Clear Sky Science · en
Hybrid deep learning and YAMNet features for asthma diagnosis from respiratory sounds
Listening to Breaths Instead of Blowing Into a Tube
For millions of people with asthma, getting a clear diagnosis often means visiting a clinic and performing lung function tests that can be tiring, time‑consuming, and hard to repeat regularly. This study explores a very different idea: using the sound of someone’s breathing and coughing, recorded with something as simple as a phone microphone or digital stethoscope, to tell whether they have asthma or another lung condition. By turning these sounds into patterns a computer can recognize, the researchers aim to build an accurate, affordable tool that could one day support remote check‑ups and mobile health apps.
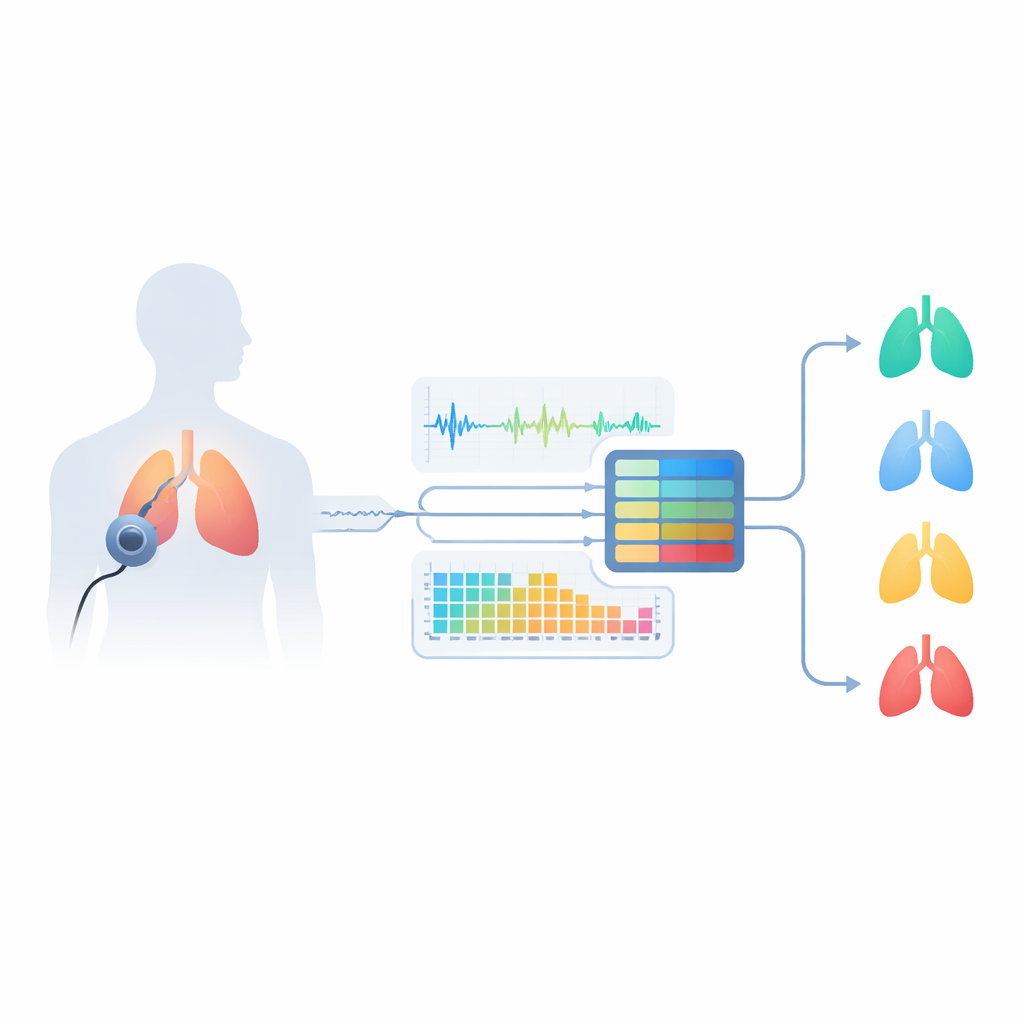
Why Breathing Sounds Carry Hidden Clues
Asthma affects the airways, narrowing them and making air flow unsteady. This produces telltale noises such as wheezes (whistling tones) and crackles (short popping sounds), which doctors traditionally listen for with a stethoscope. However, people with other lung diseases—like chronic obstructive pulmonary disease (COPD), bronchitis, or pneumonia—can produce similar sounds, making diagnosis tricky even for specialists. Standard tests like spirometry require clinic visits, trained staff, and special equipment, and they may miss the full variety of asthma types. The authors argue that carefully analyzing recorded respiratory sounds could capture these subtle differences more conveniently and could help distinguish among several lung diseases as well as healthy breathing.
Building a Smart Listener for Lung Sounds
The team designed a “smart listener” system that starts with real‑world recordings from a public Kaggle dataset called Asthma Detection Dataset v2. These are short clips of coughs and breathing collected with regular mobile phones in everyday environments, labeled as asthma, COPD, pneumonia, bronchitis, or healthy. Because the recordings vary in length and quality, the researchers first clean them: they standardize volume, remove long silences, filter out very low and very high frequencies, and cut the audio into fixed six‑second chunks long enough to capture full breathing cycles. They also create realistic variations—slightly speeding up or slowing down the sound, shifting pitch, and adding gentle background noise—to teach the system to cope with messy, real‑world conditions rather than only pristine lab recordings.
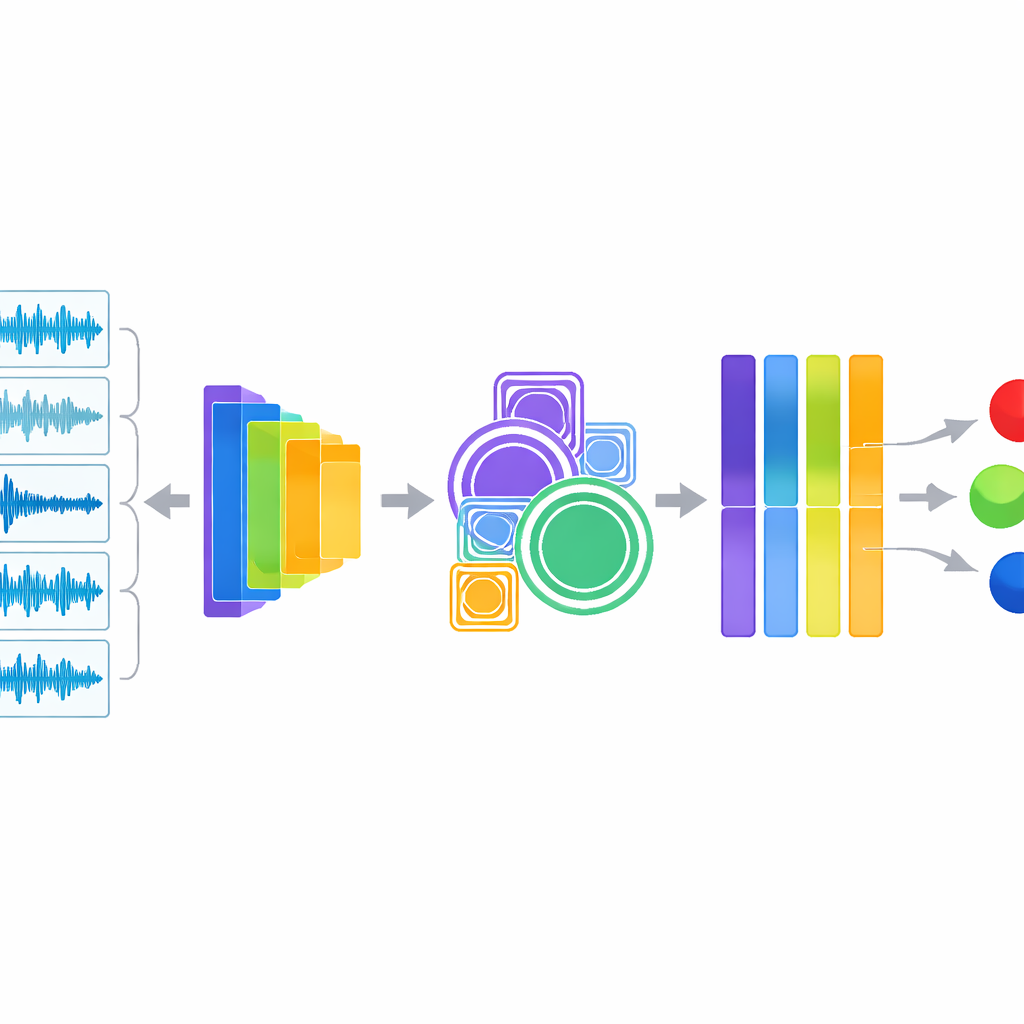
Combining Human‑Readable and Deep Patterns
At the heart of the system is a hybrid approach that listens in two ways at once. One branch extracts classic audio descriptors that audio engineers and clinicians understand, such as how energy is spread across pitches, how quickly the signal crosses zero, and how sound energy rises and falls over time. These measures are known to highlight wheezes and crackles. The second branch feeds the same audio into YAMNet, a compact deep learning model originally trained by Google on a huge variety of everyday sounds. YAMNet transforms each second of breathing into a rich numerical “fingerprint” that captures patterns too complex to describe by hand. The researchers then fuse these two views of the sound and pass the combined information through additional modules that zoom in on patterns at multiple scales and automatically emphasize the most informative channels before a final classifier makes the diagnosis.
Testing Accuracy and Making the Black Box Transparent
To see how well their system works, the authors used a careful testing strategy called stratified five‑fold cross‑validation, ensuring that each lung condition is fairly represented in training and testing phases. The model reached about 98.6% accuracy and a similarly high F1‑score and area under the curve, clearly outperforming several strong alternatives, including conventional machine‑learning models, standard convolutional networks on spectrogram images, and a simpler version using YAMNet alone. Importantly, the team did not stop at headline numbers. They used visualization tools to show how different conditions produce distinct waveforms and spectrogram patterns, and employed SHAP, a method borrowed from game theory, to highlight which features and hidden units in the network most strongly influence each prediction. These analyses revealed that the model focuses on clinically meaningful cues such as sustained high‑frequency bands and sudden bursts that correspond to wheezes and crackles.
What This Could Mean for Everyday Care
In plain terms, the study shows that a carefully built deep learning system can “listen” to breathing with near‑expert accuracy, even when recordings are made on ordinary devices in noisy environments. By blending understandable audio features with powerful learned representations, and by explaining its decisions through visual maps and feature importance scores, the system moves closer to a trustworthy digital assistant rather than a mysterious black box. While it still needs to be tested on more and larger datasets and validated in clinical practice, this approach points toward future tools that could run on phones or light‑weight hardware, helping doctors and patients monitor asthma and related lung diseases quickly, non‑invasively, and at low cost.
Citation: Shatat, G.A.EL., Moustafa, H.ED., Saraya, M.S. et al. Hybrid deep learning and YAMNet features for asthma diagnosis from respiratory sounds. Sci Rep 16, 13781 (2026). https://doi.org/10.1038/s41598-026-49247-y
Keywords: asthma diagnosis, respiratory sounds, deep learning, mobile health, medical audio analysis