Clear Sky Science · sv
WMambaFuse: ett fusionsnätverk för infrarött och synligt ljus baserat på wavelet-mamba
Skarpare nattseende för en bullrig värld
När kameror betraktar samma scen i normalt ljus och i infrarött avslöjar varje vy olika sanningar: den ena visar skarpa detaljer och färg, den andra framhäver värme och dolda objekt i mörkret. Denna artikel presenterar WMambaFuse, en ny metod inom datorseende som smälter samman dessa två perspektiv till en enda, klarare bild. Målet är enkelt men kraftfullt: hjälpa människor och maskiner att se mer pålitligt på natten, i dåligt väder och i komplexa miljöer genom att kombinera det bästa från båda bildtyperna.
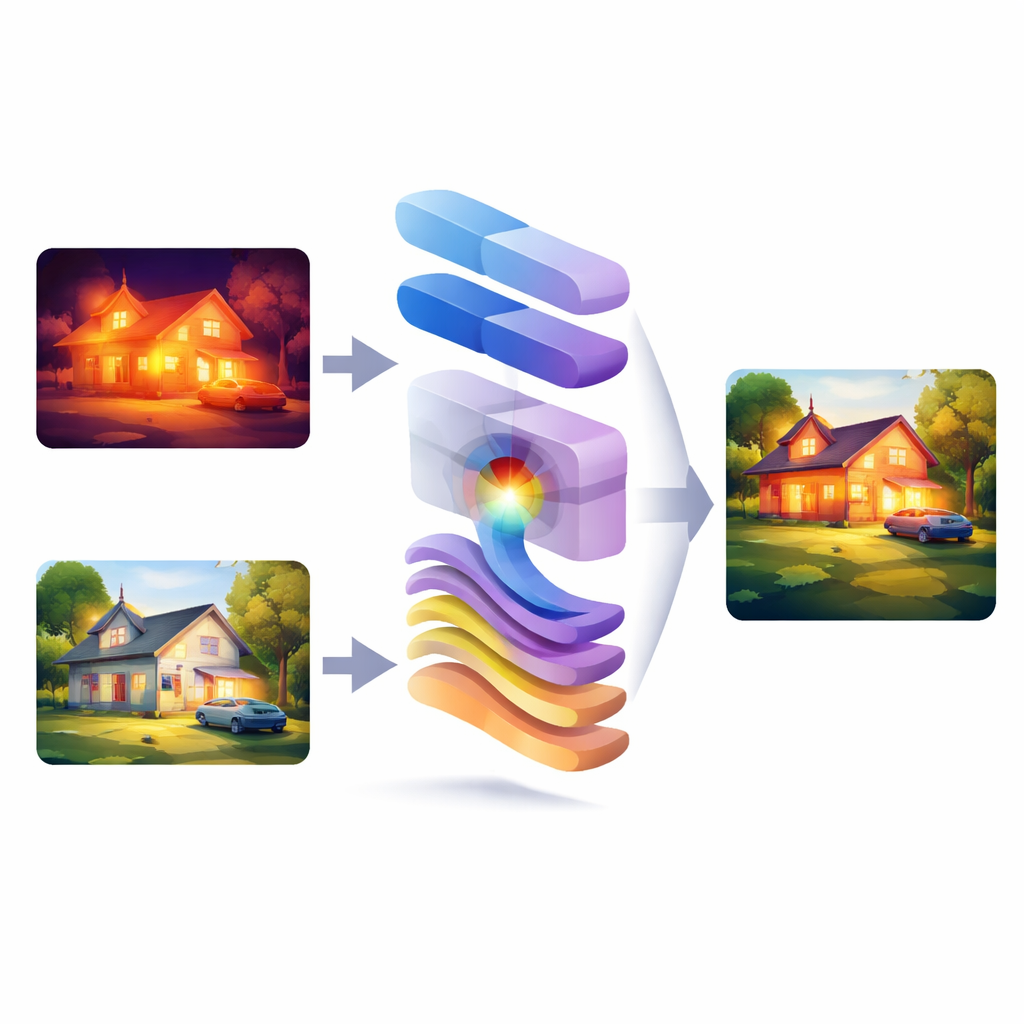
Därför är två ögon bättre än ett
Kameror för synligt ljus fångar fina texturer, skarpa kanter och naturliga färger, men de sviker i svagt ljus, dimma eller bländning. Infraröda kameror gör tvärtom: de känner av värme och kan avslöja människor, fordon eller utrustning i mörker, men deras bilder är ofta suddiga och saknar detalj. Genom att foga samman dessa två källor kan man få det bästa av båda världarna, men det är en svår balansgång. Många tidigare system fokuserar antingen på pixelvis blandning i bildplanet eller arbetar enbart i frekvensdomänen, där bilder bryts ner i grova former och fina mönster. I praktiken tenderar metoder som stannar i bara en domän att offra antingen global struktur eller fina detaljer, vilket leder till förlorade kanter, urvattnade texturer eller instabila resultat i komplexa scener.
En tredelad motor för bättre seende
WMambaFuse tar sig an denna utmaning med en noggrant lageruppbyggd design: en encoder, en fusionsmodul och en decoder. Encodern använder en modern "windowed" transformer för att betrakta scenen i flera skalor och fånga både närliggande textur och bredare kontext. Tänk på den som en smart front som lär sig representera viktiga drag i varje ingångsbild utan handskrivna regler. Decodern rekonstruerar sedan den slutliga sammansatta bilden med en rekurrent struktur, vilket hjälper till att hålla funktioner konsekventa över skalor och undviker att detaljer går förlorade när information passerar genom nätverket. Tillsammans fungerar dessa två delar som ett högt tränat öga och en hjärna som förbereder och återskapar den visuella informationen.
Att blanda rumslighet och detalj samtidigt
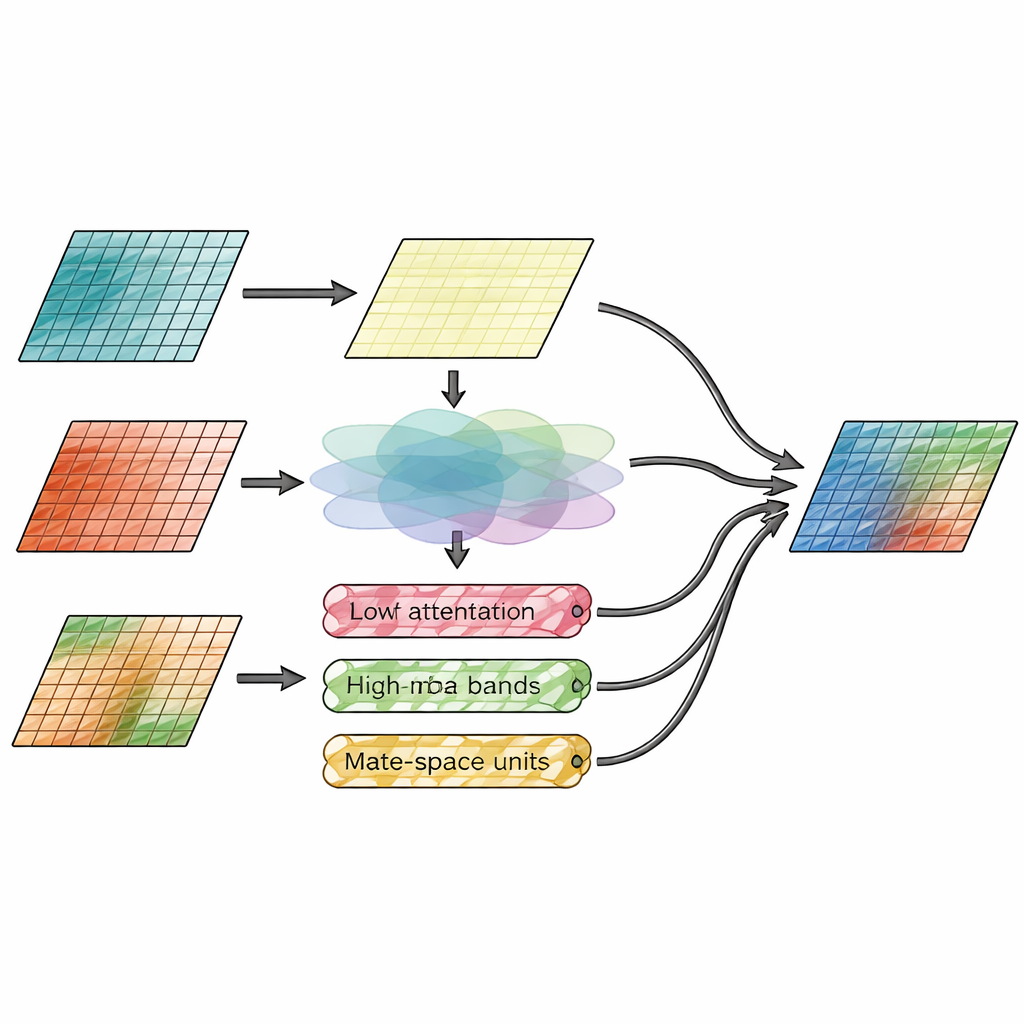
Kärninnovationen ligger i fusionsmodulen, som uttryckligen separerar ”var saker finns” från ”hur detaljerade de är”. En gren, kallad spatial attention-modul, ser direkt på bildfunktionerna och bestämmer vilka regioner från infraröda och synliga ingångar som förtjänar mer fokus. Den lär sig att framhäva ljusa termiska mål, som människor eller fordon, samtidigt som den bevarar fina texturer från den synliga vyn. Den andra grenen arbetar i frekvensdomänen och delar bildfunktionerna i ett slätt baslager och flera kant- och texturlager i horisontell, vertikal och diagonal riktning. Här för vidare en ny Wavelet-Mamba-mekanism dessa riktade detaljbands genom en strömlinjeformad state-space-modell som effektivt kan följa långräckande mönster, vilket förstärker viktiga kanter utan att överväldiga bilden med brus.
Sätta metoden på prov
För att bedöma om denna design verkligen hjälper tränade författarna encoder-decoder på ett stort, allmänt bildmaterial och tränade sedan fusionsmodulen på parade infraröda–synliga scener. De testade WMambaFuse på tre offentliga benchmark-dataset som täcker militära scener, vägar och vardagsmiljöer, och jämförde den med nio ledande fusionsmetoder, inklusive dem baserade på klassiska autoenkodare, konvolutionsnätverk, transformrar och tidigare Mamba-stilmodeller. Över en rad olika mått—övergripande information, kontrast, kantskärpa och strukturell likhet med källorna—matchade eller överträffade den nya metoden konsekvent konkurrenterna. Visuella exempel visar tydligare konturer, ljusare och mer fullständiga termiska mål samt bättre bevarade bakgrundstexturer, även i utmanande natt- och svagt ljusa situationer.
Tydligare sammansatta bilder för verkliga uppgifter
Enkelt uttryckt lär sig WMambaFuse när den ska lita på värmemönster och när den ska lita på synlig detalj, och den gör det både i bildplanet och i de dolda frekvenslagren som kodar kanter och texturer. Resultatet blir en enda sammansatt bild som är lättare för människor att tolka och mer tillförlitlig för efterföljande uppgifter som måldetektion eller spårning. Författarna noterar att extrema förhållanden, som tät dimma eller intensivt regn, fortfarande utgör öppna frågor, men deras experiment visar att denna spatial–frekvens-design, driven av modern state-space-modellering, utgör ett robust steg framåt för maskiner som behöver se tydligt i mörkret.
Citering: Wang, J., Si, Y., Chen, Y. et al. WMambaFuse: an infrared and visible image fusion network based on wavelet mamba. Sci Rep 16, 14113 (2026). https://doi.org/10.1038/s41598-026-44374-y
Nyckelord: fusion infrarött synligt, nattvisionsavbildning, wavelet-baserad bildfusion, state space-visionsmodeller, multimodal datorseende