stilteperiodes, filteren zeer lage en zeer hoge frequenties en knippen de audio in vaste stukken van zes seconden, lang genoeg om volledige ademhalingscycli vast te leggen. Ze creëren ook realistische variaties — licht versnellen of vertragen van het geluid, toonhoogteverschuivingen en het toevoegen van zachte achtergrondruis — om het systeem te leren omgaan met rommelig, realistisch materiaal in plaats van alleen met vlekkeloze laboratoriumopnamen.
Mensleesbare en diepe patronen combineren
Het hart van het systeem is een hybride benadering die op twee manieren tegelijk luistert. De ene tak extraheert klassieke audiodescriptoren die audiotechnici en clinici begrijpen, zoals hoe energie verspreid is over toonhoogten, hoe snel het signaal nul doorkruist en hoe de geluidsenergie in de tijd toeneemt en afneemt. Deze maten zijn bekend om wheezes en crackles te benadrukken. De tweede tak voert dezelfde audio in YAMNet, een compact deep‑learningmodel dat oorspronkelijk door Google is getraind op een grote verscheidenheid aan alledaagse geluiden. YAMNet zet elke seconde ademhaling om in een rijk numeriek "vingerafdruk" dat patronen vastlegt die te complex zijn om handmatig te beschrijven. De onderzoekers voegen deze twee gezichtspunten samen en voeren de gecombineerde informatie door aanvullende modules die inzoomen op patronen op meerdere schalen en automatisch de meest informatieve kanalen benadrukken voordat een uiteindelijke classifier de diagnose stelt.
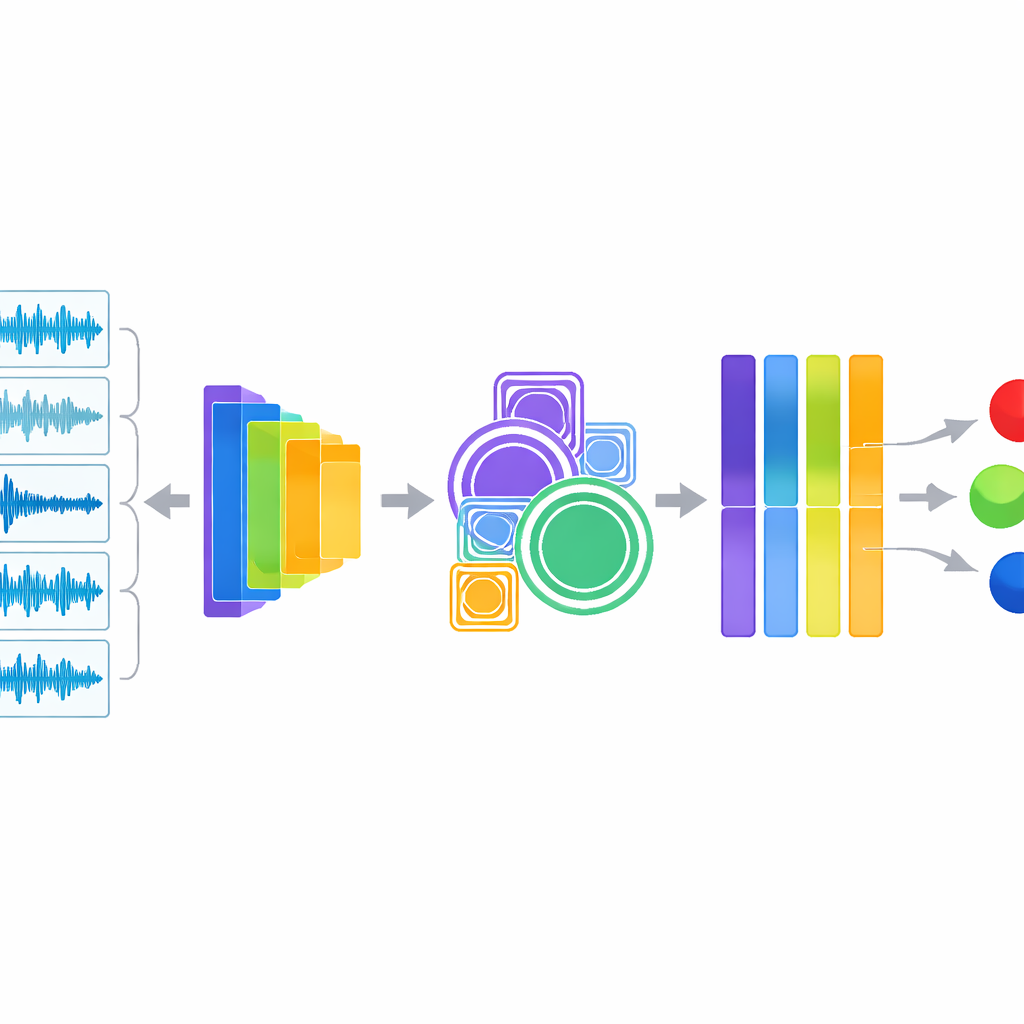
Nauwkeurigheid testen en de zwarte doos transparant maken
Om te beoordelen hoe goed hun systeem werkt, gebruikten de auteurs een zorgvuldige teststrategie genaamd gestratificeerde vijfvoudige cross‑validation, waarmee iedere longconditie eerlijk vertegenwoordigd is in trainings‑ en testfasen. Het model behaalde ongeveer 98,6% nauwkeurigheid en een vergelijkbaar hoge F1‑score en oppervlakte onder de curve, duidelijk beter dan verschillende sterke alternatieven, waaronder conventionele machine‑learningmodellen, standaard convolutionele netwerken op spectrogramafbeeldingen en een eenvoudigere versie die alleen YAMNet gebruikt. Belangrijk is dat het team niet bij kopcijfers bleef. Ze gebruikten visualisatietools om te laten zien hoe verschillende aandoeningen onderscheidende golfvormen en spectrogrampatronen produceren, en pasten SHAP toe — een methode uit de speltheorie — om te benadrukken welke kenmerken en verborgen eenheden in het netwerk elke voorspelling het sterkst beïnvloeden. Deze analyses toonden aan dat het model zich richt op klinisch betekenisvolle signalen zoals aanhoudende hoogfrequente banden en plotselinge uitbarstingen die overeenkomen met wheezes en crackles.
Wat dit kan betekenen voor alledaagse zorg
Simpel gezegd toont de studie aan dat een zorgvuldig opgebouwd deep‑learning‑systeem kan "luisteren" naar ademhaling met bijna deskundige nauwkeurigheid, zelfs wanneer opnamen zijn gemaakt met gewone apparaten in lawaaierige omgevingen. Door begrijpelijke audio‑kenmerken te combineren met krachtige geleerde representaties, en door zijn beslissingen te verklaren via visuele kaarten en kenmerkbelangscore‑overzichten, komt het systeem dichter bij een betrouwbare digitale assistent in plaats van een mysterieuze zwarte doos. Hoewel het nog op meer en grotere datasets getest en in de klinische praktijk gevalideerd moet worden, wijst deze benadering op toekomstige hulpmiddelen die op telefoons of lichtgewicht hardware kunnen draaien en artsen en patiënten snel, niet‑invasief en tegen lage kosten kunnen helpen bij het monitoren van astma en verwante longaandoeningen.
Bronvermelding: Shatat, G.A.EL., Moustafa, H.ED., Saraya, M.S. et al. Hybrid deep learning and YAMNet features for asthma diagnosis from respiratory sounds. Sci Rep 16, 13781 (2026). https://doi.org/10.1038/s41598-026-49247-y
Trefwoorden: astmadiagnose, respiratoire geluiden, deep learning, mobiele gezondheid, medische audioanalyse