Clear Sky Science · pt
WMambaFuse: uma rede de fusão de imagens infravermelhas e visíveis baseada em wavelet mamba
Visão noturna mais nítida para um mundo barulhento
Quando câmeras observam a mesma cena em luz visível e em infravermelho, cada visão revela verdades diferentes: uma mostra detalhes nítidos e cores, a outra destaca calor e objetos ocultos no escuro. Este artigo apresenta o WMambaFuse, um novo método em visão computacional que combina essas duas perspectivas em uma única imagem mais clara. O objetivo é simples, mas potente: ajudar pessoas e máquinas a enxergarem com mais confiabilidade durante a noite, em mau tempo e em ambientes complexos, reunindo o melhor de ambos os tipos de imagem.
Por que dois olhos são melhores do que um
Câmeras de luz visível capturam texturas finas, bordas nítidas e cores naturais, mas falham em pouca luz, neblina ou ofuscamento. Câmeras infravermelhas fazem o oposto: detectam calor e podem revelar pessoas, veículos ou equipamentos no escuro, porém suas imagens costumam ser borradas e com poucos detalhes. Fundir essas duas fontes promete o melhor dos dois mundos, mas é um equilíbrio delicado. Muitos sistemas anteriores se concentram ou na mistura ao nível de pixel no plano da imagem, ou trabalham puramente no domínio da frequência, onde as imagens são decompostas em formas grossas e padrões finos. Na prática, abordagens que ficam em apenas um domínio tendem a sacrificar a estrutura global ou os detalhes delicados, levando à perda de bordas, texturas desbotadas ou resultados instáveis em cenas complexas.
Um motor em três partes para ver mais
O WMambaFuse enfrenta esse desafio com um projeto cuidadosamente em camadas: um codificador, um módulo de fusão e um decodificador. O codificador usa um transformer “com janelas” moderno para observar a cena em múltiplas escalas, capturando tanto texturas próximas quanto contexto mais amplo. Pense nele como uma entrada inteligente que aprende a representar as características importantes de cada imagem de entrada sem regras escritas à mão. O decodificador reconstrói a imagem fundida final usando uma estrutura recorrente, o que ajuda a manter as características consistentes entre escalas e evita a perda de detalhes à medida que a informação percorre a rede. Juntas, essas duas partes atuam como um olho e um cérebro altamente treinados que preparam e reconstruem a informação visual.
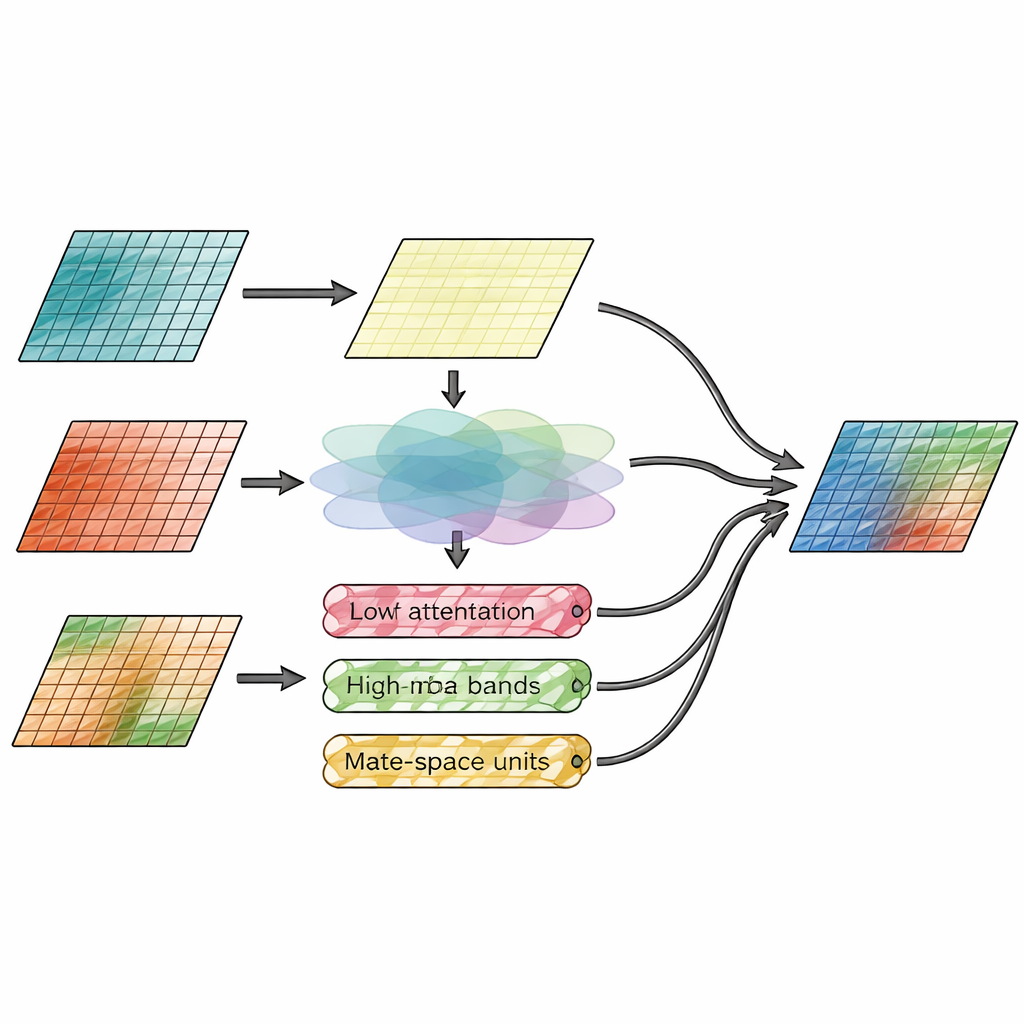
Misturando espaço e detalhe ao mesmo tempo
A inovação central está no módulo de fusão, que separa explicitamente “onde as coisas estão” de “quão detalhadas elas são”. Um ramo, chamado módulo de atenção espacial, olha diretamente para as características da imagem e decide quais regiões dos insumos infravermelho e visível merecem mais ênfase. Ele aprende a ressaltar alvos térmicos brilhantes, como pessoas ou veículos, ao mesmo tempo que preserva texturas finas da visão visível. O segundo ramo trabalha no domínio da frequência, dividindo as características da imagem em uma camada base suave e várias camadas de bordas e texturas nas direções horizontal, vertical e diagonal. Aqui, um novo mecanismo Wavelet-Mamba passa essas bandas de detalhe direcionais por um modelo em espaço de estados simplificado que pode rastrear padrões de longo alcance de forma eficiente, realçando bordas importantes sem sobrecarregar a imagem com ruído.
Submetendo o método ao teste
Para avaliar se esse projeto realmente ajuda, os autores treinaram o codificador-decodificador em um grande conjunto de imagens de uso geral e depois treinaram o módulo de fusão em cenas pareadas infravermelho–visível. Eles testaram o WMambaFuse em três benchmarks públicos cobrindo cenas militares, rodovias e ambientes cotidianos, e o compararam com nove métodos de fusão líderes, incluindo aqueles baseados em autoencoders clássicos, redes convolucionais, transformers e modelos estilo Mamba anteriores. Em uma ampla gama de métricas — informação geral, contraste, nitidez de bordas e similaridade estrutural com as fontes — o novo método consistentemente igualou ou superou os concorrentes. Exemplos visuais mostram contornos mais claros, alvos térmicos mais brilhantes e completos e texturas de fundo melhor preservadas, mesmo em situações desafiadoras de noite e pouca luz.
Imagens fundidas mais claras para tarefas do mundo real
Em termos simples, o WMambaFuse aprende quando confiar em padrões de calor e quando confiar em detalhes visíveis, e faz isso tanto no plano da imagem quanto nas camadas ocultas de frequência que codificam bordas e texturas. O resultado é uma única imagem fundida que é mais fácil de interpretar por humanos e mais confiável para tarefas a jusante, como detecção ou rastreamento de alvos. Embora os autores observem que condições extremas, como neblina densa ou chuva intensa, ainda apresentam questões em aberto, seus experimentos mostram que esse projeto espacial–frequencial, impulsionado por modelagem moderna em espaço de estados, oferece um avanço robusto para máquinas que precisam ver claramente no escuro.
Citação: Wang, J., Si, Y., Chen, Y. et al. WMambaFuse: an infrared and visible image fusion network based on wavelet mamba. Sci Rep 16, 14113 (2026). https://doi.org/10.1038/s41598-026-44374-y
Palavras-chave: fusão infravermelho visível, imagens para visão noturna, fusão de imagens baseada em wavelet, modelos de visão em espaço de estados, visão computacional multimodal