Clear Sky Science · fr
Cadre de classification du phishing basé sur l’apprentissage profond pour une détection précise utilisant une intelligence d’URL optimisée
Pourquoi les faux liens web sont un problème croissant
Chaque jour, nous cliquons sur des liens dans des courriels, des messages et des résultats de recherche sans y penser à deux fois. Derrière certains de ces liens se cachent toutefois des pièges soigneusement conçus pour voler des mots de passe, des informations bancaires ou d’autres données privées. Les attaquants modifient sans cesse l’apparence de ces adresses web factices, ce qui rend les défenses traditionnelles comme les listes noires difficiles à maintenir à jour. Cette étude présente une nouvelle méthode pour repérer automatiquement et en temps réel les liens dangereux, dans le but d’offrir aux internautes et aux organisations une protection renforcée contre les escroqueries en ligne.
Comment les escrocs en ligne se dissimulent au vu de tous
Les attaques de phishing modernes reposent rarement sur des fautes d’orthographe évidentes ou des copies grossières de sites bancaires. Elles utilisent plutôt des astuces telles que des liens très courts, des domaines changeant rapidement et des préfixes donnant une illusion de sécurité pour paraître fiables. De nombreux outils de détection existants dépendent de règles fixes ou de listes de sites connus dangereux. Ceux-ci peuvent fonctionner pour les escroqueries déjà identifiées mais ratent souvent les nouvelles, dites attaques zero-day, et peuvent signaler à tort des sites inhabituels mais inoffensifs. Les auteurs soutiennent que le web évolue désormais trop rapidement pour se reposer uniquement sur des règles faites à la main, et que les défenses doivent apprendre les motifs directement à partir des données.
Apprendre à un système à « lire » les adresses web
L’article présente une approche appelée Adaptive Deep URL Intelligence Network, ou ADUIN, qui considère chaque adresse web comme une riche source d’indices. Plutôt que de télécharger des pages complètes, le système se concentre sur trois sortes d’informations. Il étudie le texte du lien lui-même, comme sa longueur, la répartition des caractères et les mots suspects ; il examine des faits sur l’hôte du site, notamment l’ancienneté du domaine et la réputation de son adresse IP ; et il analyse la structure du lien, par exemple le nombre de sous-domaines et de dossiers ou la fréquence des redirections. Ces éléments sont convertis en nombres et combinés en une description compacte de chaque URL.
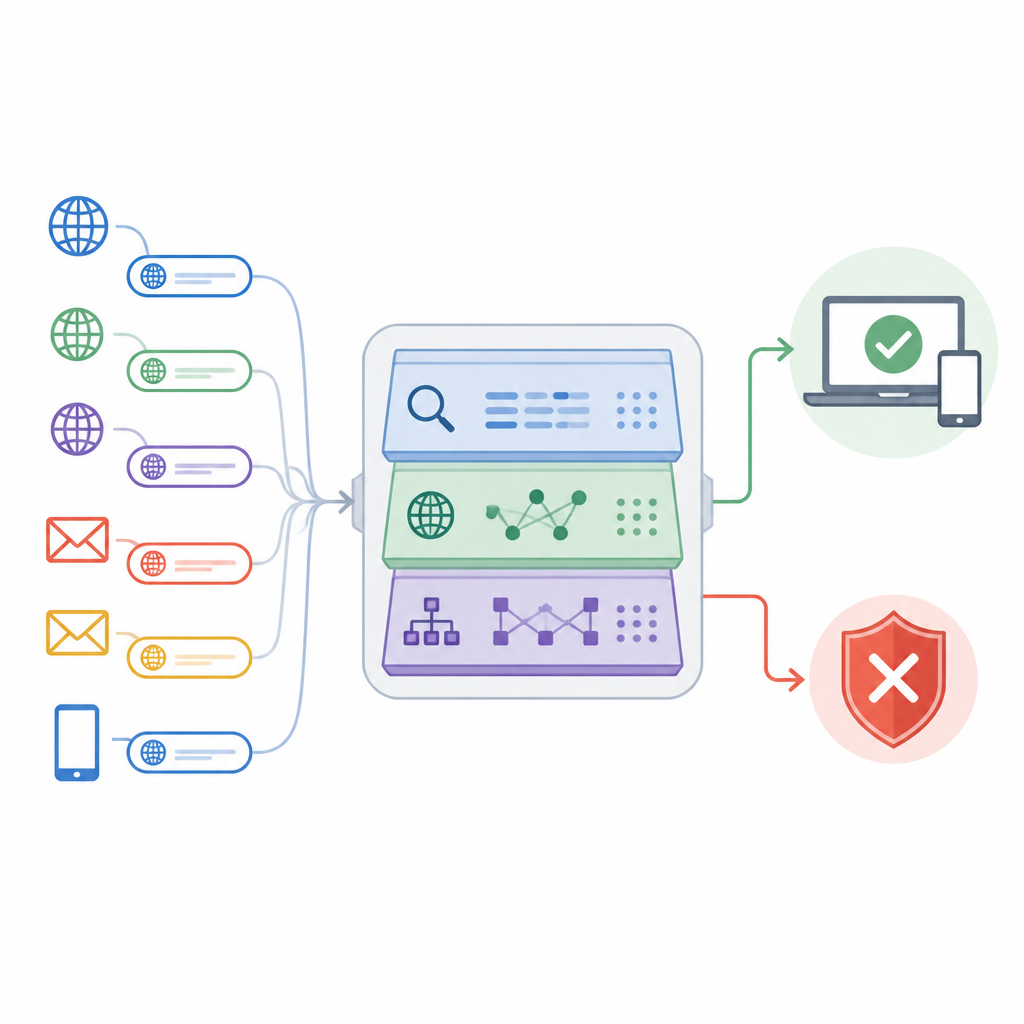
Choisir les indices les plus pertinents
La collecte de nombreux types de signaux risque d’étouffer le système dans le bruit. Pour éviter cela, les chercheurs ont créé une étape de sélection de caractéristiques qui classe chaque indice selon sa capacité à séparer les liens sûrs des liens dangereux. Des tests statistiques éliminent les mesures qui dupliquent principalement d’autres, tandis que des scores basés sur l’apprentissage mettent en évidence celles qui réduisent fortement les erreurs lorsqu’elles sont présentes. À partir d’un ensemble initial volumineux, le système conserve environ 50 des caractéristiques les plus informatives. Cet affinage accélère la détection, réduit le risque de surapprentissage lié à des particularités des données d’entraînement et préserve néanmoins les motifs qui distinguent le mieux les tentatives de phishing du trafic légitime.
Laisser l’apprentissage profond révéler les motifs cachés
Une fois les caractéristiques les plus utiles sélectionnées, elles sont injectées dans un réseau neuronal profond qui comprend plusieurs couches de « neurones » virtuels et un mécanisme d’attention. Ces couches apprennent des relations complexes entre différents aspects d’une URL, par exemple la manière dont certains mots se combinent avec un historique d’hébergement particulier ou une structure de chemin donnée. Pendant l’entraînement, le réseau voit des centaines de milliers de liens réels et malveillants et ajuste progressivement ses poids internes pour minimiser les erreurs. Il est important de noter que le système est conçu pour être mis à jour au fil de l’arrivée de nouveaux lots d’URL, afin de s’adapter aux nouveaux styles d’attaque sans devoir être reconstruit depuis zéro.
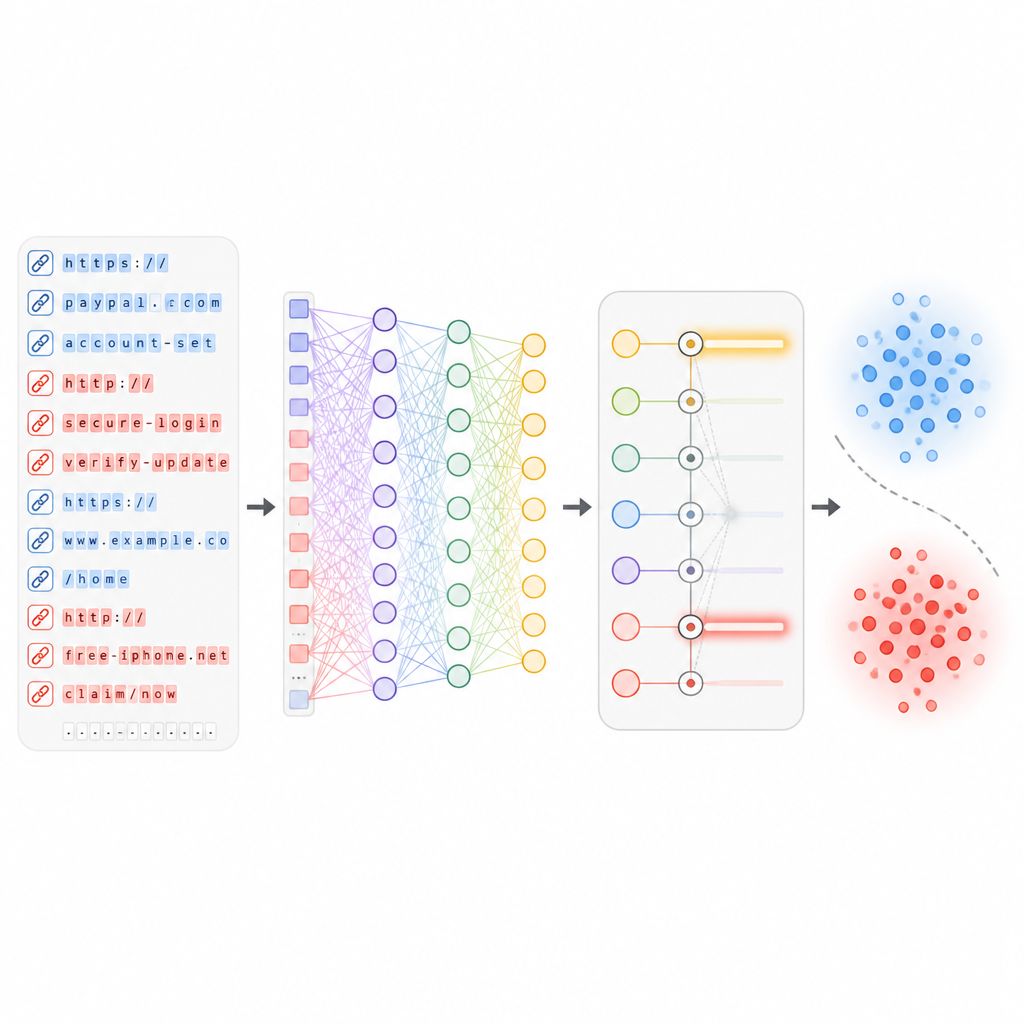
Quelle est l’efficacité de ce nouveau bouclier
Les auteurs ont testé ADUIN sur une grande collection publique d’URL de phishing et légitimes rassemblées à partir de plusieurs sources sur une période donnée. Ils ont divisé les données de sorte que les liens les plus récents, non vus durant l’entraînement, servent de substitut aux attaques zero-day du monde réel. Comparé à plusieurs solides baselines d’apprentissage automatique, le nouveau système a atteint environ 95 % de précision globale, identifié correctement près de 93 % des liens de phishing signalés et détecté environ 92 % des URL de phishing inédites. Dans le même temps, seulement environ 3,5 % des liens inoffensifs ont été étiquetés à tort comme dangereux, et chaque URL pouvait être traitée en approximativement un cinquième de seconde même sous forte charge, ce qui suggère que la méthode convient aux passerelles à fort trafic et aux réseaux d’entreprise.
Ce que cela signifie pour la navigation quotidienne
Pour les non-spécialistes, le message clé est que l’analyse attentive de la construction d’une adresse web peut révéler beaucoup sur ses intentions. En combinant de nombreux petits indices provenant du texte du lien, de son hôte et de sa structure, et en permettant à un système d’apprentissage de s’adapter en continu, le cadre proposé peut attraper à la fois les escroqueries connues et les nouvelles qui n’apparaissent sur aucune liste noire. S’il ne s’agit pas d’un remède unique contre le phishing, ADUIN montre comment une analyse d’URL plus intelligente et plus rapide peut devenir une couche importante pour protéger les utilisateurs de courriel, les acheteurs en ligne et les organisations contre le fait d’être incités à révéler leurs secrets.
Citation: Gobinath, R., Manikandan, S. Deep learning-based phishing classification framework for accurate detection using optimized URL intelligence. Sci Rep 16, 15794 (2026). https://doi.org/10.1038/s41598-026-46481-2
Mots-clés: URL de phishing, apprentissage profond, cybersécurité, analyse d’URL, sécurité web