Clear Sky Science · pt
Estrutura de classificação de phishing baseada em deep learning para detecção precisa usando inteligência de URL otimizada
Por que links falsos na web são um problema crescente
Cada dia clicamos em links em e-mails, mensagens e resultados de busca sem pensar duas vezes. Atrás de alguns desses links, entretanto, há armadilhas cuidadosamente elaboradas para roubar senhas, dados bancários ou outras informações privadas. Os atacantes continuam mudando a aparência desses endereços falsos, o que faz com que defesas tradicionais como listas negras tenham dificuldade em acompanhar. Este estudo apresenta uma nova forma de identificar links perigosos automaticamente e em tempo real, com o objetivo de oferecer aos usuários e às organizações uma proteção mais robusta contra golpes online.
Como golpistas online se escondem à vista de todos
Ataques de phishing modernos raramente dependem de erros de ortografia óbvios ou cópias grosseiras de sites bancários. Em vez disso, usam artifícios como links muito curtos, domínios que mudam rápido e prefixos com aparência segura para parecerem confiáveis. Muitas ferramentas de detecção existentes dependem de regras fixas ou listas de sites maliciosos conhecidos. Essas abordagens podem funcionar para golpes antigos, mas frequentemente deixam passar ataques novos, chamados zero-day, e podem sinalizar incorretamente sites incomuns, porém inofensivos. Os autores argumentam que a web hoje se movimenta rápido demais para regras feitas à mão sozinhas, e que as defesas precisam aprender padrões diretamente a partir dos dados.
Ensinar um sistema a “ler” endereços da web
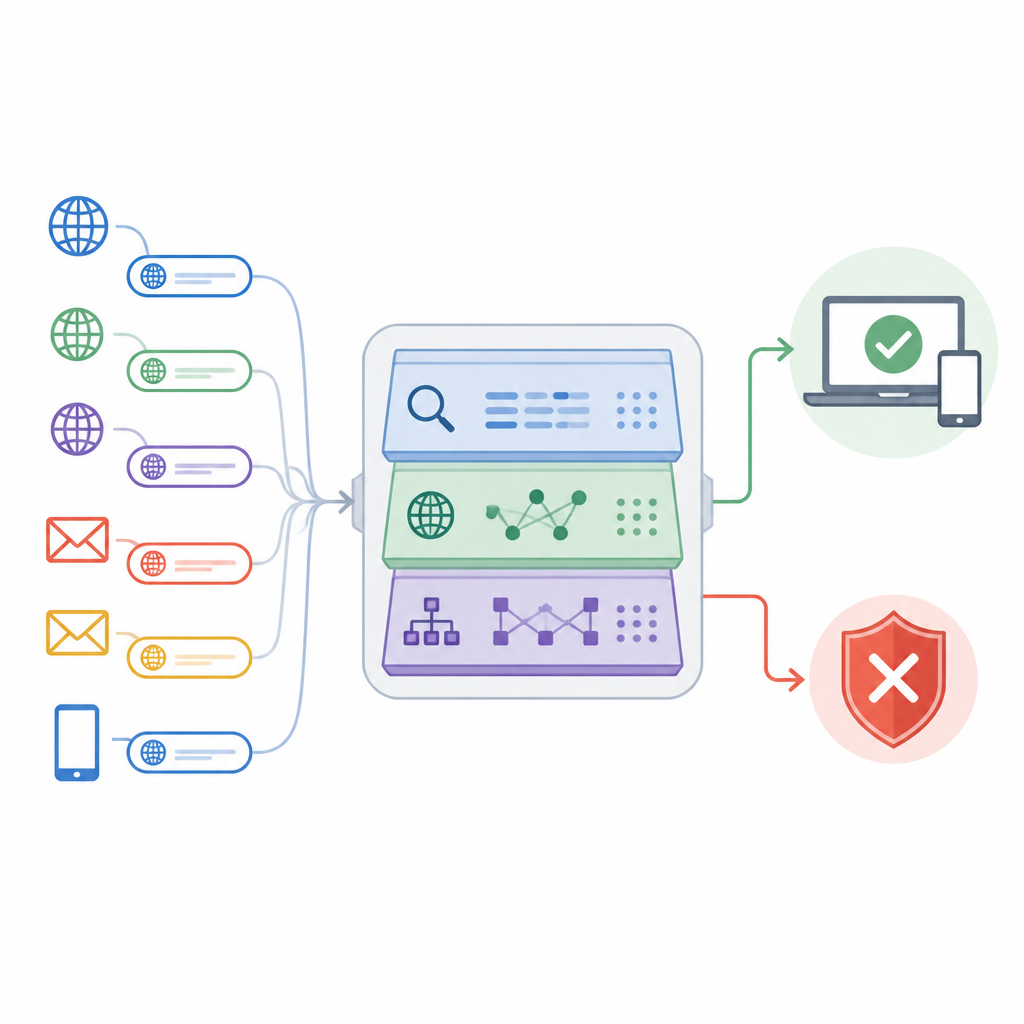
O artigo apresenta uma abordagem chamada Adaptive Deep URL Intelligence Network, ou ADUIN, que trata cada endereço web como uma fonte rica de pistas. Em vez de baixar páginas inteiras, o sistema foca em três tipos de informação. Analisa o texto do próprio link, como seu comprimento, mistura de caracteres e palavras suspeitas; examina fatos sobre o host do site, incluindo há quanto tempo o domínio existe e se o endereço IP tem má reputação; e estuda a estrutura do link, como quantos subdomínios e pastas ele usa ou com que frequência redireciona. Esses elementos são convertidos em números e combinados em uma descrição compacta de cada URL.
Escolhendo as pistas mais reveladoras
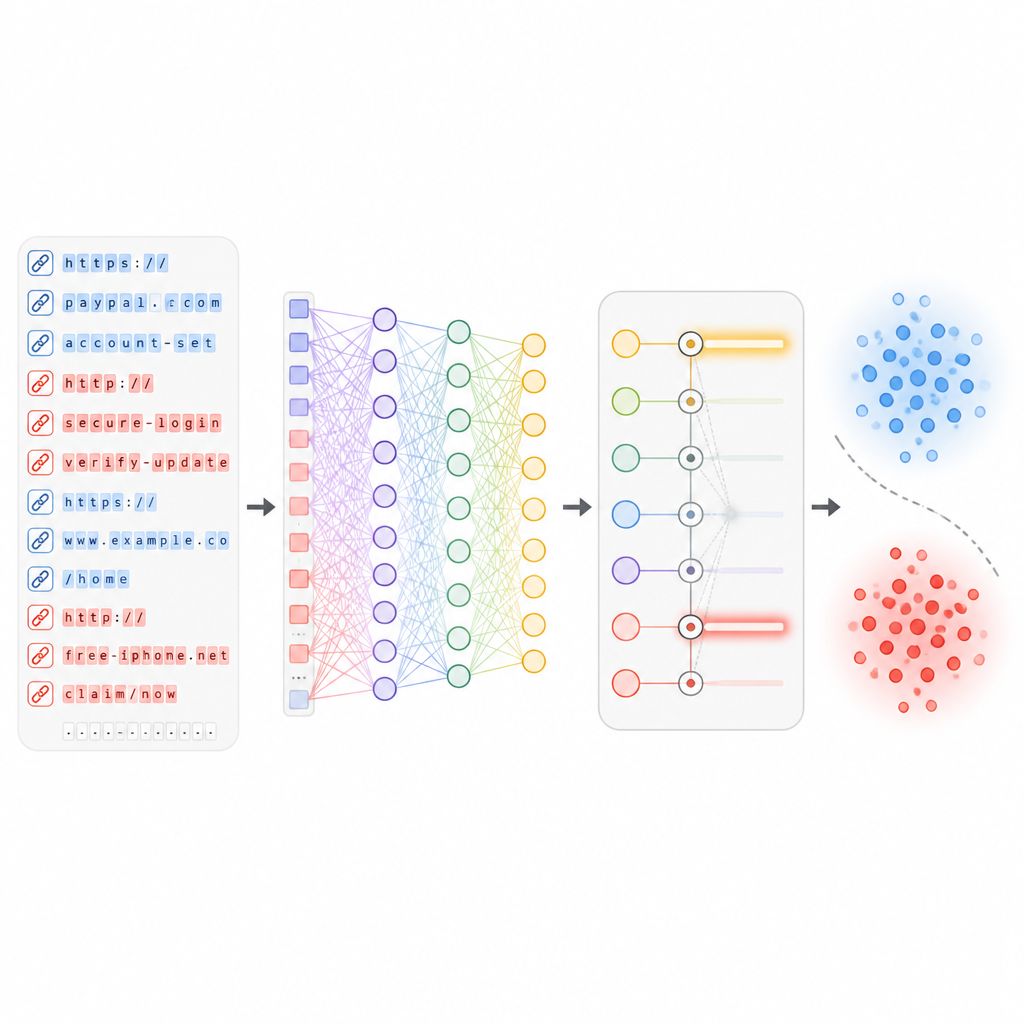
Coletar muitos tipos de sinais corre o risco de afogar o sistema em ruído. Para evitar isso, os pesquisadores criaram uma etapa de seleção de características que classifica cada pista pelo quanto ela ajuda a separar links seguros de inseguros. Testes estatísticos removem medidas que basicamente duplicam outras, enquanto pontuações baseadas em aprendizado destacam aquelas que reduzem fortemente os erros quando presentes. A partir de um conjunto original amplo, o sistema mantém cerca de 50 das características mais informativas. Esse corte acelera a detecção, reduz a chance de overfitting a peculiaridades dos dados de treinamento e ainda preserva os padrões que melhor distinguem tentativas de phishing do tráfego legítimo.
Deixando o deep learning detectar padrões ocultos
Uma vez escolhidas as características mais úteis, elas são alimentadas em uma rede neural profunda que contém várias camadas de “neurônios” virtuais e um mecanismo de atenção. Essas camadas aprendem relações complexas entre diferentes aspectos de uma URL, como a combinação de certas palavras com um histórico de hospedagem ou estrutura de caminho específicos. Durante o treinamento, a rede vê centenas de milhares de links reais e maliciosos e ajusta gradualmente seus pesos internos para minimizar erros. Importante: o sistema foi projetado para ser atualizado conforme novos lotes de URLs chegam, podendo assim se adaptar a novos estilos de ataque sem precisar ser reconstruído do zero.
Como o novo escudo se sai na prática
Os autores testaram o ADUIN em uma grande coleção pública de URLs de phishing e legítimas reunidas de várias fontes ao longo do tempo. Eles dividiram os dados de modo que os links mais recentes, não vistos durante o treinamento, atuassem como substitutos de ataques zero-day do mundo real. Em comparação com vários fortes baselines de machine learning, o novo sistema alcançou cerca de 95% de acurácia geral, identificou corretamente aproximadamente 93% dos links de phishing sinalizados e detectou cerca de 92% das URLs de phishing até então desconhecidas. Ao mesmo tempo, apenas cerca de 3,5% dos links inofensivos foram rotulados erroneamente como perigosos, e cada URL pôde ser processada em aproximadamente um quinto de segundo mesmo sob carga elevada, sugerindo que o método é adequado para gateways de alto tráfego e redes corporativas.
O que isso significa para a navegação cotidiana
Para não especialistas, a mensagem principal é que observar com atenção como um endereço web é construído pode revelar muito sobre suas intenções. Ao combinar muitas pequenas pistas do texto do link, do seu host e de sua estrutura, e permitindo que um sistema de aprendizado se adapte continuamente, a estrutura proposta pode capturar tanto golpes conhecidos quanto novos que nunca apareceram em qualquer lista negra. Embora não seja uma cura completa para o phishing, o ADUIN mostra como uma análise de URLs mais inteligente e rápida pode se tornar uma camada importante na proteção de usuários de e-mail, compradores online e organizações contra o engano que leva à divulgação de segredos.
Citação: Gobinath, R., Manikandan, S. Deep learning-based phishing classification framework for accurate detection using optimized URL intelligence. Sci Rep 16, 15794 (2026). https://doi.org/10.1038/s41598-026-46481-2
Palavras-chave: URLs de phishing, deep learning, cibersegurança, análise de URL, segurança web