Clear Sky Science · de
Tiefenlernendes Phishing-Klassifikations‑Framework zur präzisen Erkennung mithilfe optimierter URL‑Intelligenz
Warum gefälschte Web‑Links ein wachsendes Problem sind
Jeden Tag klicken wir ohne großes Nachdenken auf Links in E‑Mails, Nachrichten und Suchergebnissen. Hinter manchen dieser Links verbergen sich jedoch sorgfältig gestaltete Fallen, die darauf abzielen, Passwörter, Bankdaten oder andere vertrauliche Informationen zu stehlen. Angreifer verändern ständig das Erscheinungsbild dieser falschen Webadressen, weshalb traditionelle Abwehrmechanismen wie Blacklists immer schwerer Schritt halten. Diese Studie stellt einen neuen Ansatz vor, gefährliche Links automatisch und in Echtzeit zu erkennen, mit dem Ziel, Webnutzern und Organisationen einen stärkeren Schutz gegen Online‑Betrug zu bieten.
Wie Online‑Betrüger sich gut tarnen
Moderne Phishing‑Angriffe setzen selten auf offensichtliche Rechtschreibfehler oder plumpe Kopien von Bankenwebseiten. Stattdessen nutzen sie Tricks wie sehr kurze Links, schnell wechselnde Domains und vertrauenswürdig wirkende Präfixe, um glaubwürdig zu erscheinen. Viele vorhandene Erkennungswerkzeuge beruhen auf festen Regeln oder Listen bekannter bösartiger Seiten. Diese helfen bei alten Betrugsformen, übersehen jedoch oft neue, sogenannte Zero‑Day‑Angriffe, und können ungewöhnliche, aber harmlose Seiten fälschlich markieren. Die Autoren argumentieren, dass das Web heute zu schnelllebig ist, um nur auf handgefertigte Regeln zu setzen, und dass Abwehrmechanismen Muster direkt aus den Daten lernen müssen.
Ein System darin schulen, Webadressen „zu lesen”
Das Papier stellt einen Ansatz namens Adaptive Deep URL Intelligence Network, kurz ADUIN, vor, der jede Webadresse als reichhaltige Informationsquelle begreift. Anstatt komplette Seiten herunterzuladen, konzentriert sich das System auf drei Arten von Informationen. Es betrachtet den Text des Links selbst, etwa Länge, Zeichenzusammensetzung und verdächtige Wörter; es untersucht Fakten zum Host der Seite, darunter Alter der Domain und ob die IP‑Adresse einen schlechten Ruf hat; und es analysiert die Struktur des Links, beispielsweise die Anzahl der Subdomains und Verzeichnisse oder wie oft Weiterleitungen erfolgen. Diese Elemente werden in Zahlen überführt und zu einer kompakten Beschreibung jeder URL zusammengeführt.
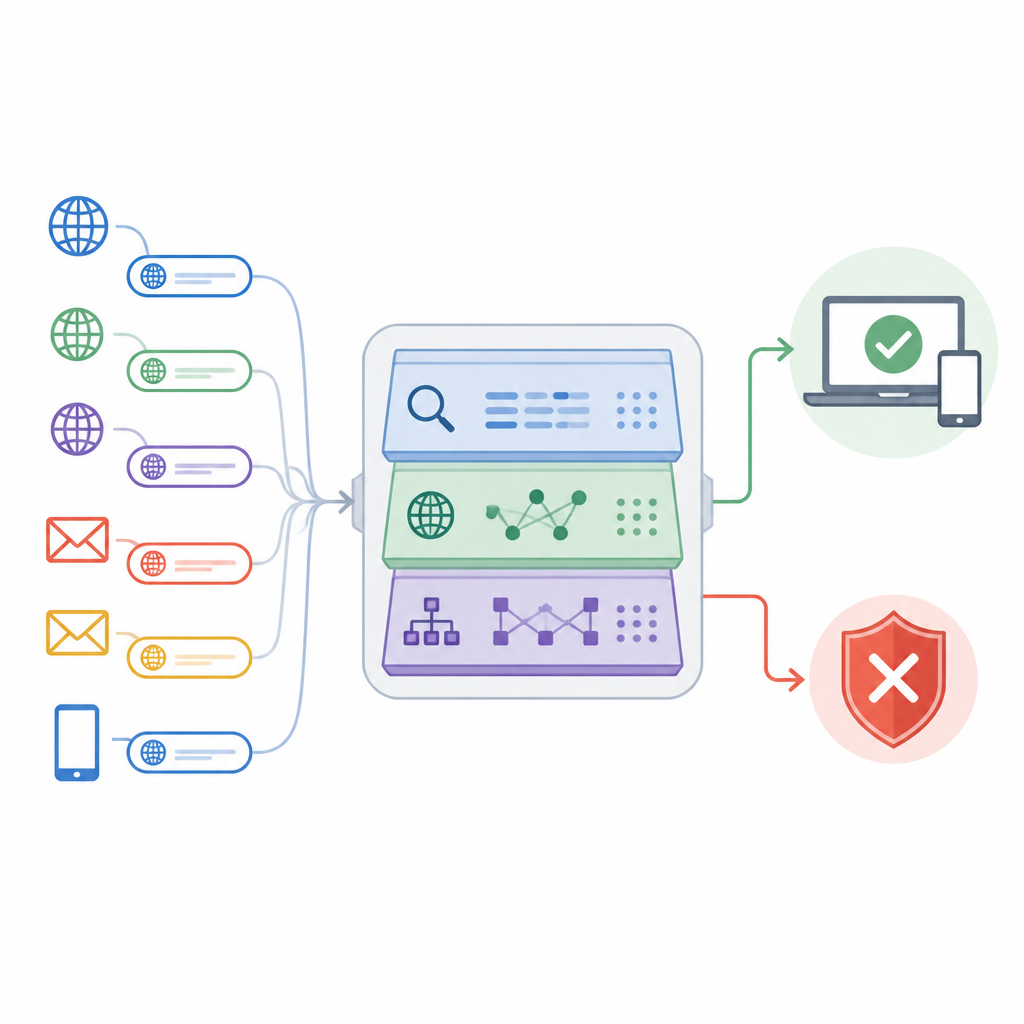
Die aussagekräftigsten Hinweise auswählen
Das Sammeln vieler Signalarten birgt die Gefahr, das System mit Rauschen zu überfluten. Um das zu vermeiden, entwickelten die Forscher einen Merkmalsauswahl‑Schritt, der jeden Hinweis danach bewertet, wie stark er bei der Trennung von sicheren und unsicheren Links hilft. Statistische Tests entfernen Messgrößen, die vor allem andere duplizieren, während lernbasierte Bewertungen jene hervorheben, die bei Vorhandensein Fehler deutlich reduzieren. Aus einem großen ursprünglichen Satz behält das System etwa 50 der informativsten Merkmale. Diese Reduktion beschleunigt die Erkennung, verringert die Gefahr des Overfittings an Eigenheiten der Trainingsdaten und erhält dennoch die Muster, die Phishing‑Versuche am besten von legitimen Zugriffen unterscheiden.
Tiefenlernen verborgene Muster entdecken lassen
Sind die nützlichsten Merkmale gewählt, werden sie in ein tiefes neuronales Netzwerk eingespeist, das mehrere Schichten virtueller „Neuronen“ und einen Aufmerksamkeitsmechanismus enthält. Diese Schichten lernen komplexe Beziehungen zwischen unterschiedlichen Aspekten einer URL, zum Beispiel wie bestimmte Wörter mit einer spezifischen Hosting‑Historie oder Pfadstruktur zusammenspielen. Während des Trainings sieht das Netzwerk Hunderttausende echte und bösartige Links und passt seine internen Gewichte schrittweise an, um Fehler zu minimieren. Wichtig ist, dass das System so ausgelegt ist, dass es mit neuen URL‑Batches aktualisiert werden kann, damit es sich an neue Angriffsarten anpasst, ohne komplett neu aufgebaut werden zu müssen.
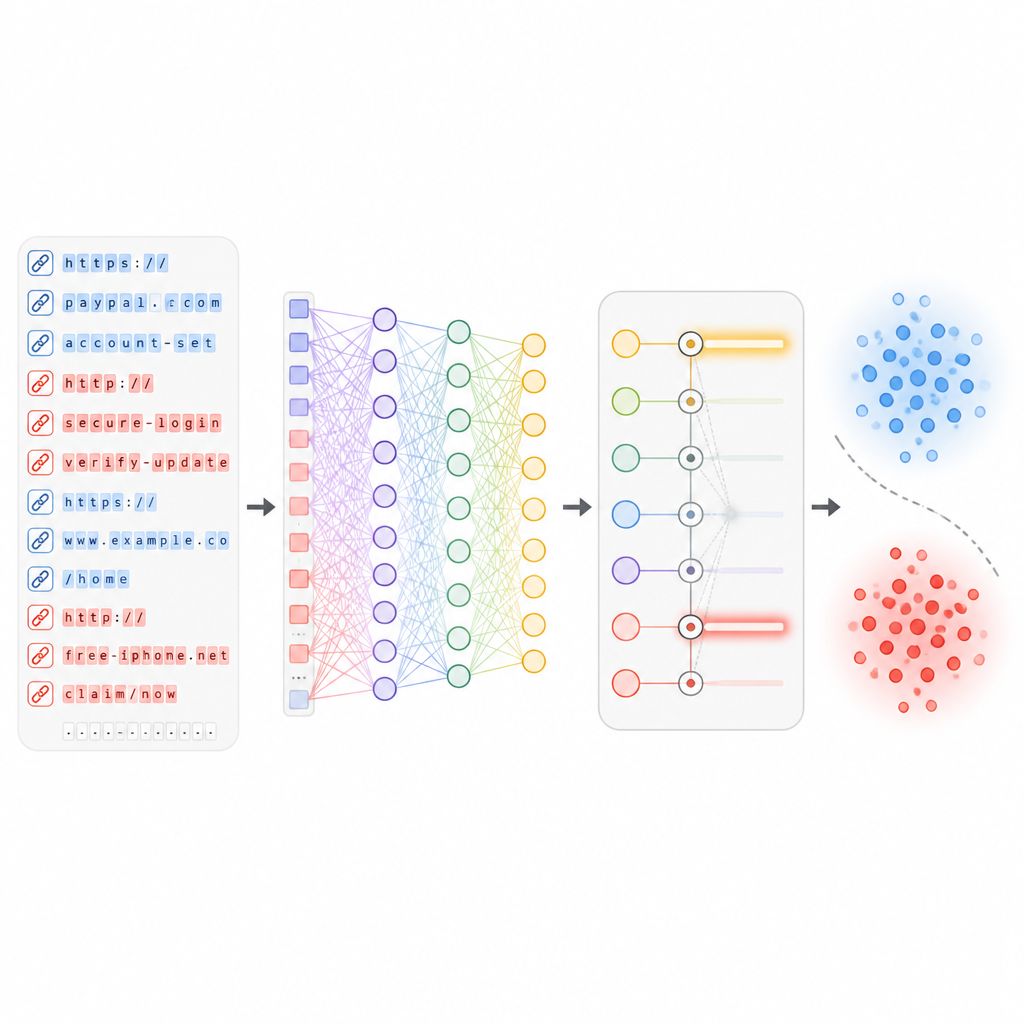
Wie gut der neue Schutz wirkt
Die Autoren testeten ADUIN an einer großen öffentlichen Sammlung von Phishing‑ und legitimen URLs, die über die Zeit aus mehreren Quellen zusammengetragen wurden. Sie teilten die Daten so auf, dass die neuesten Links, die während des Trainings nicht gesehen wurden, als Stellvertreter für reale Zero‑Day‑Angriffe dienten. Im Vergleich zu mehreren starken Machine‑Learning‑Baselines erreichte das neue System eine Gesamtgenauigkeit von etwa 95 %, identifizierte rund 93 % der als Phishing markierten Links korrekt und erkannte etwa 92 % zuvor unbekannter Phishing‑URLs. Gleichzeitig wurden nur etwa 3,5 % harmloser Links fälschlich als gefährlich eingestuft, und jede URL konnte selbst unter hoher Last in ungefähr einem Fünftel einer Sekunde verarbeitet werden, was darauf hindeutet, dass die Methode für stark frequentierte Gateways und Unternehmensnetzwerke geeignet ist.
Was das für das alltägliche Surfen bedeutet
Für Nicht‑Spezialisten ist die zentrale Botschaft, dass eine sorgfältige Betrachtung des Aufbaus einer Webadresse viel über ihre Absichten verraten kann. Durch die Kombination vieler kleiner Hinweise aus Link‑Text, Host und Struktur und durch die Möglichkeit, ein lernendes System kontinuierlich anzupassen, kann das vorgeschlagene Framework sowohl bekannte Betrugsmaschen als auch neue, noch nie auf einer Blacklist erschienene Angriffe erfassen. Es ist zwar keine Allheilmittel gegen Phishing, zeigt jedoch, wie intelligentere und schnellere URL‑Analysen eine wichtige Schutzschicht für E‑Mail‑Nutzer, Online‑Käufer und Organisationen werden können, damit sie nicht dazu verleitet werden, ihre Geheimnisse preiszugeben.
Zitation: Gobinath, R., Manikandan, S. Deep learning-based phishing classification framework for accurate detection using optimized URL intelligence. Sci Rep 16, 15794 (2026). https://doi.org/10.1038/s41598-026-46481-2
Schlüsselwörter: Phishing‑URLs, Tiefenlernen, Cybersicherheit, URL‑Analyse, Web‑Sicherheit