Clear Sky Science · fr
Apprentissage profond hybride et caractéristiques YAMNet pour le diagnostic de l’asthme à partir des sons respiratoires
Écouter la respiration plutôt que souffler dans un tube
Pour des millions de personnes atteintes d’asthme, obtenir un diagnostic clair implique souvent de se rendre en consultation et de réaliser des tests de la fonction pulmonaire qui peuvent être fatigants, longs et difficiles à répéter régulièrement. Cette étude explore une idée très différente : utiliser le son de la respiration et de la toux, enregistré avec quelque chose d’aussi simple qu’un microphone de téléphone ou un stéthoscope numérique, pour déterminer si une personne souffre d’asthme ou d’une autre affection pulmonaire. En transformant ces sons en motifs qu’un ordinateur peut reconnaître, les chercheurs visent à construire un outil précis et abordable susceptible, un jour, de soutenir des téléconsultations et des applications de santé mobile.
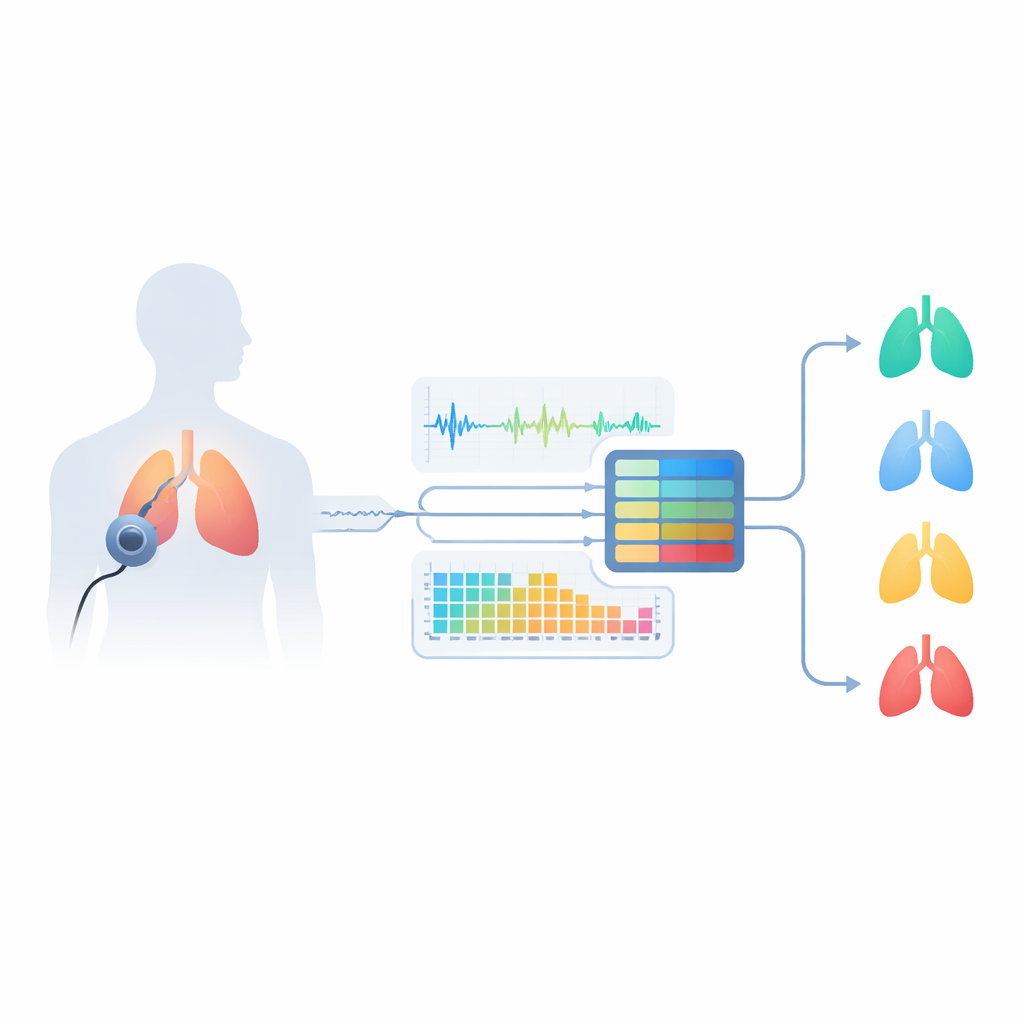
Pourquoi les sons respiratoires contiennent des indices cachés
L’asthme affecte les voies respiratoires, en les rétrécissant et en rendant le flux d’air instable. Cela produit des bruits caractéristiques tels que des sifflements (wheezes) et des crépitements (crackles), que les médecins écoutent traditionnellement au stéthoscope. Cependant, des personnes atteintes d’autres maladies pulmonaires — comme la bronchopneumopathie chronique obstructive (BPCO), la bronchite ou la pneumonie — peuvent produire des sons similaires, ce qui complique le diagnostic même pour les spécialistes. Les tests standard comme la spirométrie exigent des visites en clinique, du personnel formé et du matériel spécialisé, et peuvent ne pas couvrir la pleine diversité des formes d’asthme. Les auteurs soutiennent qu’une analyse soignée des sons respiratoires enregistrés pourrait saisir ces différences subtiles de façon plus pratique et aider à distinguer plusieurs maladies pulmonaires ainsi que la respiration saine.
Construire un auditeur intelligent pour les sons pulmonaires
L’équipe a conçu un système de « auditeur intelligent » qui part d’enregistrements du monde réel issus d’un jeu de données public sur Kaggle nommé Asthma Detection Dataset v2. Il s’agit de courts extraits de toux et de respiration collectés avec des téléphones mobiles ordinaires en environnements quotidiens, étiquetés comme asthme, BPCO, pneumonie, bronchite ou sain. Comme les enregistrements varient en longueur et en qualité, les chercheurs les nettoient d’abord : ils standardisent le volume, retirent les longues silences, filtrent les fréquences très basses et très hautes, et découpent l’audio en segments fixes de six secondes, suffisants pour capturer des cycles respiratoires complets. Ils créent aussi des variations réalistes — léger accéléré ou ralenti, déplacement de hauteur, ajout de bruits de fond discrets — pour apprendre au système à gérer des conditions du monde réel plutôt que des enregistrements de laboratoire parfaits.
Combiner des motifs lisibles par l’humain et des représentations profondes
Au cœur du système se trouve une approche hybride qui écoute de deux manières à la fois. Une branche extrait des descripteurs audio classiques compris par les ingénieurs du son et les cliniciens, tels que la répartition de l’énergie selon les hauteurs, la fréquence des passages par zéro, et la façon dont l’énergie sonore monte et descend dans le temps. Ces mesures mettent en évidence les sifflements et les crépitements. La seconde branche injecte le même audio dans YAMNet, un modèle léger d’apprentissage profond initialement entraîné par Google sur une grande variété de sons du quotidien. YAMNet transforme chaque seconde de respiration en une « empreinte » numérique riche qui capture des motifs trop complexes pour être décrits manuellement. Les chercheurs fusionnent ensuite ces deux vues du son et font passer l’information combinée par des modules supplémentaires qui examinent les motifs à plusieurs échelles et mettent automatiquement en évidence les canaux les plus informatifs avant qu’un classificateur final n’émette le diagnostic.
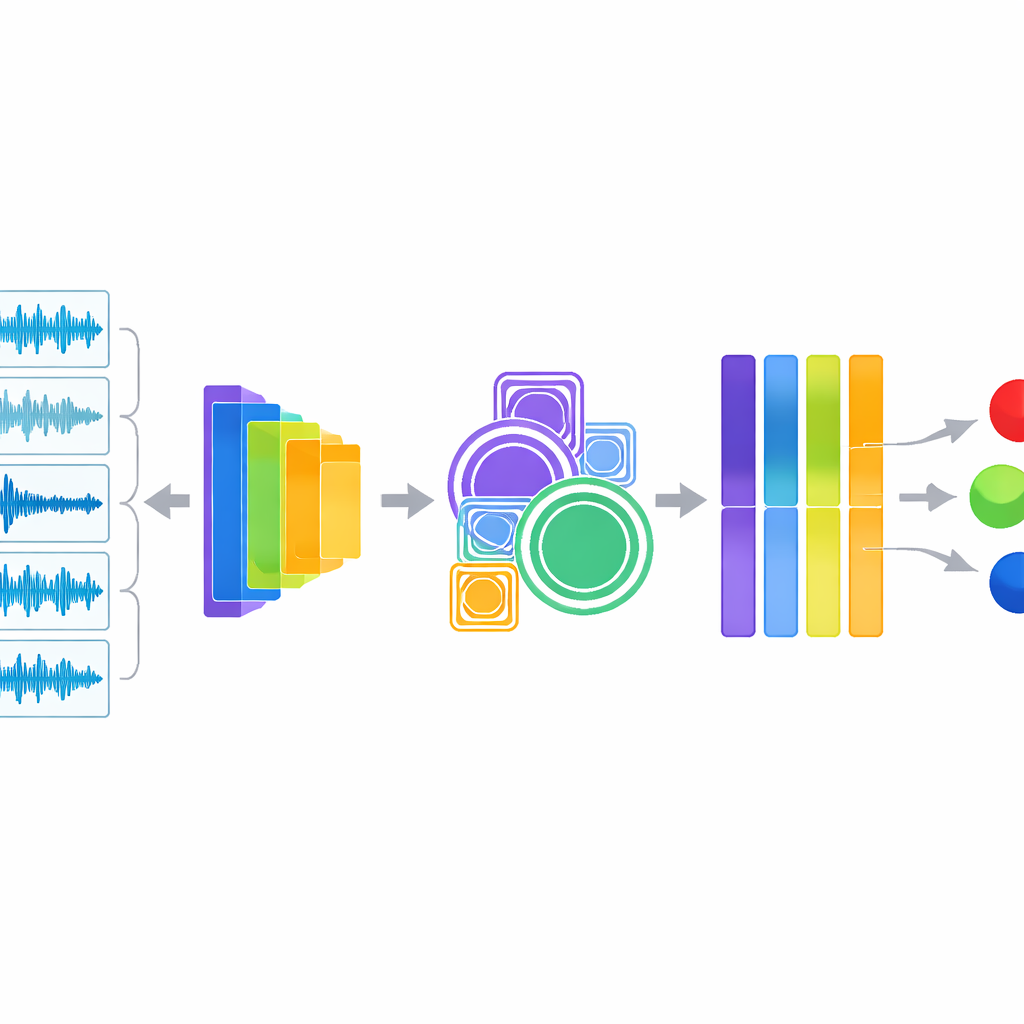
Tester la précision et rendre la boîte noire plus transparente
Pour évaluer les performances de leur système, les auteurs ont utilisé une stratégie de test rigoureuse appelée validation croisée stratifiée en cinq plis, garantissant que chaque condition pulmonaire soit équitablement représentée dans les phases d’entraînement et de test. Le modèle a atteint environ 98,6 % de précision ainsi qu’un score F1 et une aire sous la courbe également élevés, surpassant nettement plusieurs alternatives solides, y compris des modèles d’apprentissage automatique conventionnels, des réseaux convolutionnels standard appliqués à des spectrogrammes, et une version simplifiée utilisant uniquement YAMNet. Surtout, l’équipe ne s’est pas limitée aux chiffres globaux. Elle a utilisé des outils de visualisation pour montrer comment différentes conditions produisent des formes d’onde et des spectrogrammes distincts, et a employé SHAP, une méthode issue de la théorie des jeux, pour mettre en évidence quelles caractéristiques et quelles unités cachées du réseau influencent le plus chaque prédiction. Ces analyses ont révélé que le modèle se concentre sur des indices cliniquement pertinents tels que des bandes de hautes fréquences soutenues et des explosions soudaines correspondant aux sifflements et aux crépitements.
Ce que cela pourrait signifier pour les soins quotidiens
En termes simples, l’étude montre qu’un système d’apprentissage profond bien conçu peut « écouter » la respiration avec une précision proche de celle d’un expert, même lorsque les enregistrements sont réalisés sur des appareils ordinaires dans des environnements bruyants. En associant des caractéristiques audio compréhensibles à des représentations apprises puissantes, et en expliquant ses décisions au moyen de cartes visuelles et de scores d’importance de caractéristiques, le système se rapproche d’un assistant numérique fiable plutôt que d’une boîte noire mystérieuse. Bien qu’il doive encore être testé sur des jeux de données plus nombreux et plus vastes et validé en pratique clinique, cette approche ouvre la voie à des outils futurs pouvant fonctionner sur des téléphones ou du matériel léger, aidant médecins et patients à surveiller l’asthme et les maladies pulmonaires apparentées rapidement, de manière non invasive et à faible coût.
Citation: Shatat, G.A.EL., Moustafa, H.ED., Saraya, M.S. et al. Hybrid deep learning and YAMNet features for asthma diagnosis from respiratory sounds. Sci Rep 16, 13781 (2026). https://doi.org/10.1038/s41598-026-49247-y
Mots-clés: diagnostic de l’asthme, sons respiratoires, apprentissage profond, santé mobile, analyse audio médicale