Clear Sky Science · es
Características híbridas de aprendizaje profundo y YAMNet para el diagnóstico del asma a partir de sonidos respiratorios
Escuchar las respiraciones en lugar de soplar en un tubo
Para millones de personas con asma, obtener un diagnóstico claro a menudo implica acudir a una clínica y realizar pruebas de función pulmonar que pueden resultar agotadoras, consumir mucho tiempo y ser difíciles de repetir con regularidad. Este estudio explora una idea muy distinta: usar el sonido de la respiración y la tos de una persona, grabado con algo tan sencillo como el micrófono de un teléfono o un estetoscopio digital, para determinar si tiene asma u otra enfermedad pulmonar. Al convertir estos sonidos en patrones que una computadora pueda reconocer, los investigadores pretenden construir una herramienta precisa y asequible que algún día podría apoyar revisiones remotas y aplicaciones de salud móvil.
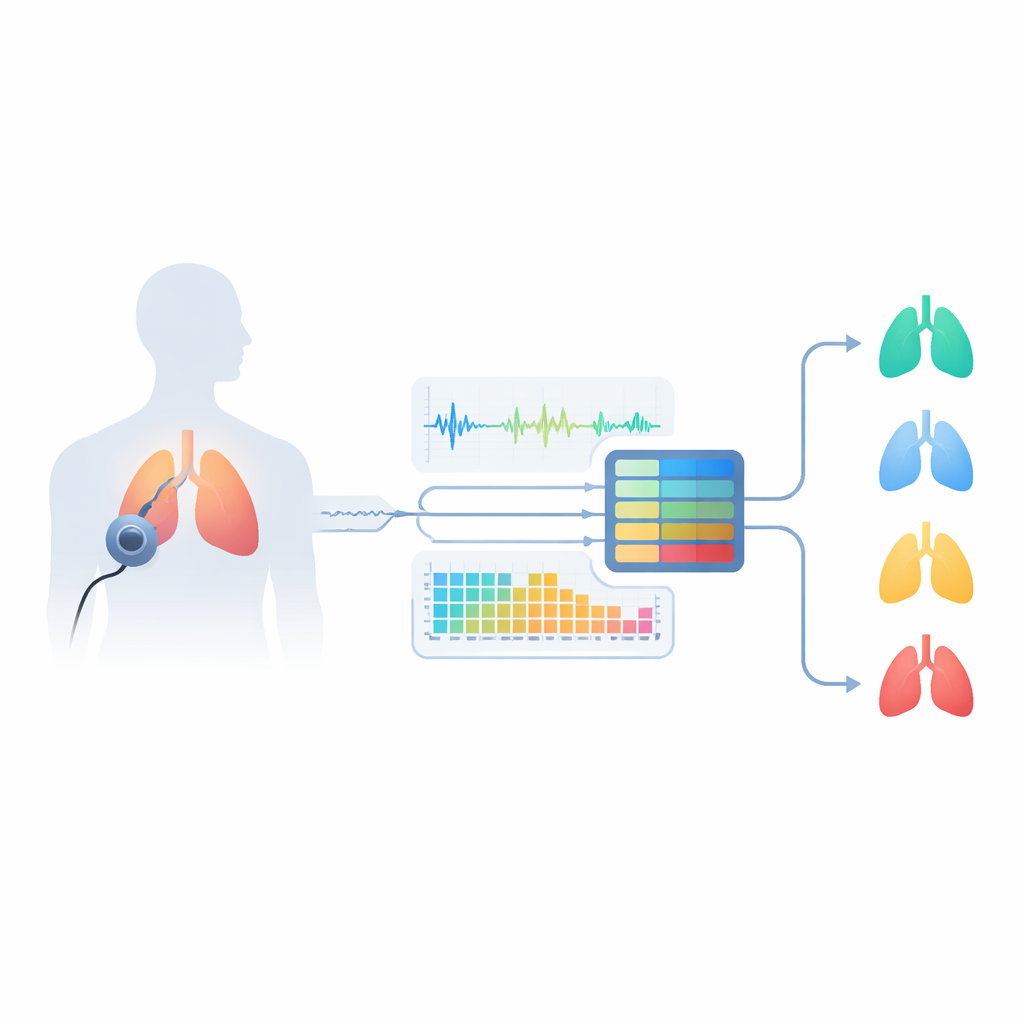
Por qué los sonidos respiratorios ocultan pistas
El asma afecta las vías respiratorias, estrechándolas y haciendo que el flujo de aire sea inestable. Esto produce ruidos característicos como sibilancias (tonos silbantes) y crepitaciones (sonidos cortos de estallido), que los médicos tradicionalmente escuchan con un estetoscopio. Sin embargo, personas con otras enfermedades pulmonares—como la enfermedad pulmonar obstructiva crónica (EPOC), bronquitis o neumonía—pueden generar sonidos similares, lo que complica el diagnóstico incluso para especialistas. Pruebas estándar como la espirometría requieren visitas a la clínica, personal capacitado y equipo especial, y pueden no captar la diversidad completa de los tipos de asma. Los autores sostienen que un análisis cuidadoso de grabaciones de sonidos respiratorios podría capturar estas diferencias sutiles de forma más conveniente y ayudar a distinguir entre varias enfermedades pulmonares así como la respiración sana.
Construyendo un oyente inteligente para sonidos pulmonares
El equipo diseñó un sistema “oyente inteligente” que parte de grabaciones del mundo real procedentes de un conjunto de datos público en Kaggle llamado Asthma Detection Dataset v2. Se trata de clips cortos de tos y respiraciones recogidos con teléfonos móviles en entornos cotidianos, etiquetados como asma, EPOC, neumonía, bronquitis o sano. Dado que las grabaciones varían en duración y calidad, los investigadores las limpian primero: estandarizan el volumen, eliminan silencios largos, filtran frecuencias muy bajas y muy altas, y cortan el audio en fragmentos fijos de seis segundos, lo bastante largos para capturar ciclos respiratorios completos. También crean variaciones realistas—ligero aumento o disminución de velocidad, desplazamiento de tono y adición de ruido de fondo suave—para enseñar al sistema a lidiar con condiciones del mundo real en lugar de solo con grabaciones de laboratorio impecables.
Combinando patrones interpretables y profundos
En el núcleo del sistema hay un enfoque híbrido que escucha de dos maneras a la vez. Una rama extrae descriptores de audio clásicos que ingenieros de sonido y clínicos entienden, tales como cómo se distribuye la energía entre las frecuencias, la rapidez con que la señal cruza por cero y cómo sube y baja la energía sonora a lo largo del tiempo. Estas medidas suelen resaltar sibilancias y crepitaciones. La segunda rama introduce el mismo audio en YAMNet, un modelo compacto de aprendizaje profundo entrenado originalmente por Google con una gran variedad de sonidos cotidianos. YAMNet transforma cada segundo de respiración en una rica “huella” numérica que captura patrones demasiado complejos para describir a mano. Los investigadores fusionan estas dos visiones del sonido y pasan la información combinada por módulos adicionales que examinan patrones a múltiples escalas y enfatizan automáticamente los canales más informativos antes de que un clasificador final emita el diagnóstico.
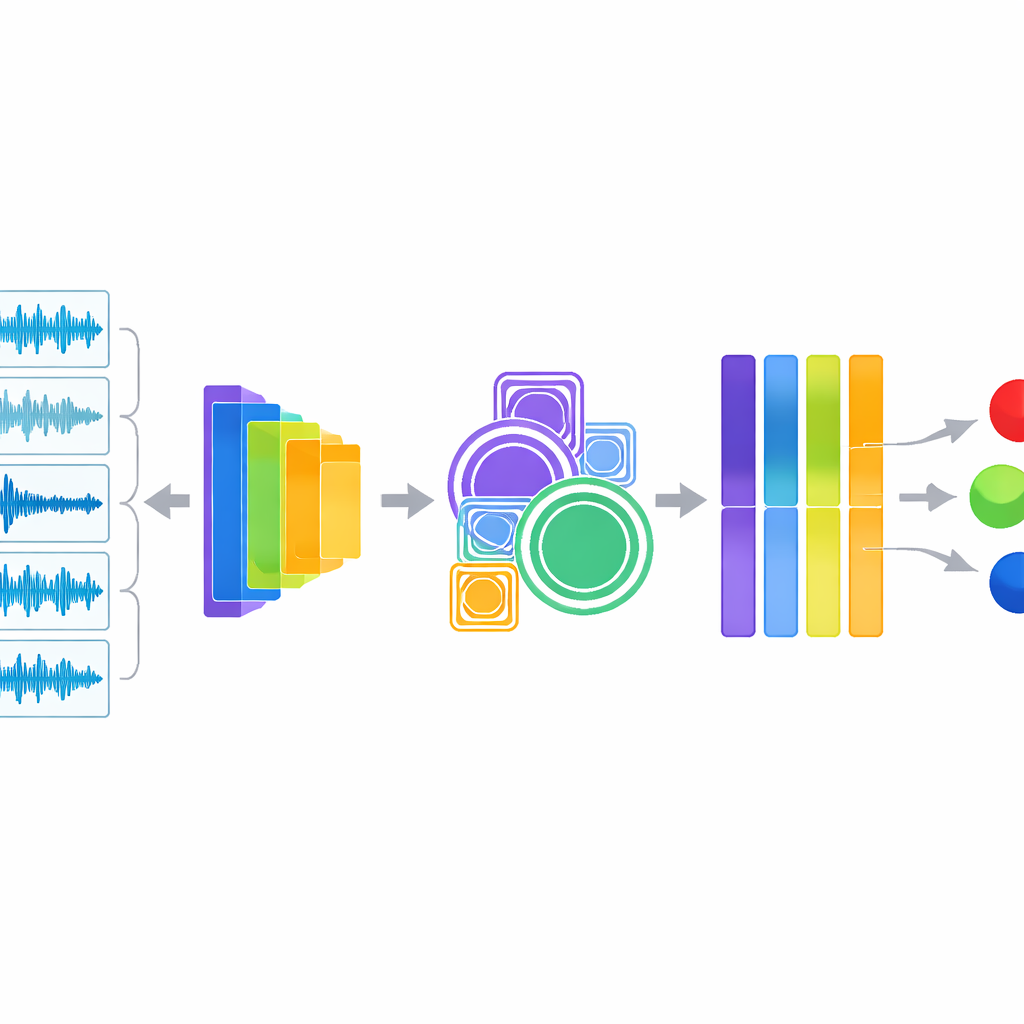
Probar la precisión y hacer transparente la caja negra
Para evaluar el rendimiento de su sistema, los autores emplearon una estrategia de prueba cuidadosa llamada validación cruzada estratificada de cinco particiones, que asegura que cada condición pulmonar esté representada de forma equilibrada en las fases de entrenamiento y prueba. El modelo alcanzó aproximadamente un 98,6 % de precisión y puntuaciones F1 y área bajo la curva igualmente altas, superando con claridad a varias alternativas robustas, incluidas modelos convencionales de aprendizaje automático, redes convolucionales estándar aplicadas a espectrogramas y una versión más sencilla que usaba solo YAMNet. De forma importante, el equipo no se quedó solo en los números principales. Usaron herramientas de visualización para mostrar cómo distintas condiciones producen formas de onda y patrones de espectrograma diferenciables, y emplearon SHAP, un método tomado de la teoría de juegos, para resaltar qué características y unidades ocultas de la red influyen con mayor fuerza en cada predicción. Estos análisis revelaron que el modelo se centra en señales clínicamente relevantes como bandas sostenidas de alta frecuencia y estallidos repentinos que corresponden a sibilancias y crepitaciones.
Qué podría significar esto para la atención cotidiana
En términos sencillos, el estudio demuestra que un sistema de aprendizaje profundo cuidadosamente construido puede “escuchar” la respiración con precisión cercana a la de un experto, incluso cuando las grabaciones se realizan con dispositivos ordinarios en entornos con ruido. Al fusionar características de audio comprensibles con representaciones aprendidas potentes, y al explicar sus decisiones mediante mapas visuales y puntuaciones de importancia de características, el sistema se acerca más a un asistente digital confiable que a una caja negra misteriosa. Aunque aún necesita probarse en conjuntos de datos más amplios y validarse en la práctica clínica, este enfoque apunta a herramientas futuras que podrían ejecutarse en teléfonos o hardware ligero, ayudando a médicos y pacientes a monitorizar el asma y enfermedades pulmonares relacionadas de forma rápida, no invasiva y a bajo coste.
Cita: Shatat, G.A.EL., Moustafa, H.ED., Saraya, M.S. et al. Hybrid deep learning and YAMNet features for asthma diagnosis from respiratory sounds. Sci Rep 16, 13781 (2026). https://doi.org/10.1038/s41598-026-49247-y
Palabras clave: diagnóstico del asma, sonidos respiratorios, aprendizaje profundo, salud móvil, análisis de audio médico