Clear Sky Science · pt
Recursos híbridos de deep learning e YAMNet para diagnóstico de asma a partir de sons respiratórios
Ouvindo a respiração em vez de soprar em um tubo
Para milhões de pessoas com asma, obter um diagnóstico claro frequentemente significa ir a uma clínica e realizar testes de função pulmonar que podem ser cansativos, demorados e difíceis de repetir com regularidade. Este estudo explora uma ideia muito diferente: usar o som da respiração e da tosse de alguém, gravado com algo tão simples quanto o microfone de um celular ou um estetoscópio digital, para identificar se a pessoa tem asma ou outra condição pulmonar. Ao transformar esses sons em padrões que um computador pode reconhecer, os pesquisadores pretendem construir uma ferramenta precisa e acessível que, um dia, possa apoiar consultas remotas e aplicativos de saúde móvel.
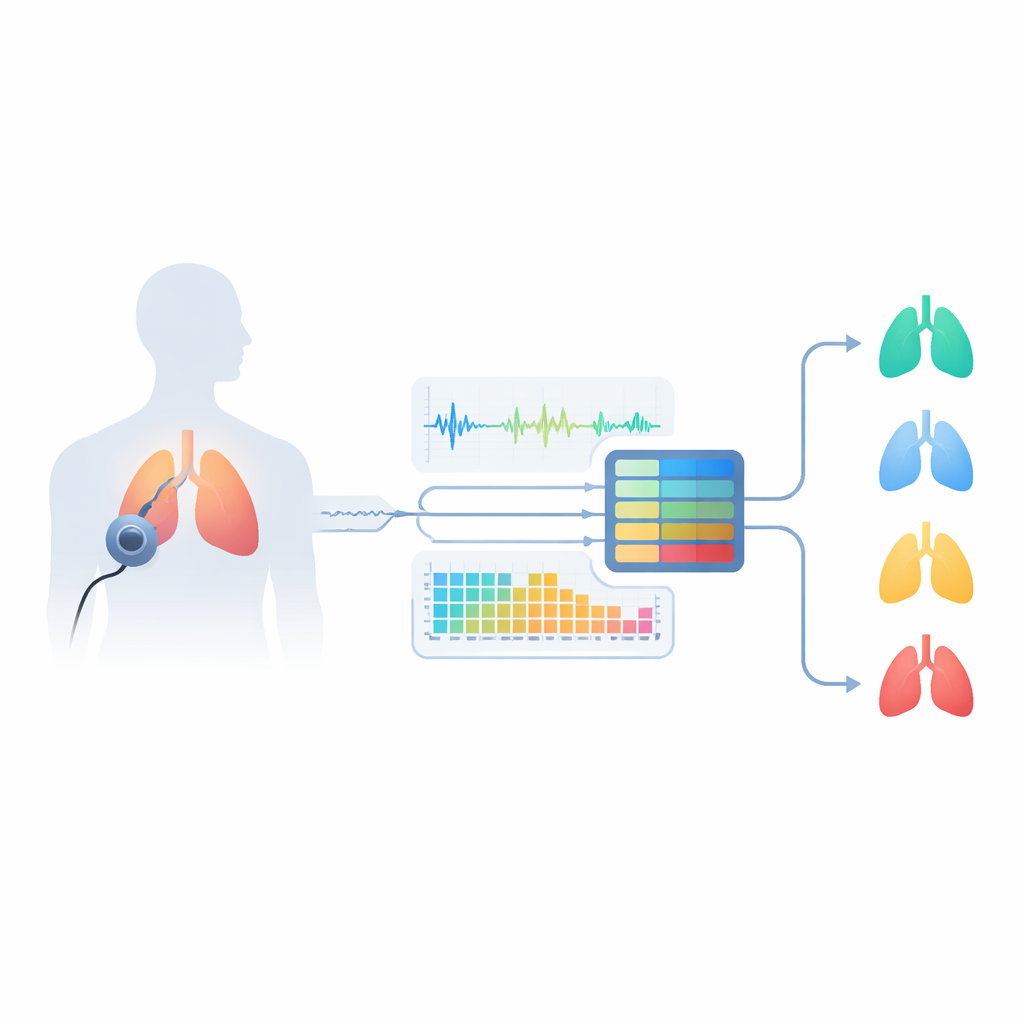
Por que os sons respiratórios carregam pistas ocultas
A asma afeta as vias aéreas, estreitando‑as e tornando o fluxo de ar instável. Isso produz ruídos característicos, como sibilos (tons assobiantes) e crepitações (sons curtos estalantes), que os médicos tradicionalmente escutam com um estetoscópio. Porém, pessoas com outras doenças pulmonares — como doença pulmonar obstrutiva crônica (DPOC), bronquite ou pneumonia — podem produzir sons semelhantes, tornando o diagnóstico difícil mesmo para especialistas. Testes padrão como a espirometria exigem visitas à clínica, pessoal treinado e equipamentos especiais, e podem não captar toda a variedade de tipos de asma. Os autores argumentam que analisar cuidadosamente sons respiratórios gravados pode captar essas diferenças sutis de forma mais conveniente e ajudar a distinguir entre várias doenças pulmonares, além da respiração saudável.
Construindo um ouvinte inteligente para sons pulmonares
A equipe projetou um sistema “ouvinte inteligente” que começa com gravações do mundo real de um conjunto de dados público no Kaggle chamado Asthma Detection Dataset v2. São clipes curtos de tosse e respiração coletados com celulares comuns em ambientes cotidianos, rotulados como asma, DPOC, pneumonia, bronquite ou saudável. Como as gravações variam em duração e qualidade, os pesquisadores as limpam primeiro: padronizam o volume, removem silêncios longos, filtram frequências muito baixas e muito altas e cortam o áudio em pedaços fixos de seis segundos suficientemente longos para captar ciclos respiratórios completos. Eles também geram variações realistas — acelerando ou desacelerando ligeiramente o som, deslocando o tom e adicionando ruído de fundo suave — para ensinar o sistema a lidar com condições do mundo real, em vez de apenas gravações impecáveis de laboratório.
Combinando padrões interpretáveis e de deep learning
No núcleo do sistema está uma abordagem híbrida que escuta de duas maneiras ao mesmo tempo. Um ramo extrai descritores clássicos de áudio que engenheiros e clínicos entendem, como a distribuição de energia entre as frequências, a rapidez com que o sinal cruza o zero e como a energia sonora sobe e cai ao longo do tempo. Essas medidas são conhecidas por realçar sibilos e crepitações. O segundo ramo envia o mesmo áudio para o YAMNet, um modelo compacto de deep learning originalmente treinado pelo Google em uma grande variedade de sons cotidianos. O YAMNet transforma cada segundo de respiração em uma rica “impressão digital” numérica que captura padrões complexos demais para serem descritos manualmente. Os pesquisadores então fundem essas duas visões do som e passam a informação combinada por módulos adicionais que identificam padrões em múltiplas escalas e enfatizam automaticamente os canais mais informativos antes que um classificador final faça o diagnóstico.
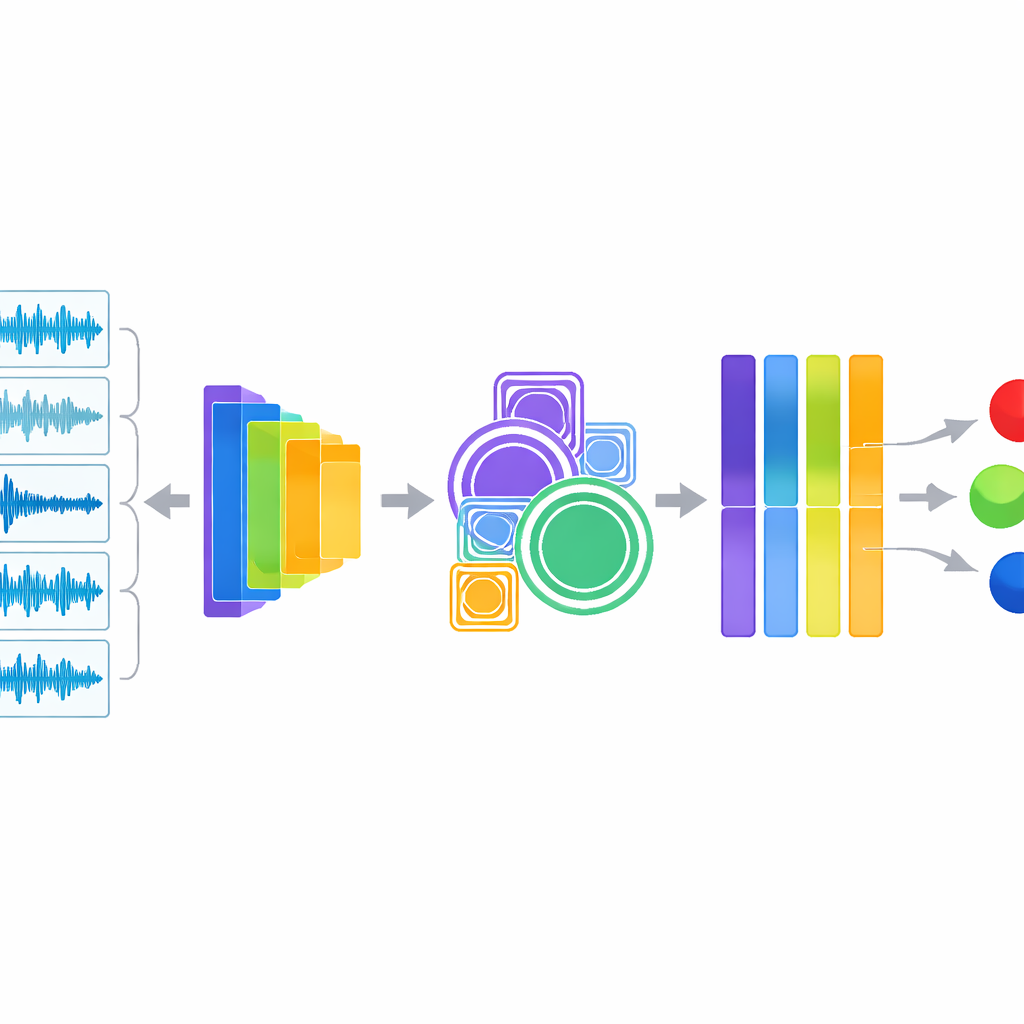
Testando a acurácia e tornando a caixa‑preta mais transparente
Para avaliar o desempenho do sistema, os autores usaram uma estratégia cuidadosa de testes chamada validação cruzada estratificada em cinco blocos, garantindo que cada condição pulmonar esteja bem representada nas fases de treinamento e teste. O modelo alcançou cerca de 98,6% de acurácia e pontuações F1 e área sob a curva igualmente altas, superando claramente várias alternativas fortes, incluindo modelos tradicionais de aprendizado de máquina, redes convolucionais padrão em imagens de espectrograma e uma versão mais simples usando apenas o YAMNet. Importante, a equipe não se limitou aos números de manchete. Eles usaram ferramentas de visualização para mostrar como diferentes condições produzem formas de onda e padrões de espectrograma distintos, e empregaram SHAP, um método emprestado da teoria dos jogos, para destacar quais características e unidades ocultas na rede influenciam mais cada previsão. Essas análises revelaram que o modelo foca em pistas clinicamente significativas, como bandas sustentadas de alta frequência e explosões súbitas que correspondem a sibilos e crepitações.
O que isso pode significar para o cuidado cotidiano
Em termos simples, o estudo mostra que um sistema de deep learning cuidadosamente construído pode “ouvir” a respiração com precisão próxima à de especialistas, mesmo quando as gravações são feitas em dispositivos comuns em ambientes ruidosos. Ao combinar características de áudio compreensíveis com representações poderosas aprendidas e ao explicar suas decisões por meio de mapas visuais e escores de importância de características, o sistema se aproxima de um assistente digital confiável em vez de uma caixa‑preta misteriosa. Embora ainda precise ser testado em conjuntos de dados maiores e mais variados e validado na prática clínica, essa abordagem aponta para ferramentas futuras que poderiam rodar em celulares ou hardware leve, ajudando médicos e pacientes a monitorar asma e doenças pulmonares relacionadas de forma rápida, não invasiva e de baixo custo.
Citação: Shatat, G.A.EL., Moustafa, H.ED., Saraya, M.S. et al. Hybrid deep learning and YAMNet features for asthma diagnosis from respiratory sounds. Sci Rep 16, 13781 (2026). https://doi.org/10.1038/s41598-026-49247-y
Palavras-chave: diagnóstico de asma, sons respiratórios, deep learning, saúde móvel, análise de áudio médico