Clear Sky Science · en
Deep learning-based phishing classification framework for accurate detection using optimized URL intelligence
Why fake web links are a growing problem
Every day we click links in emails, messages, and search results without a second thought. Behind some of those links, however, are carefully crafted traps designed to steal passwords, banking details, or other private data. Attackers keep changing how these fake web addresses look, which makes traditional defenses like blacklists struggle to keep up. This study presents a new way to spot dangerous links automatically and in real time, aiming to give web users and organizations a stronger shield against online scams.
How online tricksters hide in plain sight
Modern phishing attacks rarely rely on obvious misspellings or crude copies of bank websites. Instead, they use tricks such as very short links, fast-changing domains, and secure-looking prefixes to appear trustworthy. Many existing detection tools depend on fixed rules or lists of known bad sites. These can work for yesterday’s scams but often miss fresh ones, called zero-day attacks, and can wrongly flag unusual but harmless sites. The authors argue that the web now moves too quickly for hand-crafted rules alone, and that defenses must learn patterns directly from the data.
Teaching a system to “read” web addresses
The paper introduces an approach called the Adaptive Deep URL Intelligence Network, or ADUIN, which treats each web address as a rich source of clues. Instead of downloading full pages, the system focuses on three kinds of information. It looks at the text of the link itself, such as its length, character mix, and suspicious words; it examines facts about the site’s host, including how long the domain has existed and whether its internet address has a bad reputation; and it studies the structure of the link, like how many subdomains and folders it uses or how often it redirects. These pieces are turned into numbers and combined into a compact description of each URL.
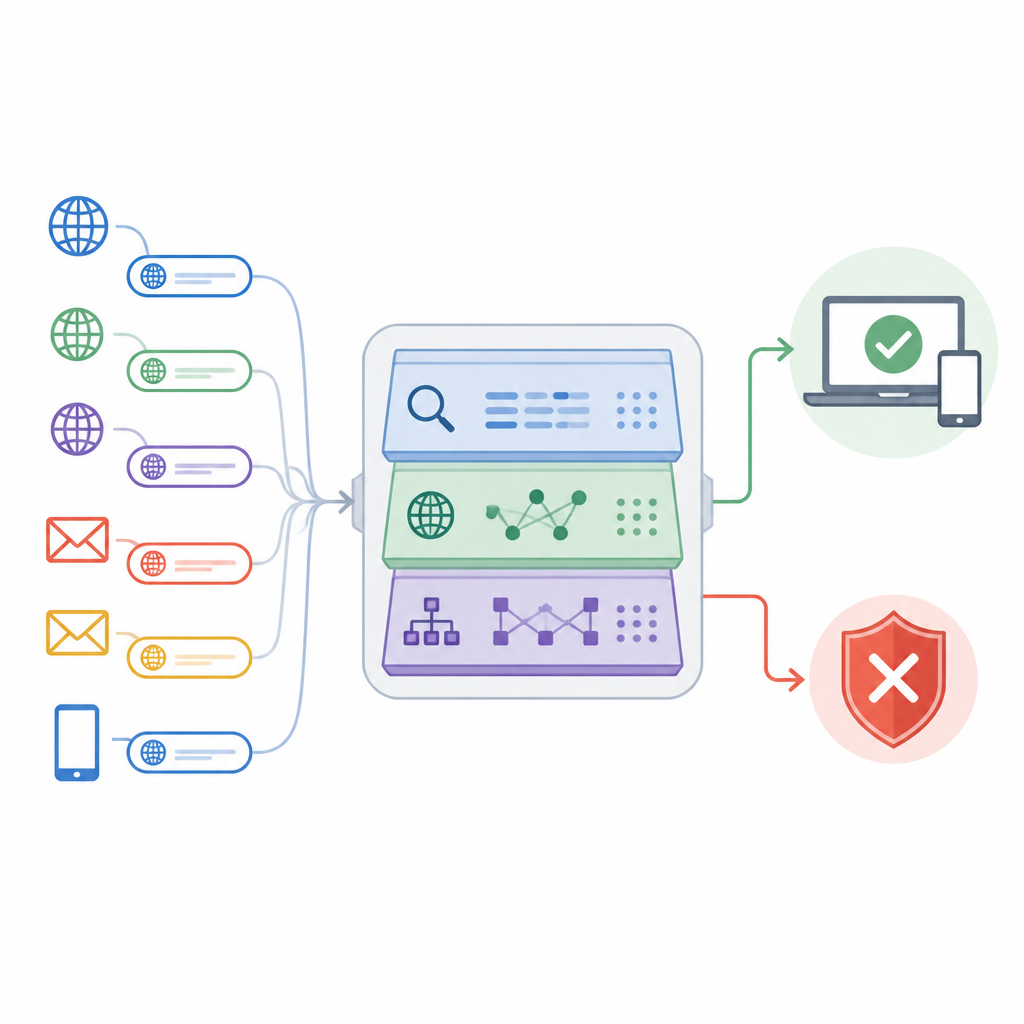
Choosing the most telling clues
Collecting many types of signals risks drowning the system in noise. To avoid this, the researchers created a feature selection step that ranks each clue by how strongly it helps separate safe from unsafe links. Statistical tests remove measurements that mostly duplicate others, while learning-based scores highlight those that sharply reduce errors when present. From a large original set, the system keeps about 50 of the most informative features. This trimming speeds up detection, reduces the chance of overfitting to quirks in the training data, and still preserves the patterns that best distinguish phishing attempts from legitimate traffic.
Letting deep learning spot hidden patterns
Once the most useful features are chosen, they are fed into a deep neural network that contains several layers of virtual “neurons” and an attention mechanism. These layers learn complex relationships between different aspects of a URL, such as how certain words combine with a particular hosting history or path structure. During training, the network sees hundreds of thousands of real and malicious links and gradually adjusts its internal weights to minimize mistakes. Importantly, the system is designed to be updated as new batches of URLs arrive, so it can adapt to new attack styles without having to be rebuilt from scratch.
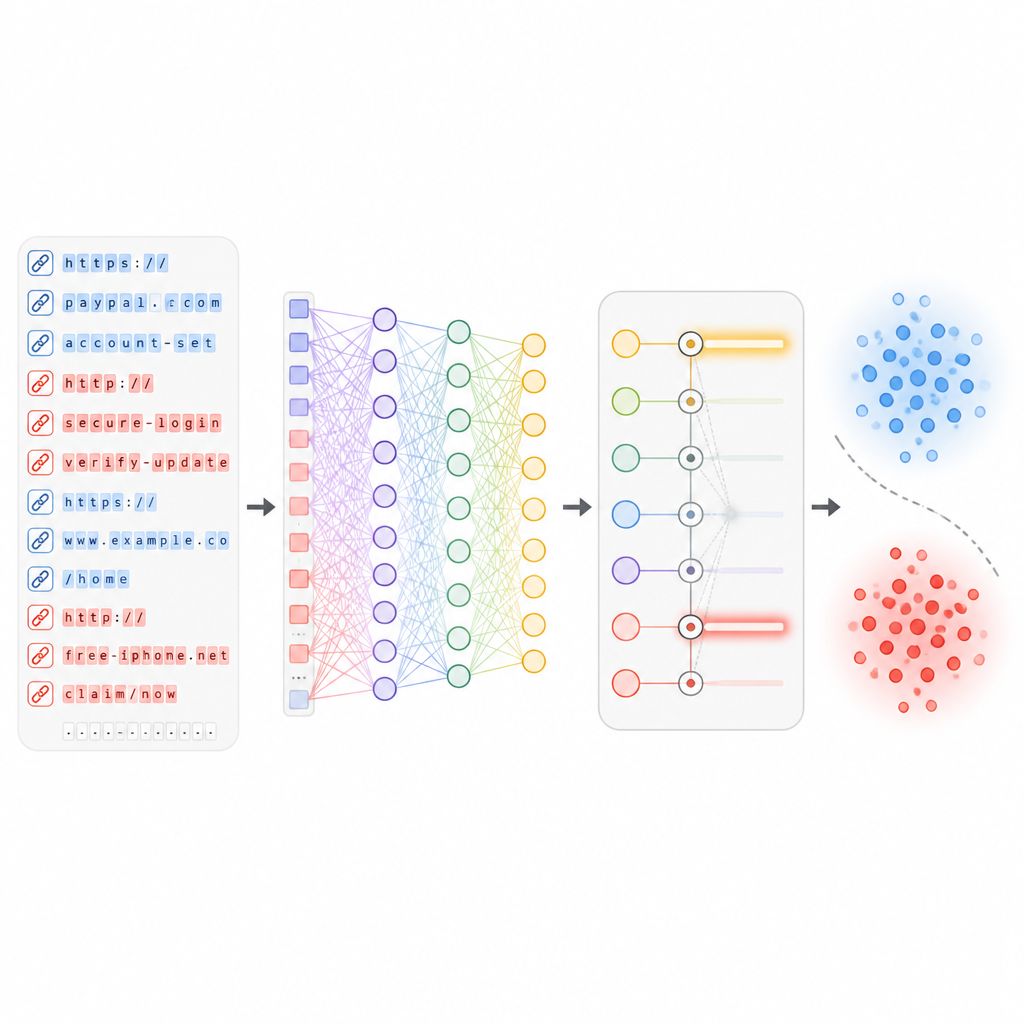
How well the new shield performs
The authors tested ADUIN on a large public collection of phishing and legitimate URLs gathered from several sources over time. They split the data so that the newest links, unseen during training, acted as a stand-in for real-world zero-day attacks. Compared with several strong machine learning baselines, the new system achieved about 95% overall accuracy, correctly identified around 93% of flagged phishing links, and detected about 92% of previously unseen phishing URLs. At the same time, only about 3.5% of harmless links were mistakenly labeled as dangerous, and each URL could be processed in roughly a fifth of a second even under heavy load, suggesting that the method is suitable for high-traffic gateways and corporate networks.
What this means for everyday browsing
For non-specialists, the key message is that looking carefully at how a web address is built can reveal a great deal about its intentions. By combining many small clues from the link text, its host, and its structure, and by allowing a learning system to continually adapt, the proposed framework can catch both familiar scams and new ones that have never appeared on any blacklist. While it is not a stand-alone cure for phishing, ADUIN shows how smarter, faster analysis of URLs can become an important layer in protecting email users, online shoppers, and organizations from being tricked into handing over their secrets.
Citation: Gobinath, R., Manikandan, S. Deep learning-based phishing classification framework for accurate detection using optimized URL intelligence. Sci Rep 16, 15794 (2026). https://doi.org/10.1038/s41598-026-46481-2
Keywords: phishing URLs, deep learning, cybersecurity, URL analysis, web security