Clear Sky Science · nl
Diep-lerende classificatiekader voor phishing voor nauwkeurige detectie met geoptimaliseerde URL-intelligentie
Waarom valse weblinks een groeiend probleem zijn
Elke dag klikken we zonder veel nadenken op links in e‑mails, berichten en zoekresultaten. Achter sommige van die links schuilen echter zorgvuldig samengestelde vallen die zijn ontworpen om wachtwoorden, bankgegevens of andere privégegevens te stelen. Aanvallers blijven veranderen hoe deze valse webadressen eruitzien, waardoor traditionele verdedigingsmiddelen zoals zwarte lijsten moeite hebben om bij te blijven. Deze studie presenteert een nieuwe manier om gevaarlijke links automatisch en in realtime te herkennen, met als doel webgebruikers en organisaties een sterker schild tegen online oplichting te bieden.
Hoe online bedriegers in het volle zicht blijven
Moderne phishingaanvallen vertrouwen zelden op duidelijke spelfouten of grove kopieën van bankwebsites. In plaats daarvan gebruiken ze trucs zoals zeer korte links, snel wisselende domeinen en beveiligend ogende voorvoegsels om betrouwbaar te lijken. Veel bestaande detectietools zijn afhankelijk van vaste regels of lijsten met bekende slechte sites. Die werken voor de scams van gisteren, maar missen vaak nieuwe gevallen, zogenaamde zero‑day‑aanvallen, en kunnen onterecht bijzondere maar onschuldige sites markeren. De auteurs bepleiten dat het web nu te snel verandert voor handgemaakte regels alleen, en dat verdedigingssystemen patronen rechtstreeks uit de data moeten leren.
Een systeem leren ‘lezen’ van webadressen
Het artikel introduceert een benadering genaamd het Adaptive Deep URL Intelligence Network, of ADUIN, dat elk webadres als een rijke bron van aanwijzingen behandelt. In plaats van volledige pagina’s te downloaden, richt het systeem zich op drie soorten informatie. Het kijkt naar de tekst van de link zelf, zoals lengte, tekenmengeling en verdachte woorden; het onderzoekt feiten over de host van de site, inclusief hoe lang het domein bestaat en of het IP‑adres een slechte reputatie heeft; en het bestudeert de structuur van de link, zoals het aantal subdomeinen en mappen of hoe vaak er redirects plaatsvinden. Deze onderdelen worden in getallen omgezet en gecombineerd tot een compacte beschrijving van elke URL.
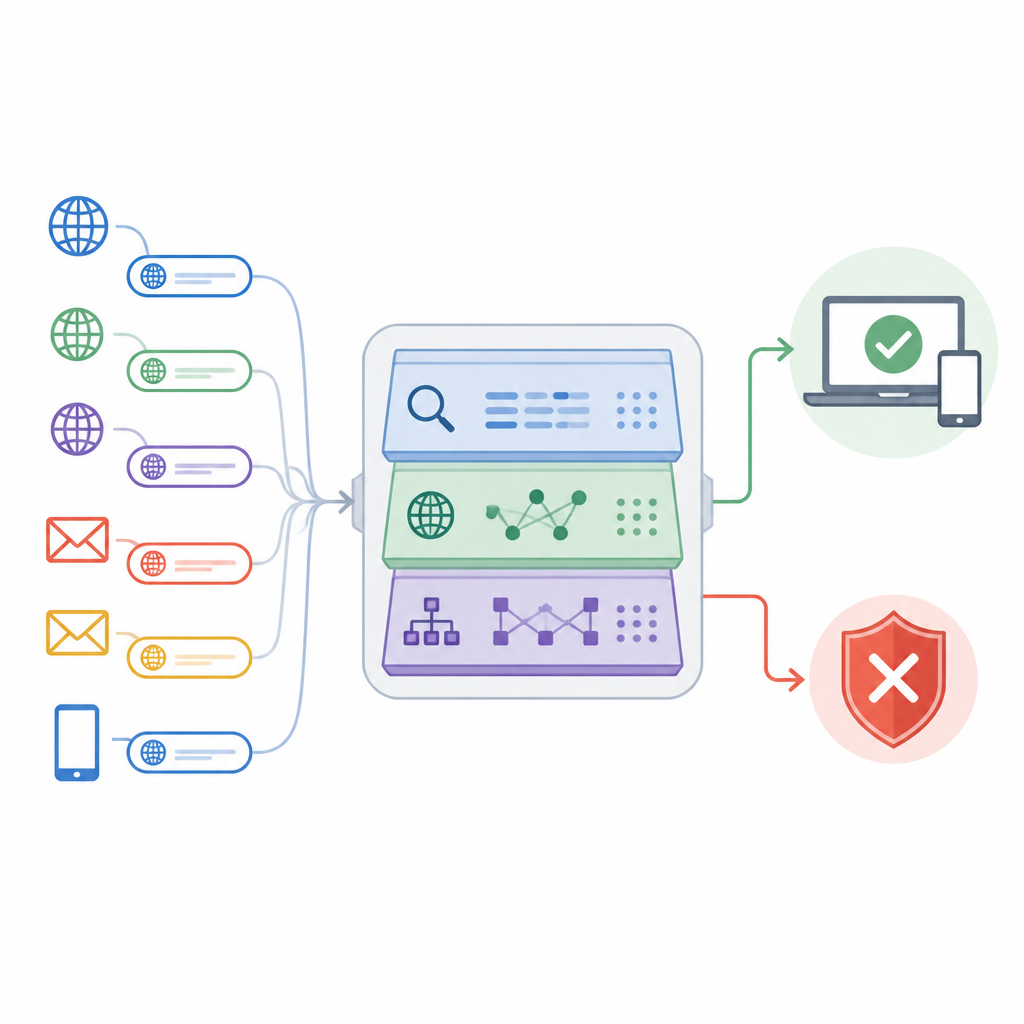
De meest veelzeggende aanwijzingen kiezen
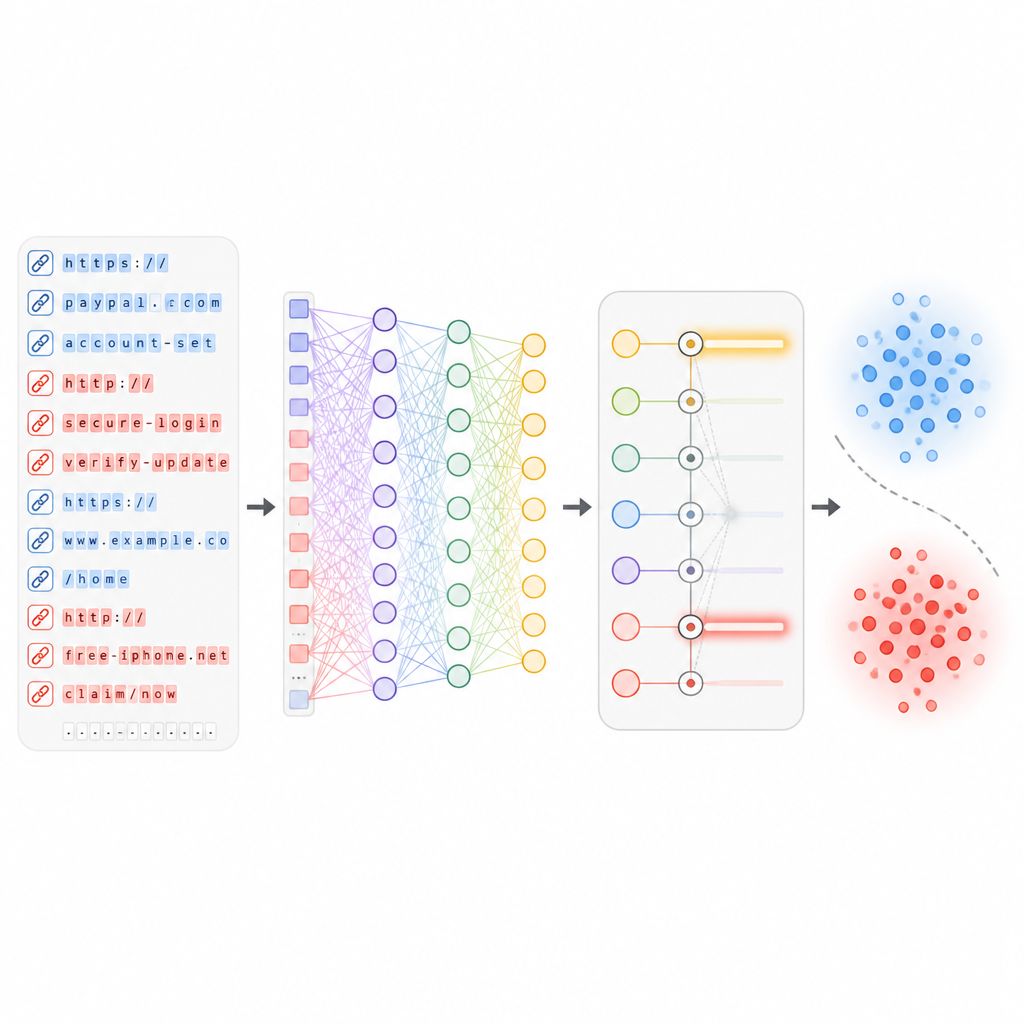
Het verzamelen van veel signaaltypen loopt het risico het systeem in lawaai te laten verdrinken. Om dit te vermijden ontwikkelden de onderzoekers een feature‑selectiestap die elke aanwijzing rangschikt op hoe sterk deze helpt veilige van onveilige links te scheiden. Statistische tests verwijderen metingen die grotendeels andere dupliceren, terwijl leeralgoritmescores die kenmerken benadrukken die fouten sterk verminderen wanneer ze aanwezig zijn. Uit een grote oorspronkelijke set houdt het systeem ongeveer 50 van de meest informatieve features over. Deze selectie versnelt detectie, vermindert de kans op overfitting aan eigenaardigheden in de trainingsdata en behoudt toch de patronen die phishingpogingen het best onderscheiden van legitiem verkeer.
Diep leren verborgen patronen laten zien
Zodra de meest bruikbare features zijn gekozen, worden ze gevoed aan een diep neuraal netwerk met meerdere lagen van virtuele “neuronen” en een attention‑mechanisme. Deze lagen leren complexe relaties tussen verschillende aspecten van een URL, zoals hoe bepaalde woorden samen gaan met een specifieke hostinggeschiedenis of padstructuur. Tijdens de training ziet het netwerk honderden duizenden echte en kwaadaardige links en past het geleidelijk zijn interne gewichten aan om fouten te minimaliseren. Belangrijk is dat het systeem is ontworpen om te worden bijgewerkt zodra nieuwe batches URL’s binnenkomen, zodat het zich kan aanpassen aan nieuwe aanvalsstijlen zonder van nul te hoeven worden opgebouwd.
Hoe goed het nieuwe schild presteert
De auteurs testten ADUIN op een grote publieke verzameling phishing‑ en legitieme URLs, bijeen gebracht uit meerdere bronnen over tijd. Ze verdeelden de data zodat de nieuwste links, die niet tijdens training waren gezien, fungeerden als representatie van echte zero‑day‑aanvallen. Vergeleken met verschillende sterke machine‑learningbaselines behaalde het nieuwe systeem ongeveer 95% totale nauwkeurigheid, identificeerde het correct ongeveer 93% van de geflagde phishinglinks en detecteerde het ongeveer 92% van eerder ongeziene phishing‑URLs. Tegelijkertijd werd slechts ongeveer 3,5% van onschuldige links ten onrechte als gevaarlijk bestempeld, en kon elke URL in ruwweg een vijfde van een seconde worden verwerkt, zelfs onder zware belasting, wat suggereert dat de methode geschikt is voor hoogverkeer‑gateways en bedrijfsnetwerken.
Wat dit betekent voor dagelijks browsen
Voor niet‑specialisten is de kernboodschap dat zorgvuldig kijken naar hoe een webadres is opgebouwd veel kan onthullen over de intenties ervan. Door vele kleine aanwijzingen uit linktekst, host en structuur te combineren en een leersysteem toe te staan continu aan te passen, kan het voorgestelde kader zowel bekende scams als nieuwe, nooit eerder op een zwarte lijst geziene gevallen vangen. Hoewel het geen op zichzelf staande remedie tegen phishing is, laat ADUIN zien hoe slimmer en sneller URL‑onderzoek een belangrijke laag kan worden in de bescherming van e‑mailgebruikers, online kopers en organisaties tegen het weggeven van hun geheimen.
Bronvermelding: Gobinath, R., Manikandan, S. Deep learning-based phishing classification framework for accurate detection using optimized URL intelligence. Sci Rep 16, 15794 (2026). https://doi.org/10.1038/s41598-026-46481-2
Trefwoorden: phishing URLs, deep learning, cybersecurity, URL analysis, web security