Clear Sky Science · pl
Rama klasyfikacji phishingu oparta na głębokim uczeniu do dokładnego wykrywania z optymalizowaną analizą URL-i
Dlaczego fałszywe linki w sieci to narastający problem
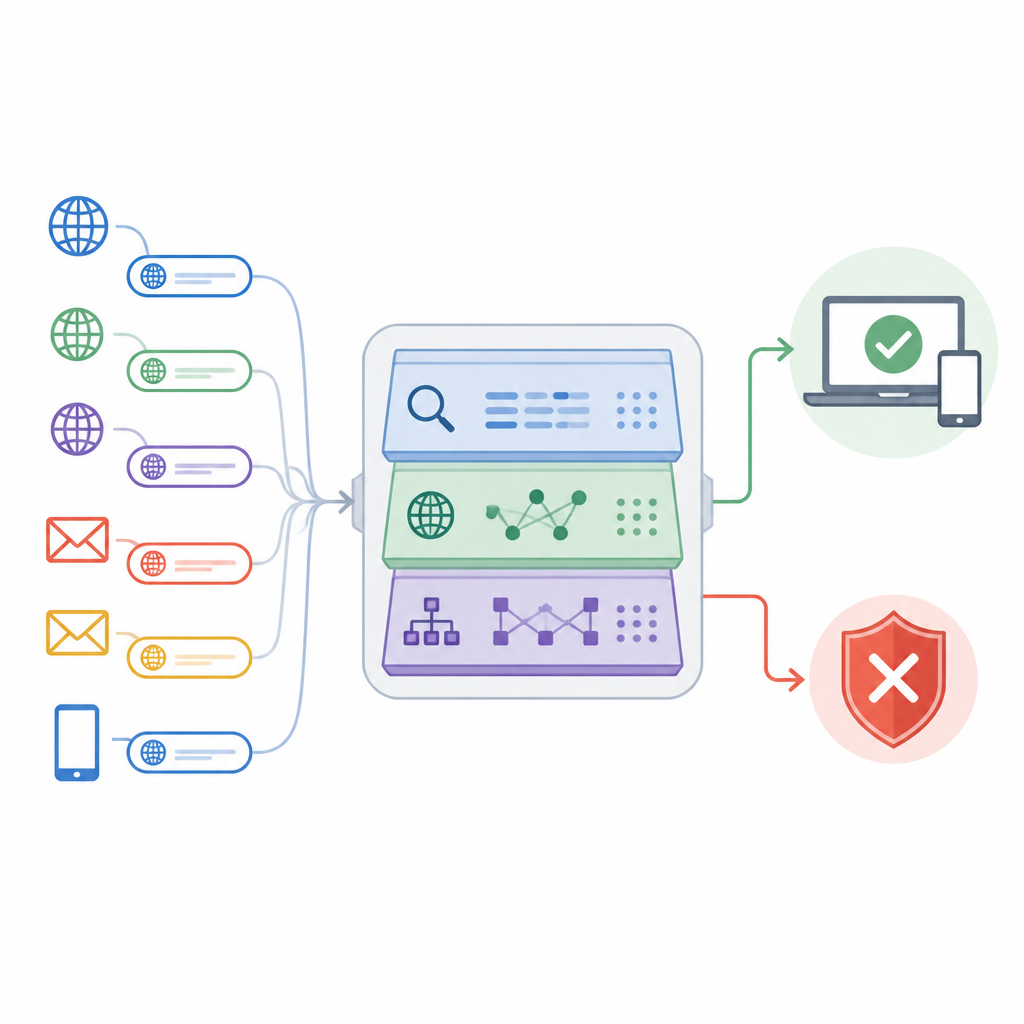
Codziennie klikamy linki w e-mailach, wiadomościach i wynikach wyszukiwania bez zastanowienia. Jednak za niektórymi z nich kryją się starannie skonstruowane pułapki zaprojektowane do kradzieży haseł, danych bankowych lub innych informacji prywatnych. Atakujący nieustannie zmieniają wygląd tych fałszywych adresów, co utrudnia tradycyjnym zabezpieczeniom, takim jak czarne listy, nadążanie za nimi. W badaniu przedstawiono nowy sposób automatycznego i natychmiastowego wykrywania niebezpiecznych linków, mający zapewnić użytkownikom i organizacjom skuteczniejszą ochronę przed oszustwami online.
Jak oszuści ukrywają się na widoku
Współczesne ataki phishingowe rzadko opierają się na oczywistych literówkach czy prymitywnych kopiujących stron banków. Zamiast tego stosują sztuczki, takie jak bardzo krótkie linki, szybko zmieniające się domeny czy prefiksy wyglądające na zabezpieczone, by budzić zaufanie. Wiele istniejących narzędzi wykrywania polega na stałych regułach lub listach znanych złośliwych stron. To może działać przeciwko wczorajszym oszustwom, ale często nie wykrywa nowych ataków zero-day i może błędnie oznaczać nietypowe, lecz nieszkodliwe witryny. Autorzy argumentują, że tempo zmian w sieci jest dziś zbyt szybkie, by polegać wyłącznie na ręcznie tworzonych regułach, i że obrona musi uczyć się wzorców bezpośrednio z danych.
Nauka „czytania” adresów internetowych
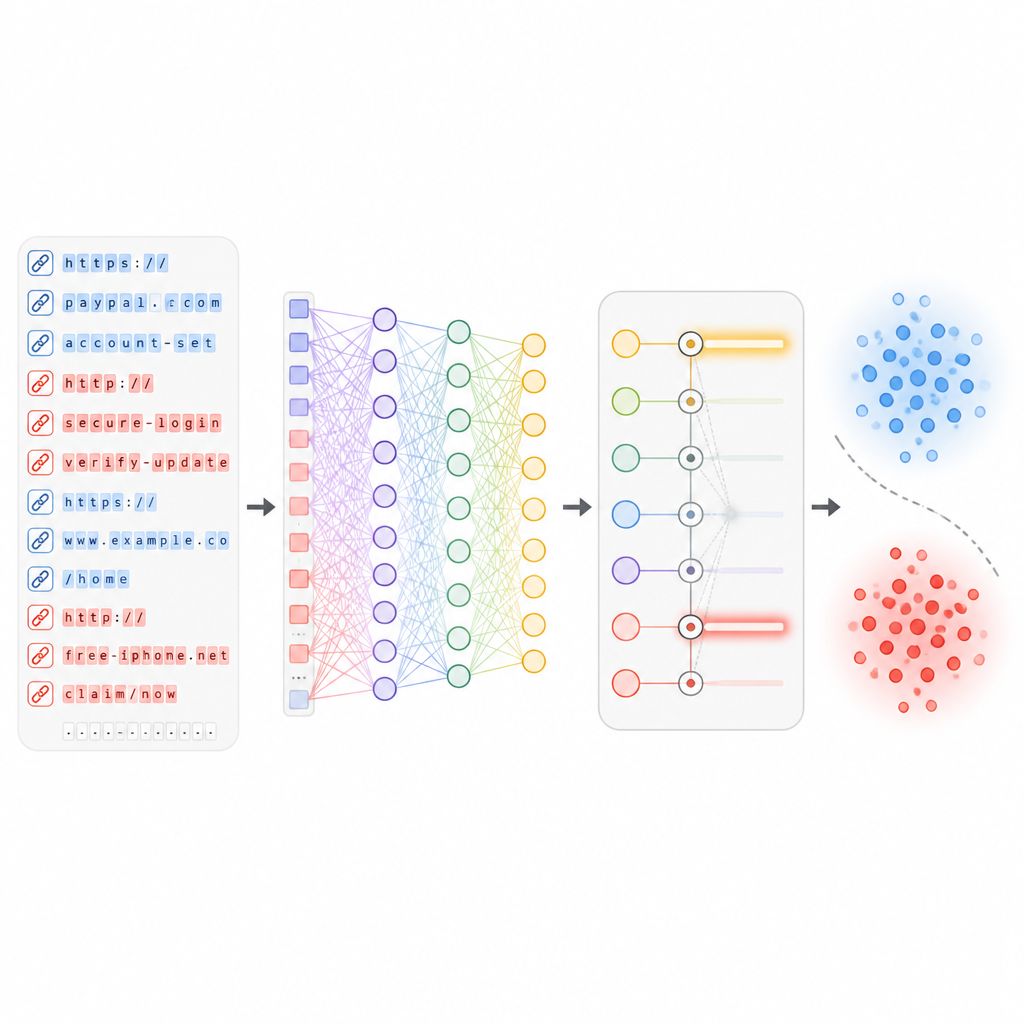
Artykuł przedstawia podejście nazwane Adaptive Deep URL Intelligence Network, w skrócie ADUIN, które traktuje każdy adres internetowy jako bogate źródło wskazówek. Zamiast pobierać całe strony, system koncentruje się na trzech rodzajach informacji. Analizuje sam tekst linku, takie jak długość, mieszanka znaków i podejrzane słowa; bada cechy hosta witryny, w tym wiek domeny i reputację adresu IP; oraz analizuje strukturę linku, na przykład liczbę subdomen i folderów czy częstotliwość przekierowań. Te elementy zamieniane są na liczby i łączone w zwarte opisy każdego URL-a.
Wybór najbardziej wymownych wskazówek
Zbieranie wielu typów sygnałów grozi zalaniem systemu szumem. Aby tego uniknąć, badacze wprowadzili etap selekcji cech, który ranguje poszczególne wskazówki według siły, z jaką pomagają oddzielić linki bezpieczne od niebezpiecznych. Testy statystyczne usuwają pomiary głównie duplikujące inne, podczas gdy miary oparte na uczeniu wskazują te, które znacząco zmniejszają błędy, gdy są obecne. Z dużego zbioru początkowego system zachowuje około 50 najbardziej informatywnych cech. To przycinanie przyspiesza wykrywanie, zmniejsza ryzyko nadmiernego dopasowania do osobliwości danych treningowych i jednocześnie zachowuje wzorce najlepiej rozróżniające próby phishingowe od ruchu legalnego.
Pozwalanie głębokiemu uczeniu dostrzegać ukryte wzorce
Gdy wybierze się najbardziej użyteczne cechy, przekazuje się je do głębokiej sieci neuronowej zawierającej kilka warstw wirtualnych „neuronów” oraz mechanizm uwagi. Warstwy te uczą się złożonych zależności między różnymi aspektami URL-a, na przykład jak pewne słowa łączą się ze specyficzną historią hostingu czy strukturą ścieżki. Podczas treningu sieć widzi setki tysięcy prawdziwych i złośliwych linków i stopniowo dostosowuje wewnętrzne wagi, by minimalizować błędy. Co ważne, system zaprojektowano tak, by był aktualizowany wraz z nadejściem nowych partii URL-i, dzięki czemu może dostosowywać się do nowych stylów ataków bez konieczności budowy od zera.
Jak dobrze działa nowa tarcza
Autorzy przetestowali ADUIN na dużym publicznym zbiorze adresów phishingowych i legalnych zebranych z różnych źródeł w czasie. Podzielili dane tak, aby najnowsze linki, nieznane w trakcie treningu, służyły jako odpowiednik rzeczywistych ataków zero-day. W porównaniu z kilkoma silnymi bazowymi metodami uczenia maszynowego nowy system osiągnął około 95% dokładności ogólnej, poprawnie zidentyfikował około 93% oznaczonych linków phishingowych i wykrył około 92% wcześniej nieznanych URL-i phishingowych. Jednocześnie jedynie około 3,5% nieszkodliwych linków zostało błędnie oznaczonych jako niebezpieczne, a przetworzenie jednego URL-a zajmowało około jednej piątej sekundy nawet przy dużym obciążeniu, co sugeruje, że metoda nadaje się do bramek o dużym ruchu i sieci korporacyjnych.
Co to oznacza dla codziennego przeglądania
Dla osób niebędących specjalistami kluczowy przekaz jest taki, że uważna analiza budowy adresu internetowego może wiele powiedzieć o jego intencjach. Łącząc wiele drobnych wskazówek z tekstu linku, informacji o hoście i jego strukturze, oraz pozwalając systemowi uczącemu się ciągle adaptować, proponowane rozwiązanie może wychwycić zarówno znane oszustwa, jak i nowe, które nigdy nie pojawiły się na żadnej czarnej liście. Choć nie jest to samodzielne lekarstwo na phishing, ADUIN pokazuje, jak mądrzejsza i szybsza analiza URL-i może stać się ważną warstwą ochrony użytkowników poczty, kupujących online i organizacji przed wyłudzeniem ich poufnych danych.
Cytowanie: Gobinath, R., Manikandan, S. Deep learning-based phishing classification framework for accurate detection using optimized URL intelligence. Sci Rep 16, 15794 (2026). https://doi.org/10.1038/s41598-026-46481-2
Słowa kluczowe: adresy URL phishingowe, głębokie uczenie, cyberbezpieczeństwo, analiza URL, bezpieczeństwo sieci