Clear Sky Science · ar
إطار تصنيف التصيد القائم على التعلم العميق للكشف الدقيق باستخدام استخبارات عنوان URL المحسّنة
لماذا تُشكّل الروابط المزيفة مشكلة متزايدة
نضغط يوميًا على روابط في رسائل البريد الإلكتروني والرسائل ونتائج البحث دون تفكير ثانٍ. خلف بعض تلك الروابط، مع ذلك، فخاخ مُتقنة الصنع تهدف إلى سرقة كلمات المرور أو معلومات الحسابات المصرفية أو بيانات خاصة أخرى. يواصل المهاجمون تغيير مظهر هذه العناوين المزيفة، مما يجعل الدفاعات التقليدية مثل القوائم السوداء تكافح لمواكبة التطور. تعرض هذه الدراسة طريقة جديدة لرصد الروابط الخطرة تلقائيًا وفي الوقت الحقيقي، بهدف منح مستخدمي الويب والمنظمات درعًا أقوى ضد الاحتيال الإلكتروني.
كيف يختبئ المحتالون على العلن
نادراً ما تعتمد هجمات التصيد الحديثة على أخطاء إملائية واضحة أو نسخ رديئة لمواقع البنوك. بدلاً من ذلك، يستخدمون حيلًا مثل الروابط القصيرة جداً، والنطاقات التي تتغير بسرعة، والبادئات التي تبدو آمنة لتبدو موثوقة. تعتمد العديد من أدوات الكشف الحالية على قواعد ثابتة أو قوائم بمواقع معروفة سيئة السمعة. قد تنجح هذه الأساليب مع عمليات الاحتيال القديمة لكنها غالبًا ما تفوت الهجمات الجديدة المسماة بهجمات اليوم الصفري، وقد تعلم مواقع شاذة ولكن غير ضارة خطأً. يجادل المؤلفون بأن الويب أصبح يتحرك بسرعة تفوق القواعد المصممة يدويًا وحدها، وأن الدفاعات يجب أن تتعلم الأنماط مباشرة من البيانات.
تعليم النظام "قراءة" عناوين الويب
تقدم الورقة نهجًا يسمى شبكة استخبارات عنوان URL العميقة التكيفية، أو ADUIN، الذي يتعامل مع كل عنوان ويب كمصدر ثري للدلالات. بدلاً من تنزيل الصفحات كاملة، يركز النظام على ثلاثة أنواع من المعلومات. ينظر إلى نص الرابط نفسه، مثل طوله، وتكوين الأحرف، والكلمات المشتبه بها؛ يفحص حقائق حول مضيف الموقع، بما في ذلك مدة وجود النطاق وما إذا كان عنوانه الشبكي ذو سمعة سيئة؛ ويدرس بنية الرابط، مثل عدد النطاقات الفرعية والمجلدات التي يستخدمها أو عدد عمليات إعادة التوجيه. تُحوَّل هذه الأجزاء إلى أرقام وتُدمج في وصف مدمج لكل عنوان URL.
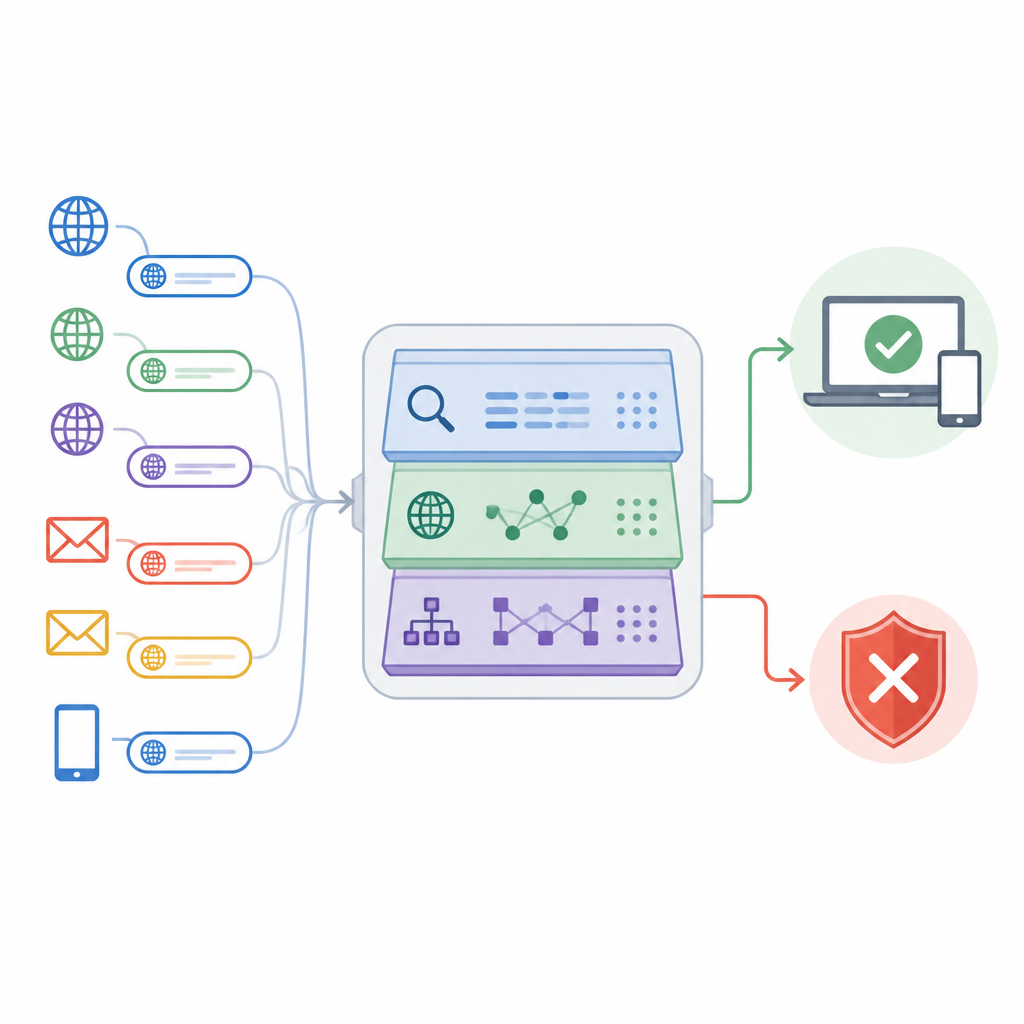
اختيار الدلائل الأكثر إفادة
جمع أنواع كثيرة من الإشارات يعرض النظام لخطر الغرق في الضوضاء. لتجنب ذلك، أنشأ الباحثون خطوة لاختيار الميزات تقوم بترتيب كل دليل حسب مدى قدرته على فصل الروابط الآمنة عن غير الآمنة. تزيل الاختبارات الإحصائية القياسات التي تكرر غيرها إلى حد كبير، بينما تبرز الدرجات المعتمدة على التعلم تلك التي تقلل الأخطاء بشكل حاد عند توافرها. من مجموعة أولية كبيرة، يحتفظ النظام بحوالي 50 من أكثر الميزات إفادة. هذا التقليم يسرّع عملية الكشف، ويقلل احتمال الإفراط في التوافق مع خصائص بيانات التدريب، ويظل يحافظ على الأنماط التي تميز محاولات التصيد عن الحركة الشرعية بأفضل شكل.
السماح للتعلم العميق بكشف الأنماط الخفية
بمجرد اختيار الميزات الأكثر فائدة، تُغذى إلى شبكة عصبية عميقة تحتوي على عدة طبقات من "الخلايا العصبية" الافتراضية وآلية انتباه. تتعلم هذه الطبقات علاقات معقّدة بين جوانب مختلفة من عنوان URL، مثل كيفية تداخل كلمات معينة مع سجل استضافة معين أو بنية المسار. أثناء التدريب، ترى الشبكة مئات الآلاف من الروابط الحقيقية والضارة وتعدل أوزانها الداخلية تدريجيًا لتقليل الأخطاء. والأهم من ذلك، أن النظام مصمم ليتم تحديثه مع وصول دفعات جديدة من عناوين URL، حتى يتكيف مع أنماط هجوم جديدة دون الحاجة لإعادة بنائه من الصفر.
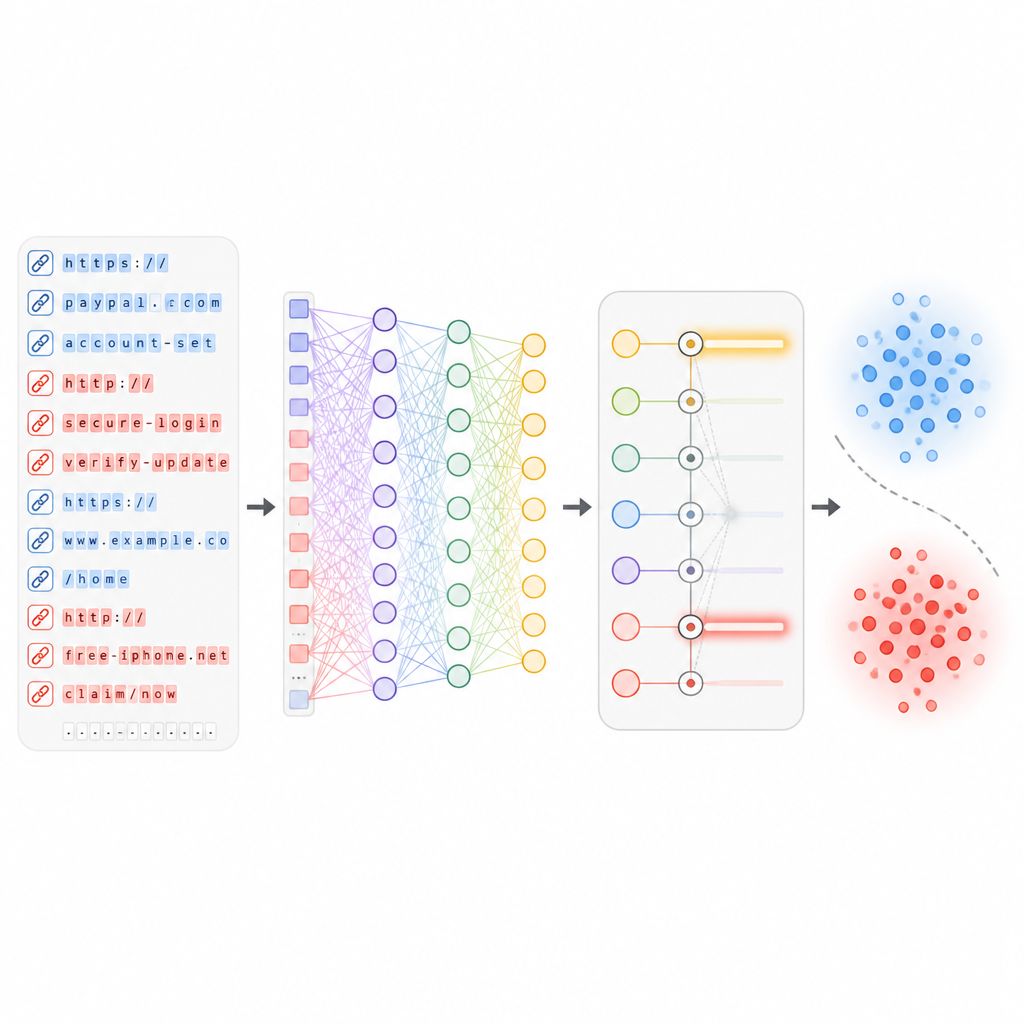
ما مدى أداء الدرع الجديد
اختبر المؤلفون ADUIN على مجموعة عامة كبيرة من عناوين URL للتصيد والشرعية جُمعت من مصادر عدة على مدى فترة زمنية. جزءوا البيانات بحيث كانت أحدث الروابط، التي لم تُشاهد أثناء التدريب، بمثابة نموذج لهجمات اليوم الصفري في العالم الحقيقي. مقارنةً بعدة أساليب تعلم آلة قوية، حقق النظام الجديد دقة إجمالية تقارب 95%، وحدد بشكل صحيح نحو 93% من الروابط المصنفة كتصيد، وكشف نحو 92% من عناوين التصيد غير المرئية سابقًا. في الوقت نفسه، تم وسم حوالي 3.5% فقط من الروابط البريئة عن طريق الخطأ كخطرة، ويمكن معالجة كل عنوان URL في نحو خُمس الثانية تقريبًا حتى تحت حمل ثقيل، مما يوحي بأن الطريقة مناسبة للبوابات عالية الحركة وشبكات المؤسسات.
ماذا يعني هذا للتصفح اليومي
لغير المتخصصين، الرسالة الأساسية هي أن الفحص الدقيق لكيفية بناء عنوان الويب يمكن أن يكشف الكثير عن نواياه. من خلال الجمع بين العديد من الدلائل الصغيرة من نص الرابط ومضيفه وبنيته، والسماح لنظام متعلم بالتكيف المستمر، يمكن للإطار المقترح أن يلتقط كلًا من الاحتيالات المألوفة وتلك الجديدة التي لم تظهر على أي قائمة سوداء من قبل. وعلى الرغم من أنه ليس علاجًا وحيدًا للتصيد، توضح ADUIN كيف يمكن للتحليل الأذكى والأسرع لعناوين URL أن يصبح طبقة مهمة في حماية مستخدمي البريد الإلكتروني والمتسوقين عبر الإنترنت والمنظمات من الخداع الذي يؤدي إلى تسليم أسرارهم.
الاستشهاد: Gobinath, R., Manikandan, S. Deep learning-based phishing classification framework for accurate detection using optimized URL intelligence. Sci Rep 16, 15794 (2026). https://doi.org/10.1038/s41598-026-46481-2
الكلمات المفتاحية: عناوين URL للتصيد, التعلم العميق, الأمن السيبراني, تحليل عناوين URL, أمن الويب