Clear Sky Science · it
Framework di classificazione del phishing basato sul deep learning per rilevamento accurato tramite intelligenza URL ottimizzata
Perché i link web falsi sono un problema in crescita
Ogni giorno clicchiamo link in email, messaggi e risultati di ricerca senza pensarci troppo. Dietro alcuni di quei link, però, ci sono trappole accuratamente costruite per rubare password, dati bancari o altre informazioni private. Gli aggressori continuano a modificare l’aspetto di questi indirizzi web falsi, il che rende le difese tradizionali, come le blacklist, difficili da aggiornare in tempo. Questo studio presenta un nuovo metodo per riconoscere automaticamente e in tempo reale i link pericolosi, con l’obiettivo di offrire agli utenti e alle organizzazioni una protezione più solida contro le truffe online.
Come i truffatori online si nascondono in piena vista
Gli attacchi di phishing moderni raramente si basano su evidenti errori di ortografia o su copie grossolane di siti bancari. Usano invece espedienti come link molto corti, domini che cambiano rapidamente e prefissi dall’aspetto sicuro per sembrare affidabili. Molti strumenti di rilevamento esistenti si affidano a regole fisse o a elenchi di siti conosciuti come malevoli. Questi possono funzionare per le truffe di ieri, ma spesso non intercettano quelle nuove, chiamate attacchi zero-day, e possono segnalare erroneamente siti insoliti ma innocui. Gli autori sostengono che il web ora evolve troppo rapidamente per regole costruite a mano e che le difese devono apprendere i pattern direttamente dai dati.
Insegnare a un sistema a “leggere” gli indirizzi web
Il paper introduce un approccio chiamato Adaptive Deep URL Intelligence Network, o ADUIN, che considera ogni indirizzo web come una ricca fonte di indizi. Invece di scaricare le pagine complete, il sistema si concentra su tre tipi di informazioni. Esamina il testo del link stesso, come la lunghezza, la composizione dei caratteri e parole sospette; valuta dati sul host del sito, inclusa la durata di vita del dominio e se l’indirizzo IP ha una cattiva reputazione; e analizza la struttura del link, ad esempio il numero di sottodomini e cartelle o la frequenza dei reindirizzamenti. Questi elementi vengono convertiti in numeri e combinati in una descrizione compatta di ogni URL.
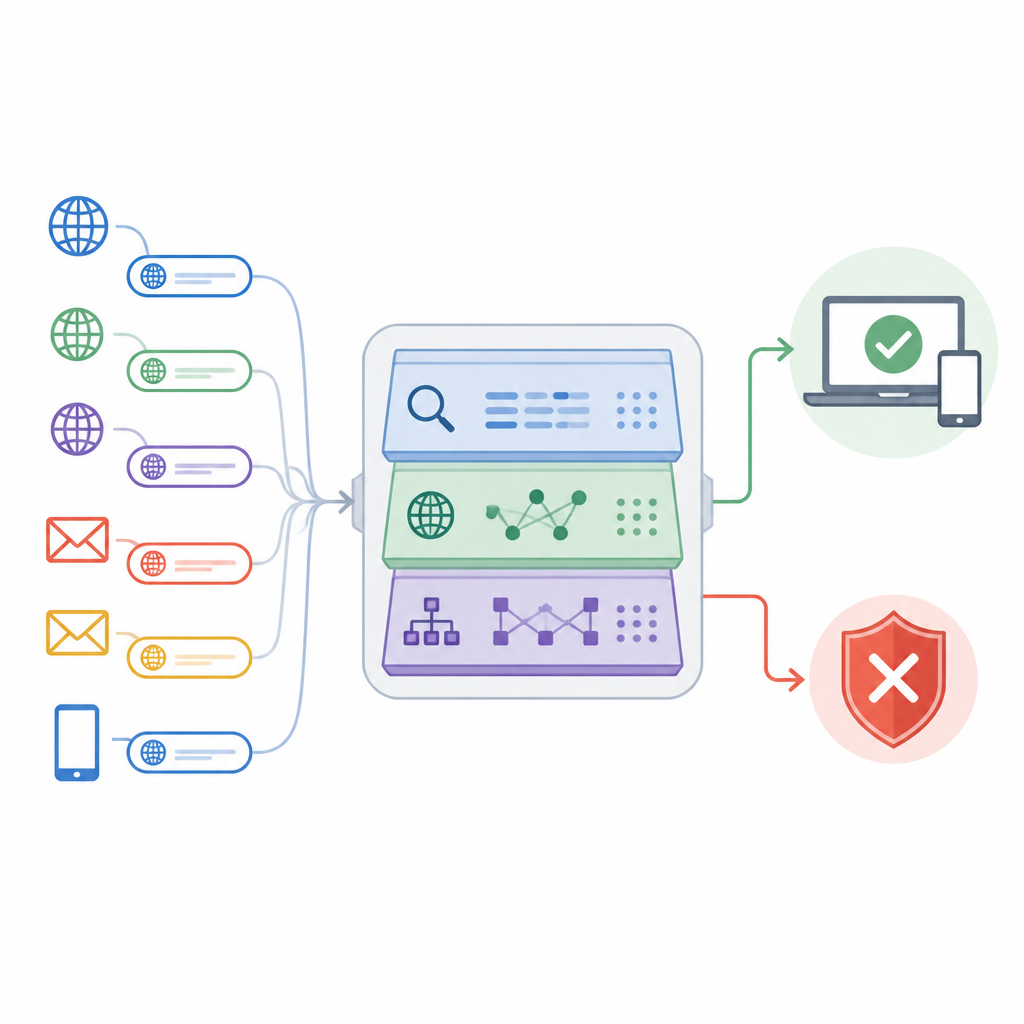
Scegliere gli indizi più significativi
Raccogliere molti tipi di segnali rischia di sommergere il sistema con rumore. Per evitarlo, i ricercatori hanno introdotto una fase di selezione delle feature che classifica ogni indizio in base a quanto aiuta a separare link sicuri da quelli pericolosi. Test statistici rimuovono misure che duplicano in gran parte altre, mentre punteggi basati sull’apprendimento evidenziano quelle che riducono nettamente gli errori quando presenti. Da un ampio insieme iniziale, il sistema conserva circa 50 delle feature più informative. Questa riduzione accelera il rilevamento, diminuisce il rischio di overfitting a caratteristiche del set di addestramento e mantiene comunque i pattern che meglio distinguono i tentativi di phishing dal traffico legittimo.
Lasciare che il deep learning individui pattern nascosti
Una volta scelte le feature più utili, vengono alimentate in una rete neurale profonda che contiene diversi strati di “neuroni” virtuali e un meccanismo di attenzione. Questi strati apprendono relazioni complesse tra aspetti diversi di una URL, per esempio come certe parole si combinano con una particolare storia di hosting o con una struttura di percorso. Durante l’addestramento la rete vede centinaia di migliaia di link reali e malevoli e regola gradualmente i propri pesi interni per minimizzare gli errori. È importante che il sistema sia progettato per essere aggiornato man mano che arrivano nuovi batch di URL, così da adattarsi a nuovi stili d’attacco senza dover essere ricostruito da zero.
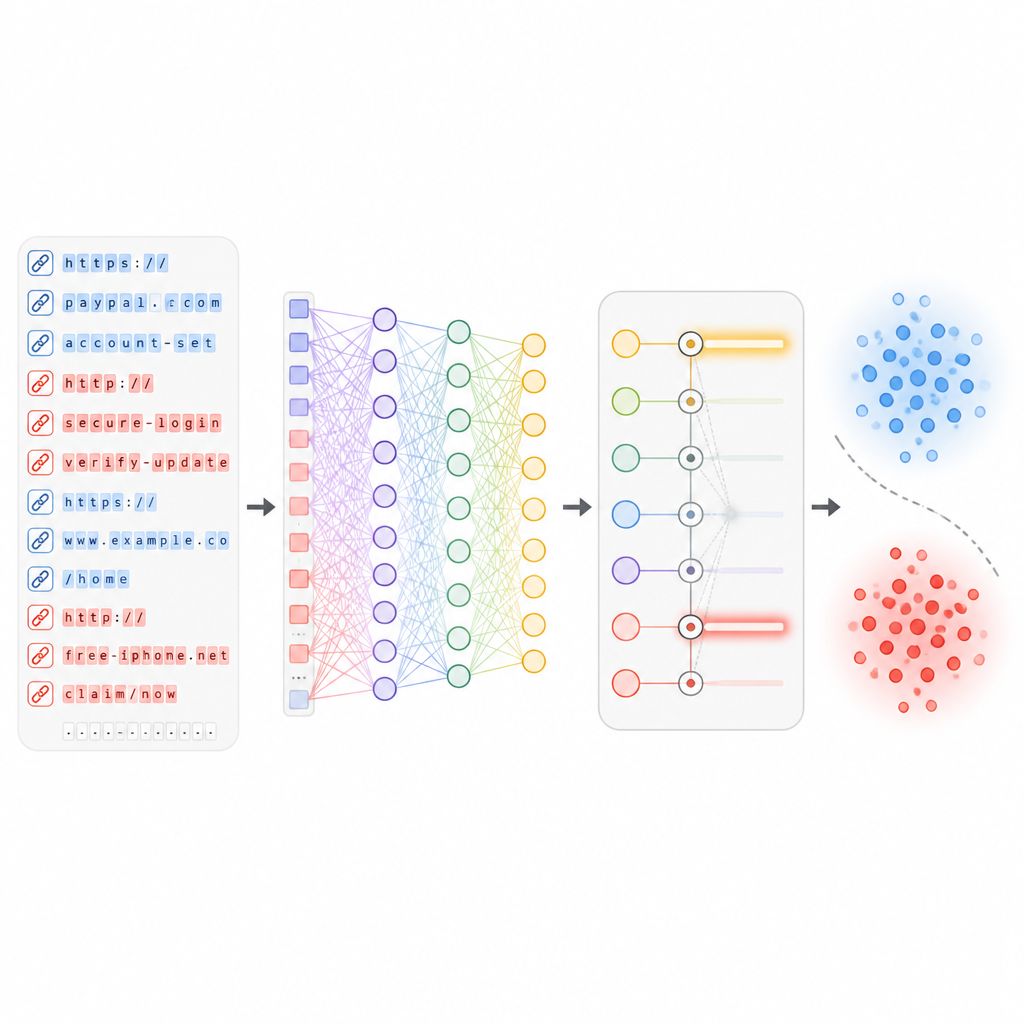
Quanto bene funziona il nuovo scudo
Gli autori hanno testato ADUIN su una grande raccolta pubblica di URL di phishing e legittime ottenute da diverse fonti nel tempo. Hanno suddiviso i dati in modo che i link più recenti, non visti durante l’addestramento, fungessero da proxy per attacchi zero-day reali. Rispetto a diversi forti baseline di machine learning, il nuovo sistema ha raggiunto circa il 95% di accuratezza complessiva, ha identificato correttamente circa il 93% dei link di phishing segnalati e ha individuato circa il 92% delle URL di phishing precedentemente non viste. Allo stesso tempo, solo circa il 3,5% dei link innocui è stato etichettato erroneamente come pericoloso, e ogni URL poteva essere elaborata in circa un quinto di secondo anche sotto carico elevato, suggerendo che il metodo è adatto a gateway ad alto traffico e reti aziendali.
Cosa significa per la navigazione di tutti i giorni
Per i non specialisti, il messaggio chiave è che osservare attentamente come è costruito un indirizzo web può rivelare molto sulle sue intenzioni. Combinando molti piccoli indizi dal testo del link, dal suo host e dalla sua struttura, e permettendo a un sistema di apprendimento di adattarsi continuamente, il framework proposto può intercettare sia truffe conosciute sia nuove che non sono mai apparse in una blacklist. Pur non essendo una cura unica e definitiva contro il phishing, ADUIN dimostra come un’analisi delle URL più intelligente e veloce possa diventare un livello importante nella protezione degli utenti di posta elettronica, degli acquirenti online e delle organizzazioni dall’essere indotti a consegnare i propri segreti.
Citazione: Gobinath, R., Manikandan, S. Deep learning-based phishing classification framework for accurate detection using optimized URL intelligence. Sci Rep 16, 15794 (2026). https://doi.org/10.1038/s41598-026-46481-2
Parole chiave: URL di phishing, deep learning, cybersicurezza, analisi URL, sicurezza web