Clear Sky Science · de
WMambaFuse: ein Infrarot- und Sichtbild-Fusionsnetzwerk basierend auf Wavelet-Mamba
Schärfere Nachtsicht für eine laute Welt
Wenn Kameras dieselbe Szene im sichtbaren Licht und im Infrarot betrachten, offenbart jede Ansicht andere Wahrheiten: Die eine zeigt feine Details und Farbe, die andere hebt Wärme und im Dunkeln verborgene Objekte hervor. Dieses Paper stellt WMambaFuse vor, eine neue Computer-Vision-Methode, die diese beiden Perspektiven zu einem einzigen, klareren Bild verschmilzt. Das Ziel ist einfach, aber wirkungsvoll: Menschen und Maschinen helfen, nachts, bei schlechtem Wetter und in komplexen Umgebungen zuverlässiger zu sehen, indem das Beste aus beiden Bildarten kombiniert wird.
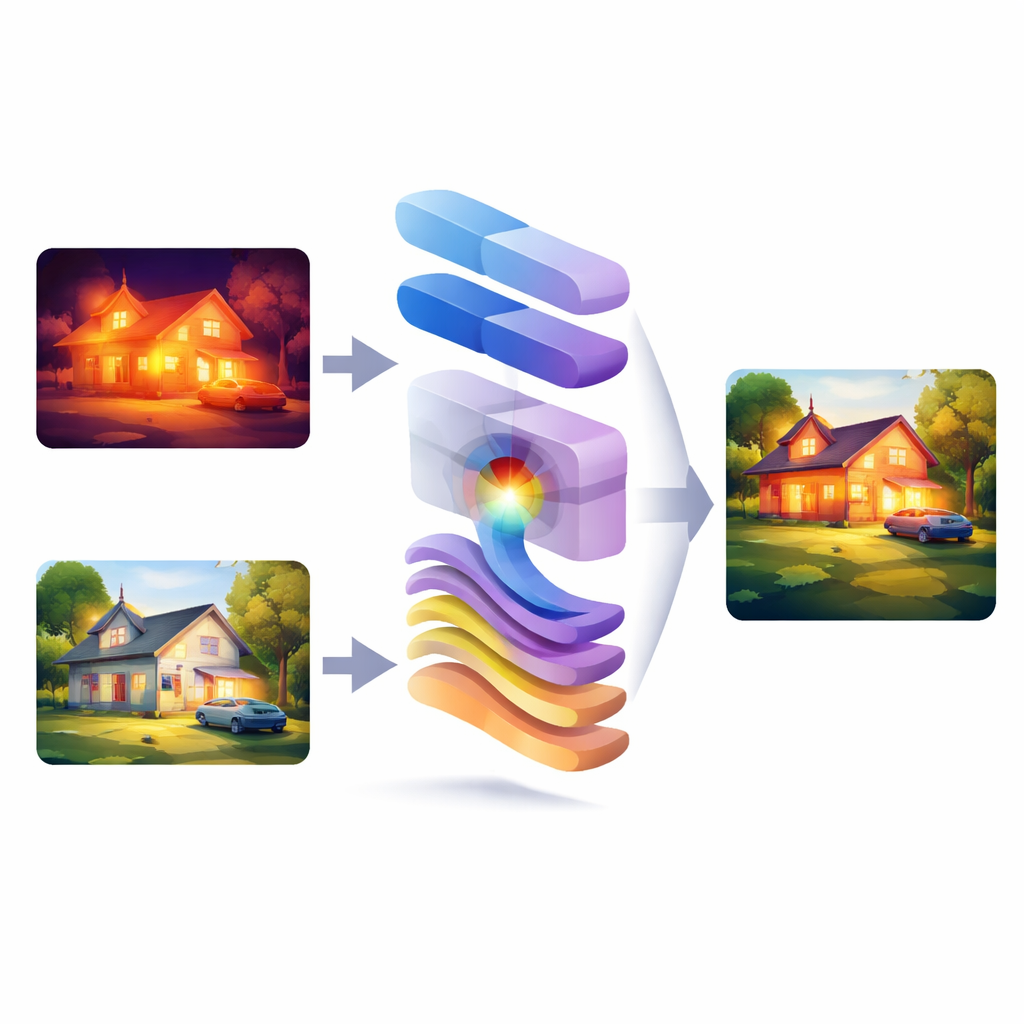
Warum zwei Augen besser sind als eines
Sichtbare Lichtkameras erfassen feine Texturen, scharfe Kanten und natürliche Farben, versagen jedoch bei schwachem Licht, Nebel oder Blendung. Infrarotkameras leisten das Gegenteil: Sie erfassen Wärme und können Personen, Fahrzeuge oder Ausrüstung in der Dunkelheit sichtbar machen, doch ihre Bilder wirken oft verschwommen und detailarm. Die Fusion dieser beiden Quellen verspricht das Beste aus beiden Welten, ist aber eine heikle Balance. Viele frühere Systeme konzentrieren sich entweder auf das Mischen auf Pixelebene in der Bildebene oder arbeiten ausschließlich im Frequenzbereich, in dem Bilder in grobe Formen und feine Muster zerlegt werden. In der Praxis neigen Ansätze, die nur in einem dieser Bereiche verbleiben, dazu, entweder die globale Struktur oder die feinen Details zu opfern, was zu verlorenen Kanten, ausgewaschenen Texturen oder instabilen Ergebnissen in komplexen Szenen führt.
Ein dreiteiliger Motor, um mehr zu sehen
WMambaFuse geht diese Herausforderung mit einem sorgfältig geschichteten Design an: einem Encoder, einem Fusionsmodul und einem Decoder. Der Encoder verwendet einen modernen „windowed“ Transformer, um die Szene auf mehreren Skalen zu betrachten und sowohl Nahtextur als auch breiteren Kontext zu erfassen. Man kann ihn sich als eine intelligente Vorderstufe vorstellen, die lernt, die wichtigen Merkmale jedes Eingangsbildes ohne handschriftliche Regeln darzustellen. Der Decoder rekonstruiert dann das finale fusionierte Bild mithilfe einer rekurrenten Struktur, die hilft, Merkmale über Skalen hinweg konsistent zu halten und zu vermeiden, dass Details verloren gehen, während Informationen durch das Netzwerk fließen. Zusammen wirken diese beiden Teile wie ein hochtrainiertes Auge und Gehirn, die die visuellen Informationen aufbereiten und wiederherstellen.
Raum und Detail gleichzeitig mischen
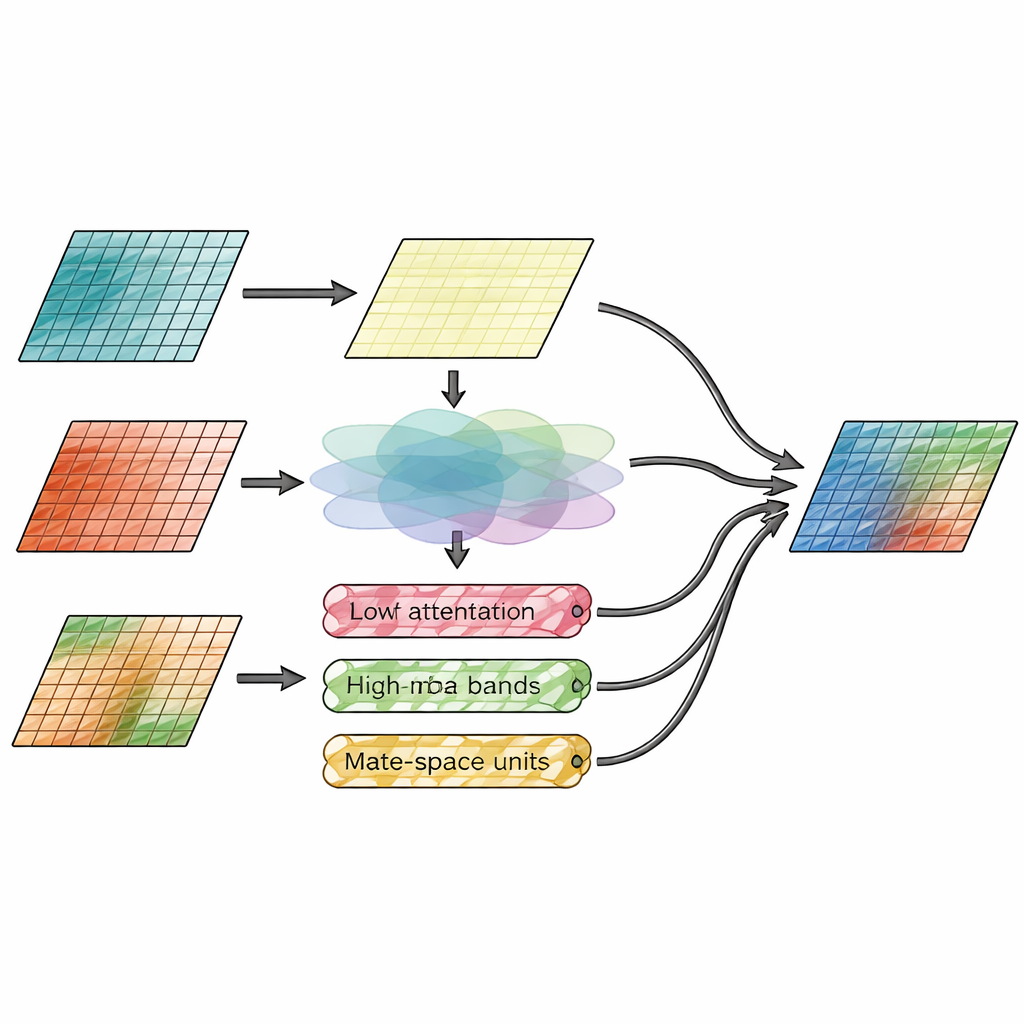
Die Kerninnovation liegt im Fusionsmodul, das explizit „wo Dinge sind“ von „wie detailliert sie sind“ trennt. Ein Zweig, das räumliche Aufmerksamkeitsmodul, schaut direkt auf die Bildmerkmale und entscheidet, welche Regionen aus Infrarot- und Sichtbildern mehr Gewicht verdienen. Es lernt, helle thermische Ziele wie Personen oder Fahrzeuge hervorzuheben und gleichzeitig feine Texturen aus der sichtbaren Ansicht zu bewahren. Der zweite Zweig arbeitet im Frequenzbereich und teilt Bildmerkmale in eine glatte Basisschicht sowie mehrere Kanten- und Texturschichten in horizontaler, vertikaler und diagonaler Richtung auf. Hier leitet ein neuer Wavelet-Mamba-Mechanismus diese gerichteten Detailbänder durch ein schlankes State-Space-Modell, das langfristige Muster effizient verfolgen kann und wichtige Kanten hervorhebt, ohne das Bild mit Rauschen zu überfrachten.
Die Methode im Test
Um zu beurteilen, ob dieses Design wirklich hilft, trainierten die Autoren den Encoder-Decoder auf einem großen, allgemein verwendeten Bildsatz und trainierten anschließend das Fusionsmodul auf gepaarten Infrarot–Sicht-Szenen. Sie testeten WMambaFuse auf drei öffentlichen Benchmarks, die militärische Szenen, Straßen und alltägliche Umgebungen abdecken, und verglichen es mit neun führenden Fusionsmethoden, darunter solche auf Basis klassischer Autoencoder, Convolutional Networks, Transformern und früheren Mamba-artigen Modellen. Über eine breite Palette von Messgrößen hinweg — Gesamtinformation, Kontrast, Kantenschärfe und strukturelle Ähnlichkeit zu den Quellen — übertraf oder erreichte die neue Methode durchweg die Konkurrenz. Visuelle Beispiele zeigen klarere Konturen, hellere und vollständigere thermische Ziele sowie besser erhaltene Hintergrundtexturen, selbst in herausfordernden Nacht- und Schwachlichtsituationen.
Klarere fusionierte Bilder für reale Aufgaben
Einfach gesagt lernt WMambaFuse, wann Wärmebilder und wann sichtbare Details zu vertrauen sind, und tut dies sowohl in der Bildebene als auch in den verborgenen Frequenzschichten, die Kanten und Texturen kodieren. Das Ergebnis ist ein einzelnes fusioniertes Bild, das für Menschen leichter zu interpretieren und für nachgelagerte Aufgaben wie Zielerkennung oder Tracking zuverlässiger ist. Obwohl die Autoren darauf hinweisen, dass extreme Bedingungen wie dichter Nebel oder starker Regen weiterhin offene Fragen bleiben, zeigen ihre Experimente, dass dieses Raum–Frequenz-Design, gestützt durch moderne State-Space-Modellierung, einen robusten Fortschritt für Maschinen darstellt, die nachts klar sehen müssen.
Zitation: Wang, J., Si, Y., Chen, Y. et al. WMambaFuse: an infrared and visible image fusion network based on wavelet mamba. Sci Rep 16, 14113 (2026). https://doi.org/10.1038/s41598-026-44374-y
Schlüsselwörter: fusion von infrarot und sichtbar, Nachtsichtbildgebung, wavelet-basierte Bildfusion, State-Space-Visionsmodelle, multimodale Computer Vision