Clear Sky Science · zh
基于深度学习的钓鱼网站分类框架:利用优化的 URL 智能实现精准检测
为什么伪造的网页链接日益成问题
我们每天在电子邮件、消息和搜索结果中点击链接,往往不会多想。然而,其中一些链接背后可能是精心设计的陷阱,旨在窃取密码、银行信息或其他隐私数据。攻击者不断改变伪造网页地址的外观,这让基于黑名单等传统防御手段难以追赶。本文提出了一种新的自动化、实时识别危险链接的方法,旨在为网页用户和组织提供更强的反诈骗防护。
网络骗术如何伪装得惟妙惟肖
现代钓鱼攻击很少依赖明显的拼写错误或粗糙的银行网站仿制品。相反,它们采用短链、快速更换域名或看起来安全的前缀等手法以显得可信。许多现有检测工具依赖固定规则或已知恶意站点列表,这些方法能应对过往的诈骗,但常常漏掉新出现的“零日”攻击,并可能错误标记不常见但无害的网站。作者认为,网络变动太快,单靠人工制定的规则已不足够,防御需要从数据中直接学习模式。
教系统“读懂”网址
论文提出了一种名为自适应深度 URL 智能网络(Adaptive Deep URL Intelligence Network,简称 ADUIN)的方法,将每个网址视为丰富的线索来源。系统不下载完整页面,而是关注三类信息。它分析链接文本本身,如长度、字符组合和可疑词汇;检查主机相关信息,包括域名存在时间和 IP 是否有不良声誉;并研究链接结构,例如子域和目录数量以及重定向频率。这些要素被数值化并合成为每个 URL 的紧凑描述。
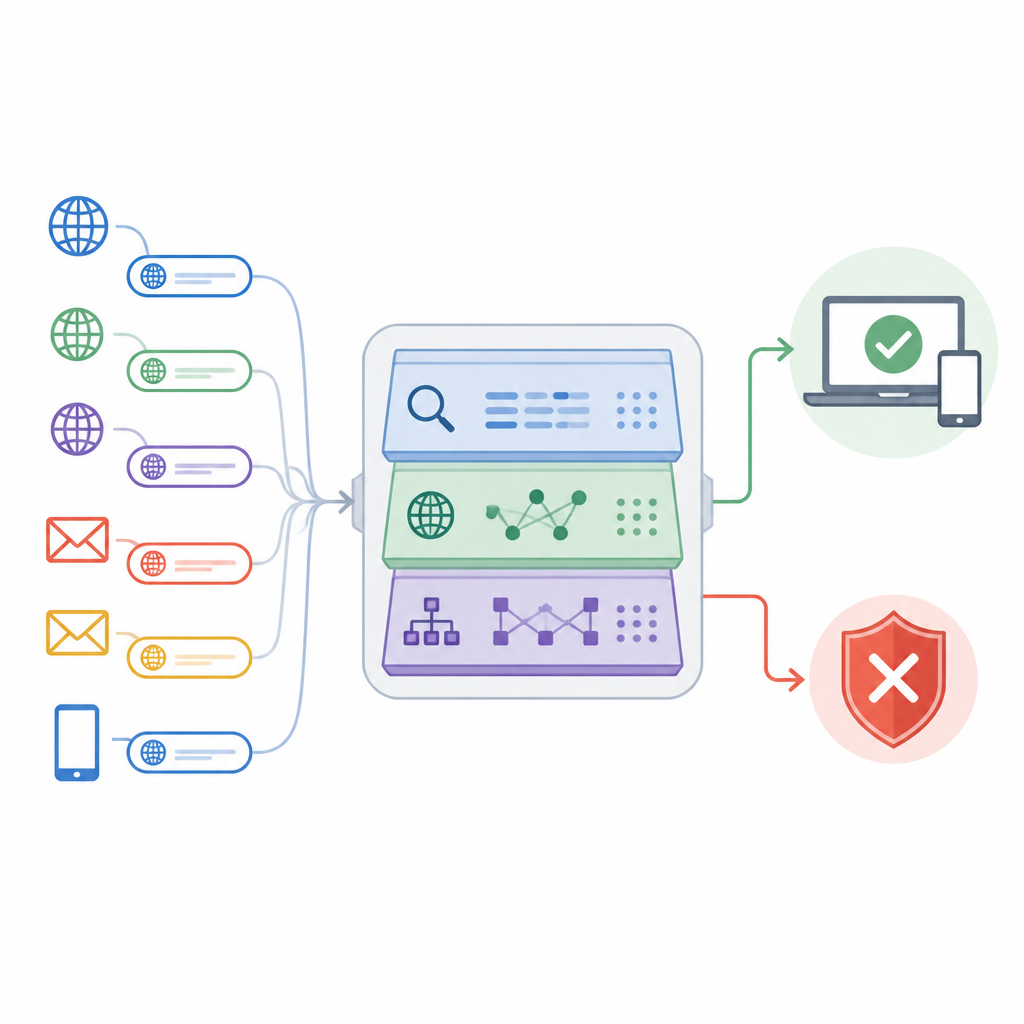
挑选最具判别力的线索
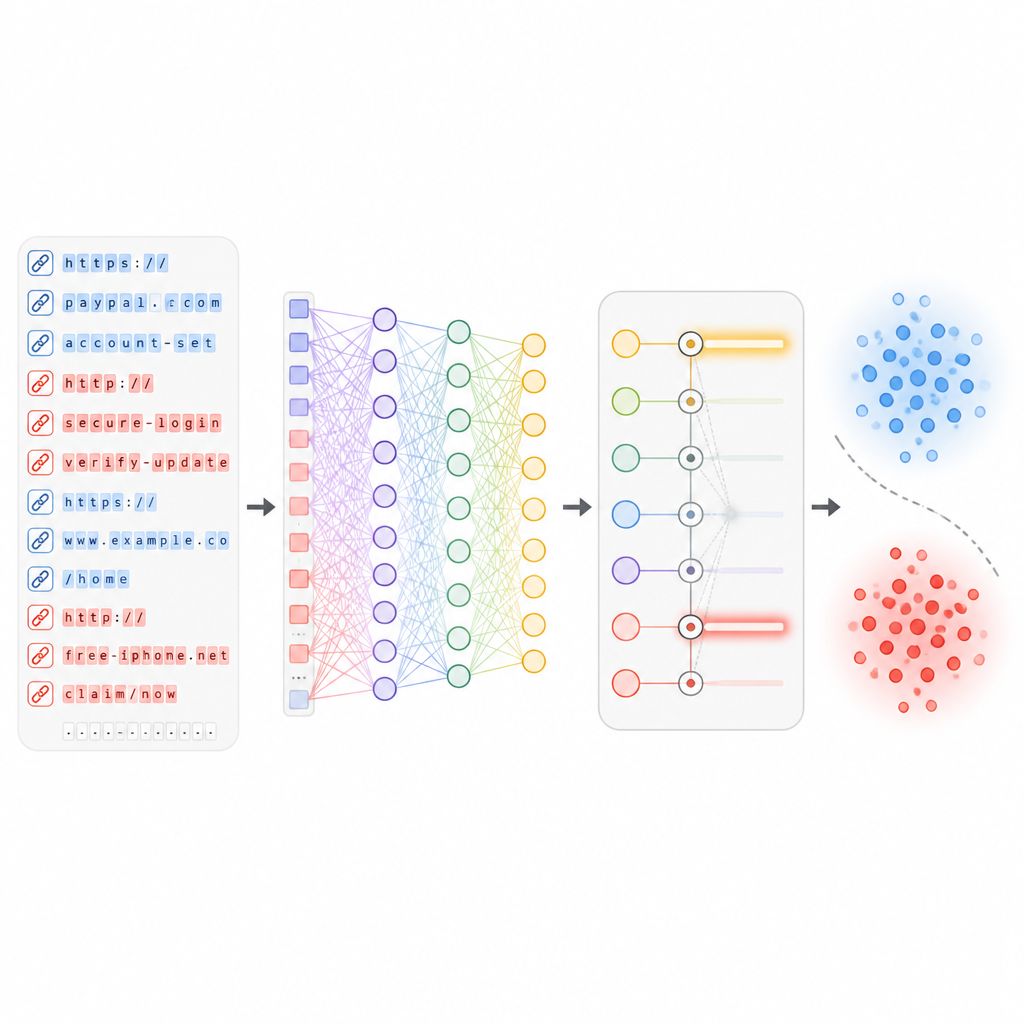
收集大量信号有可能让系统被噪声淹没。为避免这一点,研究人员设计了特征选择步骤,对每个线索按其将安全与不安全链接区分开的能力进行排序。统计检验会剔除那些主要重复其他测量的特征,而基于学习的评分则突出显示那些在存在时能显著降低错误率的特征。从原始的大量特征中,系统保留大约 50 个最具信息量的特征。这一精简加快了检测速度,降低了对训练数据偶发现象的过拟合风险,同时保留了最能区分钓鱼与正常流量的模式。
让深度学习发现隐藏模式
一旦选出最有用的特征,它们会被送入包含若干层虚拟“神经元”与注意力机制的深度神经网络。这些层学习 URL 不同方面之间的复杂关系,例如某些词汇与特定托管历史或路径结构如何组合。在训练过程中,网络会看到数十万条真实与恶意链接,并逐步调整内部权重以最小化错误。重要的是,该系统设计为可随新一批 URL 的到来而更新,因此它能在不用从头重建的情况下适应新的攻击手法。
这种新防护的表现如何
作者在一个来自多个来源、跨时段的大型公开钓鱼与正常 URL 集合上测试了 ADUIN。他们按时间拆分数据,使训练时未见过的最新链接充当真实世界零日攻击的替代。与若干强基线机器学习方法相比,新系统实现了约 95% 的总体准确率,正确识别了约 93% 的标记为钓鱼的链接,并检测出约 92% 的先前未见钓鱼 URL。与此同时,只有约 3.5% 的无害链接被错误标记为危险,且每个 URL 在高负载下大约可在五分之一秒内处理完毕,表明该方法适用于高流量网关和企业网络。
这对日常浏览意味着什么
对非专业读者而言,关键是:仔细观察 URL 的构成能揭示其意图。通过结合来自链接文本、主机与结构的多个小线索,并允许学习系统持续自适应,所提出的框架能捕捉既有的诈骗模式与从未出现在任何黑名单上的新型骗局。虽不能单独完全解决钓鱼问题,ADUIN 展示了对 URL 进行更智能、更快速分析如何成为保护电子邮件用户、在线购物者和组织免于泄露机密信息的重要一层防线。
引用: Gobinath, R., Manikandan, S. Deep learning-based phishing classification framework for accurate detection using optimized URL intelligence. Sci Rep 16, 15794 (2026). https://doi.org/10.1038/s41598-026-46481-2
关键词: 钓鱼 URL, 深度学习, 网络安全, URL 分析, 网页安全