Clear Sky Science · es
Marco de clasificación de phishing basado en aprendizaje profundo para detección precisa mediante inteligencia de URL optimizada
Por qué los enlaces falsos en la web son un problema creciente
Cada día hacemos clic en enlaces de correos, mensajes y resultados de búsqueda sin pensarlo demasiado. Detrás de algunos de esos enlaces, sin embargo, hay trampas cuidadosamente diseñadas para robar contraseñas, datos bancarios u otra información privada. Los atacantes no paran de cambiar el aspecto de estas direcciones web falsas, lo que hace que defensas tradicionales como las listas negras tengan dificultades para seguir el ritmo. Este estudio presenta una nueva forma de detectar enlaces peligrosos de forma automática y en tiempo real, con el objetivo de ofrecer a usuarios y organizaciones una protección más sólida contra las estafas en línea.
Cómo los estafadores en línea se ocultan a simple vista
Los ataques de phishing modernos rara vez dependen de faltas de ortografía evidentes o copias burdas de sitios bancarios. En su lugar, emplean trucos como enlaces muy cortos, dominios que cambian rápidamente y prefijos que parecen seguros para aparentar confianza. Muchas herramientas de detección actuales dependen de reglas fijas o listas de sitios conocidos como maliciosos. Estas pueden funcionar para las estafas de ayer, pero a menudo pasan por alto las nuevas, denominadas ataques zero-day, y pueden señalar por error sitios inusuales pero inocuos. Los autores sostienen que la web se mueve ahora demasiado rápido para depender solo de reglas hechas a mano, y que las defensas deben aprender patrones directamente de los datos.
Enseñar a un sistema a “leer” direcciones web
El artículo presenta un enfoque llamado Adaptive Deep URL Intelligence Network, o ADUIN, que trata cada dirección web como una rica fuente de pistas. En lugar de descargar páginas completas, el sistema se centra en tres tipos de información. Examina el texto del enlace en sí, como su longitud, la mezcla de caracteres y palabras sospechosas; observa hechos sobre el host del sitio, incluido el tiempo de existencia del dominio y si su dirección IP tiene mala reputación; y estudia la estructura del enlace, como cuántos subdominios y carpetas usa o con qué frecuencia redirige. Estas piezas se convierten en números y se combinan en una descripción compacta de cada URL.
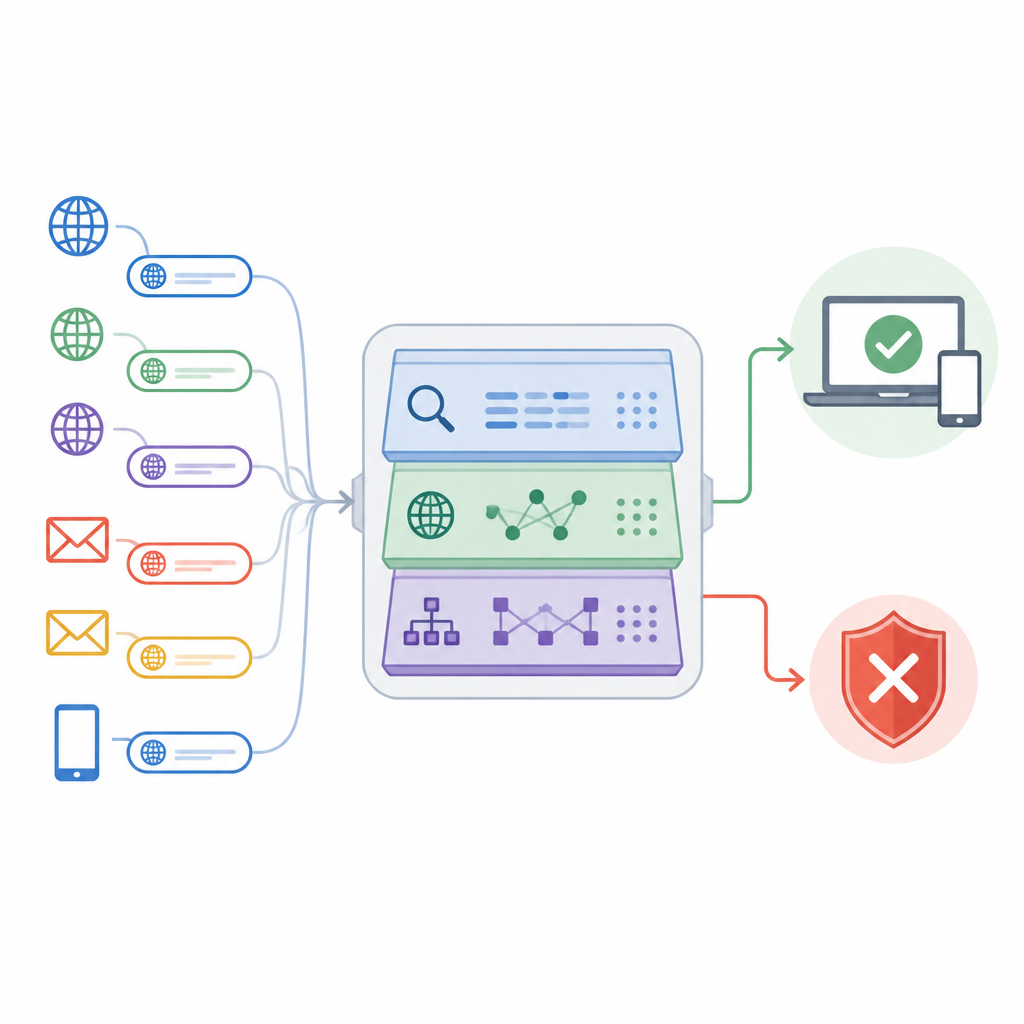
Elegir las pistas más reveladoras
Recopilar muchos tipos de señales corre el riesgo de inundar el sistema con ruido. Para evitarlo, los investigadores crearon un paso de selección de características que clasifica cada pista según la fuerza con la que ayuda a separar enlaces seguros de inseguros. Pruebas estadísticas eliminan mediciones que duplican en su mayoría a otras, mientras que puntuaciones basadas en aprendizaje destacan aquellas que reducen drásticamente los errores cuando están presentes. De un conjunto original amplio, el sistema conserva alrededor de 50 de las características más informativas. Este recorte acelera la detección, reduce la probabilidad de sobreajuste a peculiaridades de los datos de entrenamiento y aun así preserva los patrones que mejor distinguen intentos de phishing del tráfico legítimo.
Permitir que el aprendizaje profundo detecte patrones ocultos
Una vez elegidas las características más útiles, se introducen en una red neuronal profunda que contiene varias capas de “neuronas” virtuales y un mecanismo de atención. Estas capas aprenden relaciones complejas entre diferentes aspectos de una URL, como cómo ciertas palabras se combinan con un historial de alojamiento particular o una estructura de rutas concreta. Durante el entrenamiento, la red ve cientos de miles de enlaces reales y maliciosos y ajusta gradualmente sus pesos internos para minimizar errores. Es importante que el sistema esté diseñado para actualizarse conforme llegan nuevos lotes de URL, de modo que pueda adaptarse a nuevos estilos de ataque sin tener que reconstruirse desde cero.
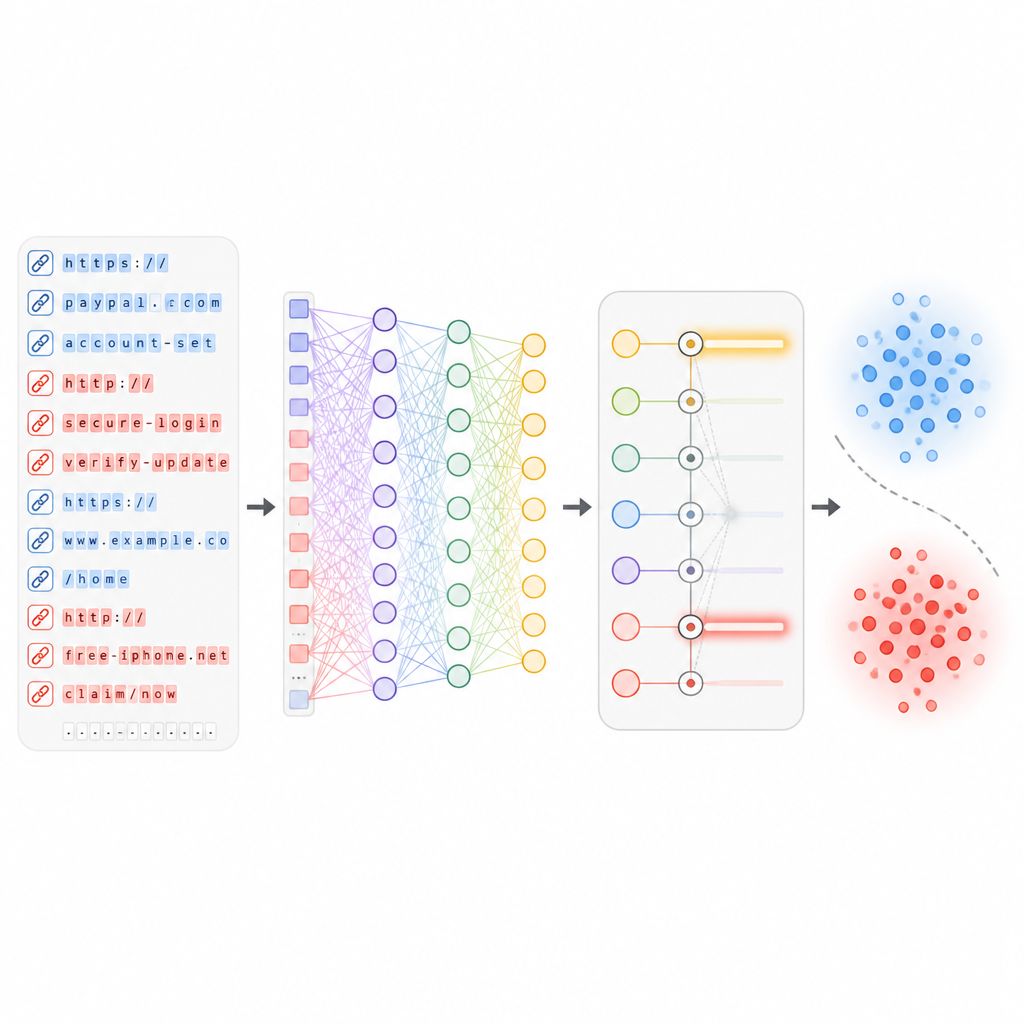
Qué tan bien funciona este nuevo escudo
Los autores probaron ADUIN con una gran colección pública de URLs de phishing y legítimas recopiladas de varias fuentes a lo largo del tiempo. Dividieron los datos de modo que los enlaces más recientes, no vistos durante el entrenamiento, actuaran como sustitutos de ataques zero-day del mundo real. En comparación con varias bases sólidas de aprendizaje automático, el nuevo sistema alcanzó aproximadamente un 95% de precisión global, identificó correctamente alrededor del 93% de los enlaces de phishing detectados y detectó cerca del 92% de las URLs de phishing no vistas con anterioridad. Al mismo tiempo, solo alrededor del 3,5% de los enlaces inofensivos fueron etiquetados por error como peligrosos, y cada URL podía procesarse en aproximadamente una quinta parte de segundo incluso bajo carga elevada, lo que sugiere que el método es adecuado para pasarelas de alto tráfico y redes corporativas.
Qué supone esto para la navegación diaria
Para los no especialistas, el mensaje clave es que observar con atención cómo está construida una dirección web puede revelar mucho sobre sus intenciones. Al combinar muchas pequeñas pistas del texto del enlace, su host y su estructura, y permitiendo que un sistema de aprendizaje se adapte continuamente, el marco propuesto puede atrapar tanto estafas conocidas como nuevas que nunca han aparecido en ninguna lista negra. Si bien no es una cura independiente contra el phishing, ADUIN muestra cómo un análisis de URLs más inteligente y rápido puede convertirse en una capa importante para proteger a usuarios de correo, compradores en línea y organizaciones de ser engañados para entregar sus secretos.
Cita: Gobinath, R., Manikandan, S. Deep learning-based phishing classification framework for accurate detection using optimized URL intelligence. Sci Rep 16, 15794 (2026). https://doi.org/10.1038/s41598-026-46481-2
Palabras clave: URLs de phishing, aprendizaje profundo, ciberseguridad, análisis de URL, seguridad web