Clear Sky Science · it
WMambaFuse: una rete di fusione di immagini infrarosse e visibili basata su wavelet mamba
Visione notturna più nitida per un mondo rumoroso
Quando le camere osservano la stessa scena alla luce normale e in infrarosso, ogni prospettiva rivela verità diverse: una mostra dettagli nitidi e colori, l’altra mette in evidenza il calore e oggetti nascosti nell’oscurità. Questo articolo presenta WMambaFuse, un nuovo metodo di visione artificiale che fonde queste due prospettive in un’unica immagine più chiara. L’obiettivo è semplice ma potente: aiutare persone e macchine a vedere in modo più affidabile di notte, in condizioni meteo avverse e in ambienti complessi combinando i pregi di entrambi i tipi di immagini.
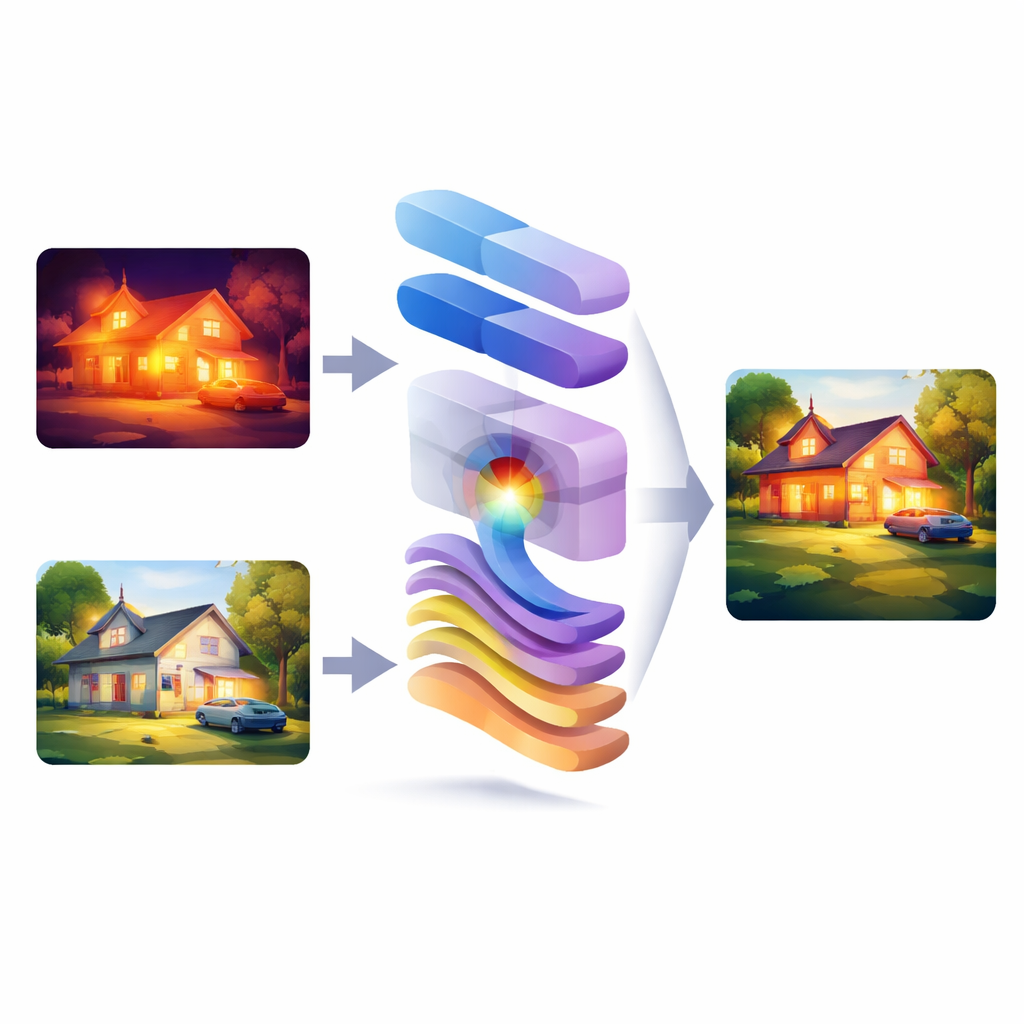
Perché due occhi valgono più di uno
Le camere a luce visibile catturano texture fini, contorni netti e colori naturali, ma non funzionano bene in bassa luminosità, nebbia o controluce. Le camere a infrarossi fanno l’opposto: rilevano il calore e possono rivelare persone, veicoli o attrezzature al buio, ma le loro immagini spesso risultano sfocate e ricche di pochi dettagli. Fondere queste due sorgenti promette il meglio di entrambi i mondi, ma è un equilibrio difficile. Molti sistemi precedenti operano o a livello di miscelazione dei pixel nel piano immagine o solo nel dominio delle frequenze, dove le immagini vengono scomposte in forme grossolane e pattern fini. Nella pratica, gli approcci che restano esclusivamente in un dominio tendono a sacrificare o la struttura globale o i dettagli delicati, causando perdita di bordi, texture spente o risultati instabili in scene complesse.
Un motore in tre parti per vedere di più
WMambaFuse affronta questa sfida con un design stratificato: un encoder, un modulo di fusione e un decoder. L’encoder utilizza un moderno trasformatore “windowed” per osservare la scena a più scale, catturando sia texture ravvicinate sia contesti più ampi. Pensatelo come un front-end intelligente che impara a rappresentare le caratteristiche importanti di ogni immagine di input senza regole scritte a mano. Il decoder ricostruisce poi l’immagine finale fusa usando una struttura ricorrente, che aiuta a mantenere la coerenza delle caratteristiche tra le scale ed evita la perdita di dettagli man mano che l’informazione scorre nella rete. Insieme, queste due parti funzionano come un occhio e un cervello altamente addestrati che preparano e ricostruiscono l’informazione visiva.
Fondere spazio e dettaglio allo stesso tempo
L’innovazione centrale risiede nel modulo di fusione, che separa esplicitamente “dove sono le cose” da “quanto sono dettagliate”. Un ramo, chiamato modulo di attenzione spaziale, osserva direttamente le caratteristiche dell’immagine e decide quali regioni degli input infrarosso e visibile meritano maggiore enfasi. Impara a evidenziare bersagli termici luminosi, come persone o veicoli, preservando al contempo le texture fini della vista visibile. Il secondo ramo opera nel dominio delle frequenze, suddividendo le caratteristiche dell’immagine in uno strato di base liscio e diversi strati di bordo e texture lungo direzioni orizzontali, verticali e diagonali. Qui, un nuovo meccanismo Wavelet-Mamba passa queste bande di dettaglio direzionali attraverso un modello a spazio di stato snellito che può tracciare schemi a lungo raggio in modo efficiente, migliorando i bordi importanti senza sovraccaricare l’immagine di rumore.
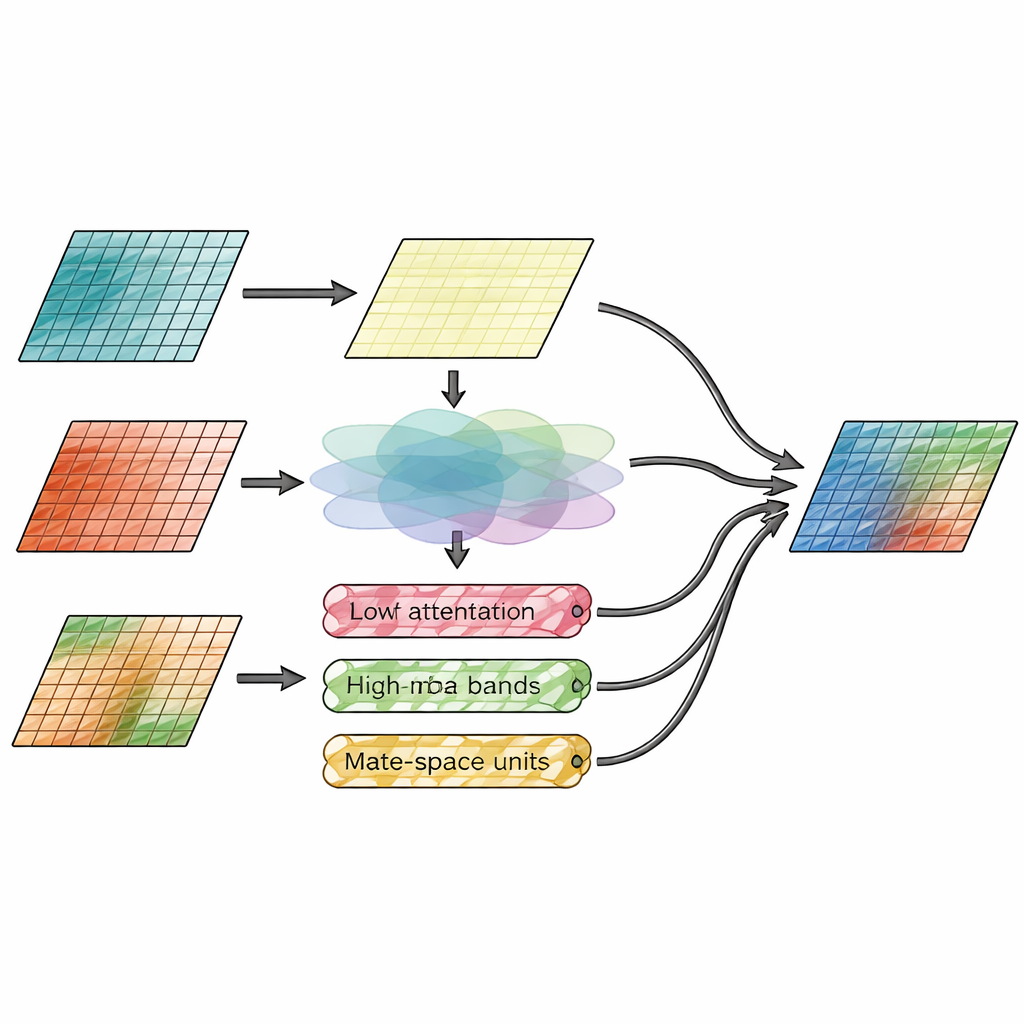
Mettere il metodo alla prova
Per valutare se questo design funziona davvero, gli autori hanno addestrato l’encoder-decoder su un ampio set di immagini generico e poi hanno addestrato il modulo di fusione su scene infrarosso–visibili abbinate. Hanno testato WMambaFuse su tre benchmark pubblici che coprono scene militari, strade e ambienti quotidiani, confrontandolo con nove metodi di fusione di punta, inclusi quelli basati su autoencoder classici, reti convoluzionali, trasformatori e modelli in stile Mamba precedenti. Su un’ampia gamma di misure — informazione complessiva, contrasto, nitidezza dei bordi e somiglianza strutturale alle sorgenti — il nuovo metodo ha costantemente eguagliato o superato i concorrenti. Esempi visivi mostrano contorni più netti, bersagli termici più luminosi e completi e texture di sfondo meglio conservate, anche in situazioni notturne e di scarsa illuminazione difficili.
Immagini fuse più chiare per compiti nel mondo reale
In termini semplici, WMambaFuse impara quando fidarsi dei pattern termici e quando fidarsi del dettaglio visibile, e lo fa sia nel piano immagine sia negli strati nascosti di frequenza che codificano bordi e texture. Il risultato è un’unica immagine fusa più facile da interpretare per gli esseri umani e più affidabile per compiti a valle come rilevamento o tracciamento di obiettivi. Pur riconoscendo che condizioni estreme, come nebbia fitta o pioggia intensa, restano sfide aperte, i loro esperimenti mostrano che questo design spazio–frequenza, potenziato dal moderno modellamento a spazio di stato, rappresenta un passo robusto in avanti per le macchine che devono vedere chiaramente al buio.
Citazione: Wang, J., Si, Y., Chen, Y. et al. WMambaFuse: an infrared and visible image fusion network based on wavelet mamba. Sci Rep 16, 14113 (2026). https://doi.org/10.1038/s41598-026-44374-y
Parole chiave: fusione infrarosso-visibile, imaging per visione notturna, fusione di immagini basata su wavelet, modelli di visione a spazio di stato, visione artificiale multimodale