Clear Sky Science · ru
Гибридные признаки глубокого обучения и YAMNet для диагностики астмы по звукам дыхания
Слушая вдохи вместо выдоха в трубку
Для миллионов людей с астмой получение точного диагноза обычно требует визита в клинику и проведения тестов функции легких, которые могут быть утомительными, отнимать много времени и трудно выполняться регулярно. В этом исследовании предлагается совсем иная идея: использовать звук дыхания и кашля, записанный чем‑то простым, например микрофоном телефона или цифровым стетоскопом, чтобы определить, есть ли у человека астма или другое заболевание легких. Превращая эти звуки в шаблоны, которые компьютер может распознавать, исследователи стремятся создать точный и недорогой инструмент, который в будущем мог бы поддерживать удаленные проверки и мобильные приложения для здравоохранения.
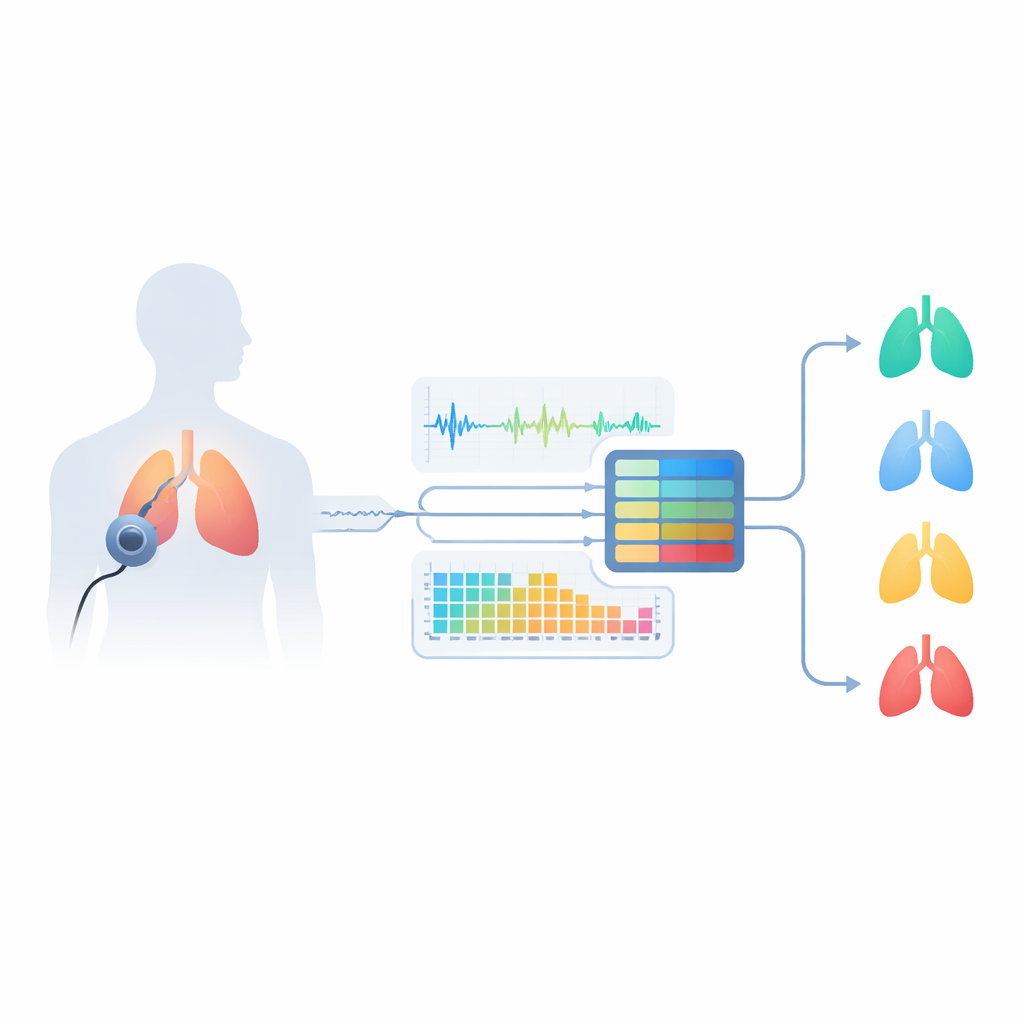
Почему звуки дыхания несут скрытые подсказки
Астма поражает дыхательные пути, сужая их и делая поток воздуха неустойчивым. Это порождает характерные шумы, такие как хрипы (свистящие тона) и крепитации (короткие щелкающие звуки), которые врачи традиционно прослушивают стетоскопом. Однако у людей с другими заболеваниями легких — например хронической обструктивной болезнью легких (ХОБЛ), бронхитом или пневмонией — могут появляться похожие звуки, что делает диагностику сложной даже для специалистов. Стандартные тесты, такие как спирометрия, требуют посещения клиники, обученного персонала и специального оборудования и могут не охватывать все варианты астмы. Авторы утверждают, что тщательный анализ записанных звуков дыхания способен зафиксировать эти тонкие различия удобнее и помочь различать несколько заболеваний легких, а также нормальное дыхание.
Создание «умного слушателя» для звуков легких
Команда разработала систему «умного слушателя», которая начинается с реальных записей из общедоступного набора данных на Kaggle под названием Asthma Detection Dataset v2. Это короткие фрагменты кашлей и дыхания, собранные обычными мобильными телефонами в повседневной обстановке и размеченные как астма, ХОБЛ, пневмония, бронхит или здоровое дыхание. Поскольку записи отличаются по длине и качеству, исследователи сначала их очищают: стандартизируют громкость, убирают долгие паузы, фильтруют очень низкие и очень высокие частоты и нарезают аудио на фиксированные шестисекундные куски, достаточно длинные, чтобы охватить полные циклы дыхания. Они также создают реалистичные вариации — слегка ускоряют или замедляют звук, сдвигают высоту тона и добавляют легкий фоновый шум — чтобы обучить систему справляться с шумными, реальными условиями, а не только с идеальными лабораторными записями.
Сочетание понятных и глубоких признаков
В основе системы лежит гибридный подход, который «слушает» двумя способами одновременно. Одна ветвь извлекает классические аудио‑дескрипторы, понятные звукоинженерам и клиницистам, такие как распределение энергии по частотам, скорость пересечения нулевой линии и динамика изменения звуковой энергии во времени. Эти показатели хорошо выявляют хрипы и крепитации. Вторая ветвь подаёт то же аудио в YAMNet — компактную модель глубокого обучения, изначально обученную Google на большом наборе повседневных звуков. YAMNet преобразует каждую секунду дыхания в богатый числовой «отпечаток», фиксирующий шаблоны, слишком сложные для ручного описания. Затем исследователи объединяют эти два представления звука и пропускают полученную информацию через дополнительные модули, которые анализируют паттерны на нескольких масштабах и автоматически выделяют наиболее информативные каналы перед финальным классификатором, выносящим диагноз.
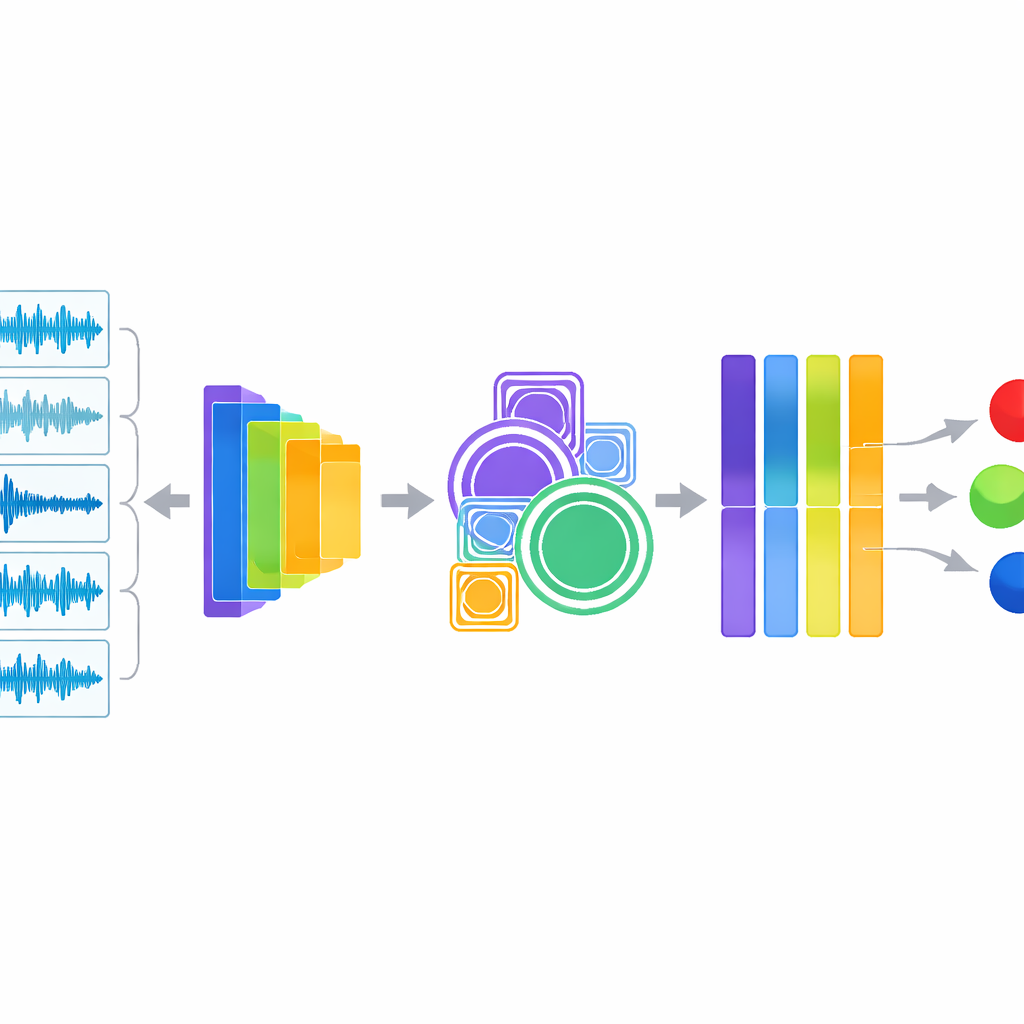
Тестирование точности и прозрачность «чёрного ящика»
Чтобы оценить эффективность системы, авторы использовали тщательную стратегию тестирования — стратифицированную пятикратную кросс‑валидацию, обеспечивающую справедливое представление каждого состояния легких в тренировочных и тестовых наборах. Модель достигла примерно 98,6% точности, а также сопоставимых значений F1‑метрики и площади под кривой, существенно превзойдя несколько сильных альтернатив, включая классические алгоритмы машинного обучения, стандартные сверточные сети на спектрограммах и более простую версию, использующую только YAMNet. Важно, что команда не ограничилась только сводными цифрами. Они применили визуализационные инструменты, чтобы показать, как разные состояния дают отличающиеся волновые формы и спектрограммы, и использовали SHAP — метод, заимствованный из теории игр, — чтобы выделить, какие признаки и скрытые единицы в сети наиболее сильно влияют на каждое предсказание. Эти анализы показали, что модель фокусируется на клинически значимых сигналах, таких как устойчивые высокочастотные полосы и внезапные всплески, соответствующие хрипам и крепитациям.
Что это может значить для повседневной помощи
Проще говоря, исследование показывает, что тщательно построенная система глубокого обучения может «слушать» дыхание с точностью, близкой к экспертной, даже когда записи сделаны обычными устройствами в шумных условиях. Сочетая понятные аудио‑признаки с мощными изученными представлениями и объясняя свои решения с помощью визуальных карт и оценок важности признаков, система приближается к роли надежного цифрового помощника, а не мистического «чёрного ящика». Хотя ей еще предстоит пройти проверку на больших и разнообразных наборах данных и клиническую валидацию, этот подход указывает путь к будущим инструментам, которые смогут работать на телефонах или лёгком оборудовании, помогая врачам и пациентам быстро, неинвазивно и с низкой стоимостью контролировать астму и связанные заболевания легких.
Цитирование: Shatat, G.A.EL., Moustafa, H.ED., Saraya, M.S. et al. Hybrid deep learning and YAMNet features for asthma diagnosis from respiratory sounds. Sci Rep 16, 13781 (2026). https://doi.org/10.1038/s41598-026-49247-y
Ключевые слова: диагностика астмы, звуки дыхания, глубокое обучение, мобильное здравоохранение, анализ медицинского аудио