Clear Sky Science · zh
WMambaFuse:一种基于小波曼巴的红外与可见光图像融合网络
为喧嚣世界带来更清晰的夜视
当相机在可见光和红外下观察同一场景时,每种视角揭示不同的信息:一种呈现清晰的细节与色彩,另一种在黑暗中突出热源和隐藏目标。本文提出了 WMambaFuse,一种将这两种视角融合为单一、更清晰图像的新型计算机视觉方法。目标简单却强大:通过结合两类图像的优点,帮助人类与机器在夜间、恶劣天气和复杂环境中更可靠地观察。
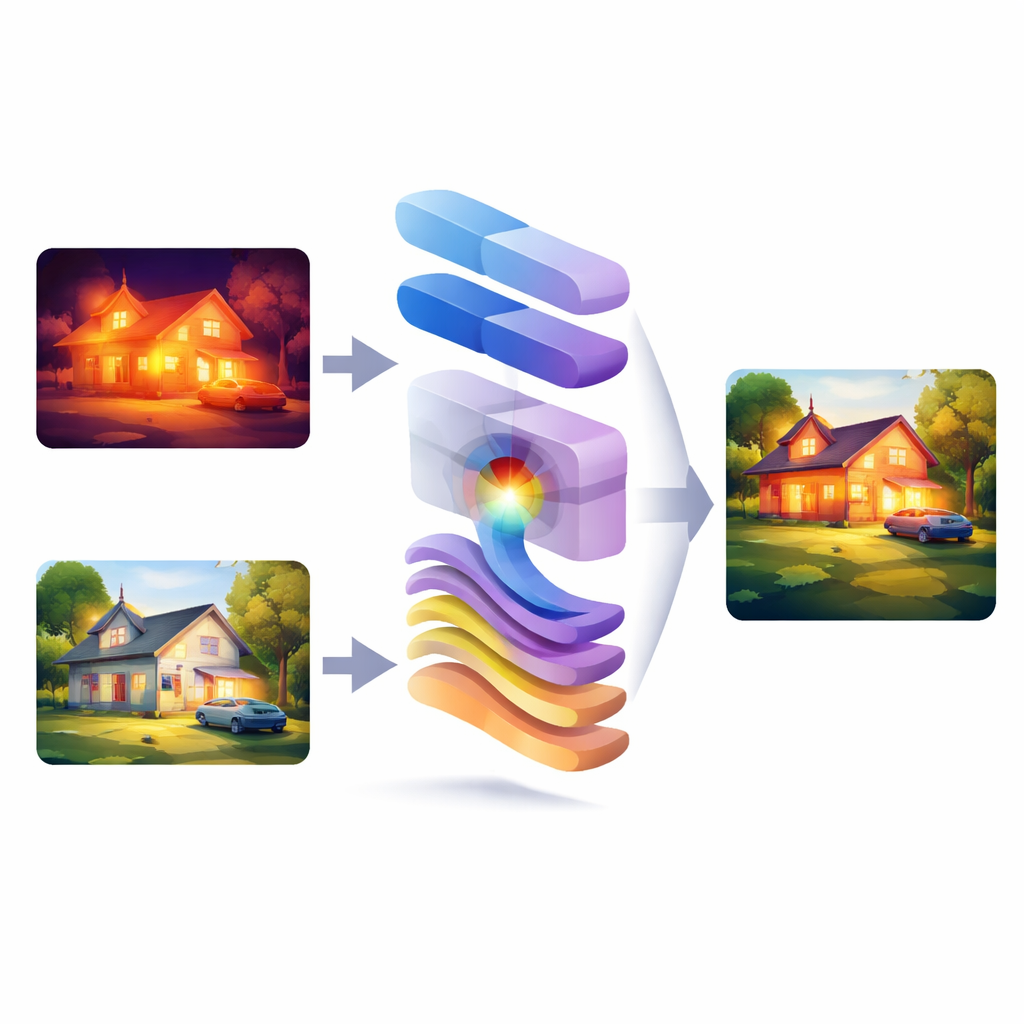
为何双眼胜过单眼
可见光相机能捕捉细腻纹理、清晰边缘和自然色彩,但在弱光、雾或眩光下表现欠佳。红外相机则相反:它们能感知热量,在黑暗中揭示人员、车辆或设备,但图像常显模糊且缺乏细节。将这两种来源融合有望兼得两者优点,但平衡并不容易。早期许多系统要么专注于图像平面的像素级混合,要么仅在频域工作,把图像分解为粗糙形状与细节模式。实际上,仅停留在单一域的方法往往会牺牲全局结构或细微细节,导致边缘丢失、纹理平淡或在复杂场景中结果不稳定。
由三部分构成的“看得更清楚”引擎
WMambaFuse 通过精心分层的设计来应对这一挑战:编码器、融合模块和解码器。编码器使用现代的“窗口化”变换器在多尺度上观察场景,同时捕捉近景纹理与更广的上下文。可以把它看成一个智能前端,学习如何表示每幅输入图像的重要特征,而无需手写规则。解码器则用递归结构重建最终的融合图像,这有助于在尺度之间保持特征一致性,并避免信息通过网络时细节丢失。两者配合起来,就像一双经过训练的眼睛与大脑,负责准备与重建视觉信息。
同时融合空间信息与细节
核心创新在于融合模块,它明确区分了“事物在哪里”和“它们有多精细”。一个分支称为空间注意力模块,直接观察图像特征并决定应从红外或可见输入中强调哪些区域。它学会突出明亮的热目标(如人员或车辆),同时保留可见视图中的细腻纹理。第二个分支在频域工作,将图像特征分解为平滑的基底层以及若干沿水平、垂直和对角方向的边缘与纹理层。在此,一个新的小波-曼巴机制将这些方向性细节带通过精简的状态空间模型,该模型可以高效追踪远程模式,在增强重要边缘的同时不过度引入噪声。
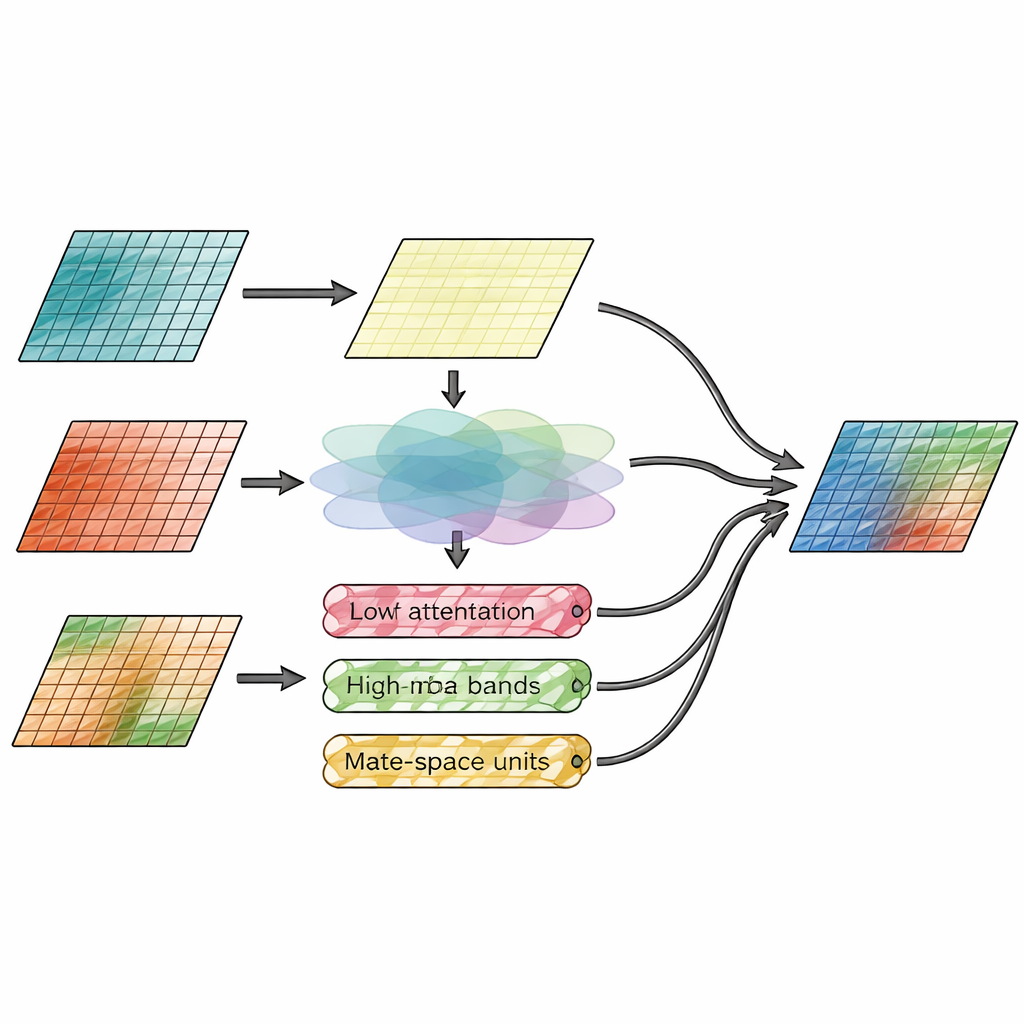
将方法付诸测试
为评估该设计是否真正有效,作者先用大规模通用图像集训练编码器—解码器,然后在成对的红外—可见场景上训练融合模块。他们在三个公开基准(涵盖军事场景、道路与日常环境)上测试 WMambaFuse,并与九种领先的融合方法比较,其中包括经典自编码器、卷积网络、变换器和早期曼巴风格模型。跨越多项指标——整体信息量、对比度、边缘清晰度以及与源图像的结构相似性——该方法始终与竞争者匹敌或优于它们。视觉示例显示了更清楚的轮廓、更明亮且更完整的热目标,以及在具有挑战性的夜间与弱光情况下更好保留的背景纹理。
为真实任务带来更清晰的融合图像
简言之,WMambaFuse 学会在何时信任热模式、何时信任可见细节,并在图像平面与编码边缘与纹理的隐性频域层面同时做出判断。其结果是一幅更易于人类解读且对后续任务(如目标检测或跟踪)更可靠的融合图像。作者指出,极端条件如浓雾或强降雨仍然是未决问题,但他们的实验表明,这种空间—频率的设计,结合现代状态空间建模,为需要在黑暗中清晰“看见”的机器提供了一个稳健的前进步骤。
引用: Wang, J., Si, Y., Chen, Y. et al. WMambaFuse: an infrared and visible image fusion network based on wavelet mamba. Sci Rep 16, 14113 (2026). https://doi.org/10.1038/s41598-026-44374-y
关键词: 红外 可见 光 融合, 夜视成像, 基于小波的图像融合, 状态空间视觉模型, 多模态计算机视觉