Clear Sky Science · es
WMambaFuse: una red de fusión de imágenes infrarrojas y visibles basada en wavelet mamba
Visión nocturna más nítida para un mundo ruidoso
Cuando las cámaras observan la misma escena con luz visible y con infrarrojos, cada vista revela verdades distintas: una muestra detalles nítidos y color, la otra resalta calor y objetos ocultos en la oscuridad. Este artículo presenta WMambaFuse, un nuevo método de visión por ordenador que combina estas dos perspectivas en una imagen única y más clara. El objetivo es simple pero potente: ayudar a personas y máquinas a ver con mayor fiabilidad durante la noche, en mal tiempo y en entornos complejos, aprovechando lo mejor de ambos tipos de imágenes.
Por qué dos ojos son mejor que uno
Las cámaras de luz visible capturan texturas finas, bordes nítidos y colores naturales, pero flaquean con poca luz, niebla o deslumbramiento. Las cámaras infrarrojas hacen lo contrario: detectan calor y pueden revelar personas, vehículos o equipos en la oscuridad, aunque sus imágenes suelen verse borrosas y con falta de detalle. Fusionar estas dos fuentes promete lo mejor de ambos mundos, pero es un equilibrio delicado. Muchos sistemas previos se centran en mezclar a nivel de píxel en el plano de la imagen o trabajan exclusivamente en el dominio de la frecuencia, donde las imágenes se descomponen en formas gruesas y patrones finos. En la práctica, los enfoques que se mantienen solo en un dominio tienden a sacrificar la estructura global o los detalles delicados, provocando pérdidas de bordes, texturas apagadas o resultados inestables en escenas complejas.
Un motor en tres partes para ver más
WMambaFuse aborda este reto con un diseño cuidadosamente estratificado: un codificador, un módulo de fusión y un decodificador. El codificador usa un transformador “windowed” moderno para observar la escena a múltiples escalas, capturando tanto la textura cercana como el contexto más amplio. Piénselo como una entrada inteligente que aprende a representar las características importantes de cada imagen de entrada sin reglas escritas a mano. El decodificador reconstruye luego la imagen fusionada final usando una estructura recurrente, lo que ayuda a mantener la coherencia de las características entre escalas y evita perder detalles a medida que la información atraviesa la red. En conjunto, estas dos partes actúan como un ojo y un cerebro altamente entrenados que preparan y reconstruyen la información visual.
Mezclando espacio y detalle a la vez
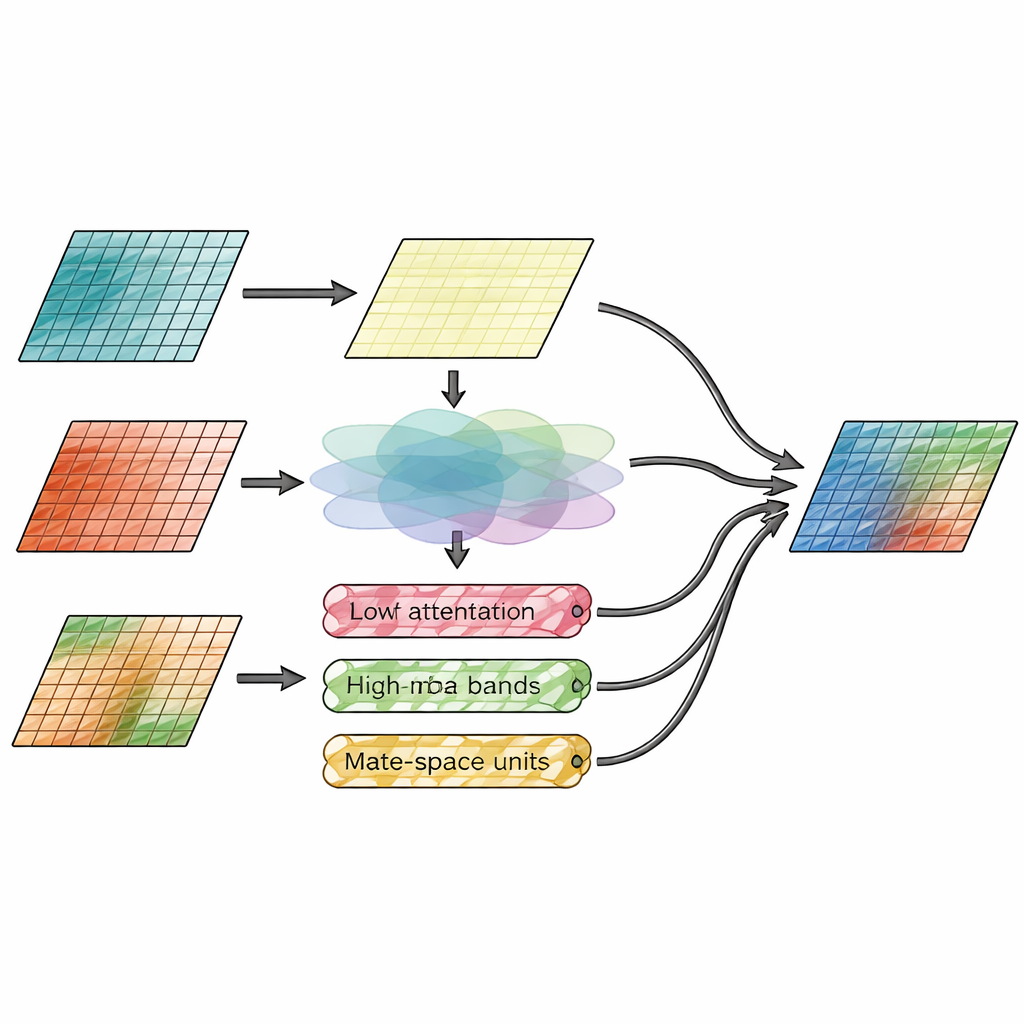
La innovación central reside en el módulo de fusión, que separa explícitamente “dónde están las cosas” de “qué tan detalladas son”. Una rama, llamada módulo de atención espacial, mira directamente las características de la imagen y decide qué regiones de las entradas infrarrojas y visibles merecen más énfasis. Aprende a resaltar objetivos térmicos brillantes, como personas o vehículos, al tiempo que preserva texturas finas de la vista visible. La segunda rama trabaja en el dominio de la frecuencia, dividiendo las características de la imagen en una capa base suave y varias capas de borde y textura en direcciones horizontal, vertical y diagonal. Aquí, un nuevo mecanismo Wavelet-Mamba pasa estas bandas direccionales de detalle a través de un modelo de espacio de estados optimizado que puede rastrear patrones de largo alcance de forma eficiente, realzando bordes importantes sin saturar la imagen de ruido.
Poniendo el método a prueba
Para evaluar si este diseño realmente ayuda, los autores entrenaron el codificador-decodificador con un gran conjunto de imágenes de uso general y luego entrenaron el módulo de fusión con escenas emparejadas infrarrojo–visible. Probaron WMambaFuse en tres benchmarks públicos que abarcan escenas militares, carreteras y entornos cotidianos, y lo compararon con nueve métodos de fusión líderes, incluidos los basados en autoencoders clásicos, redes convolucionales, transformadores y modelos estilo Mamba anteriores. En una amplia gama de medidas —información global, contraste, nitidez de bordes y similitud estructural con las fuentes— el nuevo método igualó o superó de forma consistente a los competidores. Los ejemplos visuales muestran contornos más claros, objetivos térmicos más brillantes y completos, y mejores texturas de fondo conservadas, incluso en situaciones nocturnas y de poca luz desafiantes.
Imágenes fusionadas más claras para tareas del mundo real
En términos sencillos, WMambaFuse aprende cuándo confiar en los patrones térmicos y cuándo confiar en el detalle visible, y lo hace tanto en el plano de la imagen como en las capas de frecuencia ocultas que codifican bordes y texturas. El resultado es una única imagen fusionada más fácil de interpretar para humanos y más fiable para tareas posteriores como la detección o el seguimiento de objetivos. Aunque los autores señalan que condiciones extremas, como niebla densa o lluvia intensa, siguen planteando preguntas abiertas, sus experimentos muestran que este diseño espacio–frecuencia, potenciado por modelado moderno en espacio de estados, ofrece un avance robusto para las máquinas que necesitan ver con claridad en la oscuridad.
Cita: Wang, J., Si, Y., Chen, Y. et al. WMambaFuse: an infrared and visible image fusion network based on wavelet mamba. Sci Rep 16, 14113 (2026). https://doi.org/10.1038/s41598-026-44374-y
Palabras clave: fusión infrarrojo-visible, imágenes para visión nocturna, fusión de imágenes basada en wavelets, modelos de visión en espacio de estados, visión por ordenador multimodal