Clear Sky Science · nl
WMambaFuse: een infrarood- en zichtbaarbeeld-fusienetwerk gebaseerd op wavelet mamba
Scherper nachtzicht voor een rumoerige wereld
Wanneer camera’s naar dezelfde scène kijken in zichtbaar licht en in het infrarood, onthult elk beeld andere waarheden: het ene toont scherpe details en kleur, het andere markeert warmte en verborgen objecten in het donker. Dit artikel introduceert WMambaFuse, een nieuwe computervisiemethode die deze twee perspectieven mengt tot één duidelijker beeld. Het doel is eenvoudig maar krachtig: mensen en machines helpen om betrouwbaarder te zien ’s nachts, bij slecht weer en in complexe omgevingen door het beste van beide beeldtypen te combineren.
Waarom twee ogen beter zijn dan één
Camera’s voor zichtbaar licht vangen fijne texturen, scherpe randen en natuurlijke kleuren, maar ze falen bij weinig licht, mist of schittering. Infraroodcamera’s doen het tegenovergestelde: ze registreren warmte en kunnen mensen, voertuigen of apparatuur in het donker zichtbaar maken, maar hun beelden zijn vaak onscherp en missen detail. Het samenvoegen van deze twee bronnen belooft het beste van beide werelden, maar het is een delicate balans. Veel eerdere systemen richten zich ofwel op pixelniveau-mixing in het beeldvlak of werken puur in het frequentiedomein, waar beelden worden opgesplitst in grove vormen en fijne patronen. In de praktijk zorgen benaderingen die slechts in één domein blijven er vaak voor dat ofwel de globale structuur of wel de fijne details verloren gaan, wat leidt tot wegvallende randen, uitgeveegde texturen of instabiele resultaten in complexe scènes.
Een drietalige motor om meer te zien
WMambaFuse pakt deze uitdaging aan met een zorgvuldig gelaagd ontwerp: een encoder, een fusiemodule en een decoder. De encoder gebruikt een moderne “windowed” transformer om de scène op meerdere schalen te bekijken, en vangt zowel close-up textuur als bredere context. Zie het als een slimme front-end die leert hoe de belangrijke kenmerken van elke invoerafbeelding te representeren zonder handgeschreven regels. De decoder reconstrueert vervolgens het uiteindelijke gefuseerde beeld met een recurrente structuur, wat helpt om kenmerken consistent te houden over schalen en voorkomt dat details verloren gaan terwijl informatie door het netwerk stroomt. Samen werken deze twee onderdelen als een hoogopgeleid oog en brein die de visuele informatie voorbereiden en herbouwen.
Ruimte en detail tegelijk mengen
De kerninnovatie ligt in de fusiemodule, die expliciet “waar dingen zijn” scheidt van “hoe gedetailleerd ze zijn”. De ene tak, de zogenaamde spatial attention-module, kijkt rechtstreeks naar de beeldkenmerken en beslist welke regio’s van de infrarood- en zichtbare invoer meer nadruk verdienen. Ze leert heldere thermische doelen te accentueren, zoals mensen of voertuigen, terwijl fijne texturen uit het zichtbare beeld behouden blijven. De tweede tak werkt in het frequentiedomein en splitst beeldkenmerken in een gladde basielaag en meerdere rand- en textuurlagen langs horizontale, verticale en diagonale richtingen. Hier passeert een nieuwe Wavelet-Mamba-mechaniek deze directionele detailbanden door een gestroomlijnd state-space model dat langeafstandspatronen efficiënt kan volgen, belangrijke randen versterkt zonder het beeld te overladen met ruis.
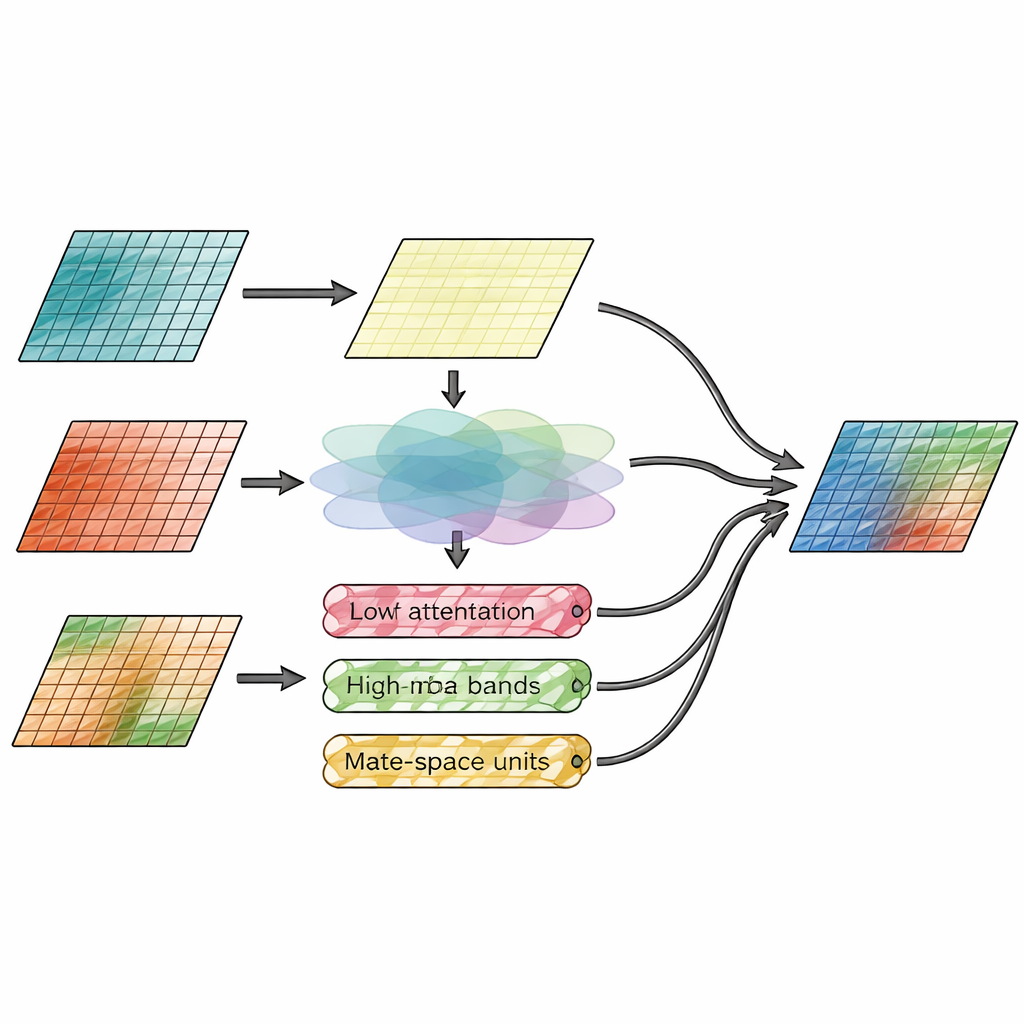
De methode op de proef gesteld
Om te beoordelen of dit ontwerp daadwerkelijk helpt, trainden de auteurs de encoder-decoder op een grote, algemene beeldset en trainden ze vervolgens de fusiemodule op gepaarde infrarood–zichtbare scènes. Ze testten WMambaFuse op drie openbare benchmarks die militaire scènes, wegen en alledaagse omgevingen bestrijken, en vergeleken het met negen toonaangevende fusiemethoden, waaronder methoden gebaseerd op klassieke auto-encoders, convolutionele netwerken, transformers en eerdere Mamba-stijl modellen. Over een breed scala aan maten — totale informatie, contrast, randscherpte en structurele gelijkenis met de bronnen — presteerde de nieuwe methode consequent gelijk aan of beter dan de concurrentie. Visuele voorbeelden tonen duidelijkere contouren, helderdere en vollediger thermische doelen en beter bewaarde achtergrondtexturen, zelfs in uitdagende nacht- en weinig-lichtsituaties.
Duidelijker gefuseerde beelden voor taken in de echte wereld
In eenvoudige bewoordingen leert WMambaFuse wanneer het warmtepatronen moet vertrouwen en wanneer het zichtbare detail moet vertrouwen, en doet dat zowel in het beeldvlak als in de verborgen frequentielagen die randen en texturen coderen. Het resultaat is één gefuseerd beeld dat gemakkelijker voor mensen te interpreteren is en betrouwbaarder voor downstreamtaken zoals detectie of tracking van doelen. Hoewel de auteurs opmerken dat extreme omstandigheden, zoals dichte mist of hevige regen, nog steeds open vragen oproepen, tonen hun experimenten aan dat dit ruimte–frequentieontwerp, aangedreven door moderne state-space modellering, een robuuste stap voorwaarts biedt voor machines die helder moeten zien in het donker.
Bronvermelding: Wang, J., Si, Y., Chen, Y. et al. WMambaFuse: an infrared and visible image fusion network based on wavelet mamba. Sci Rep 16, 14113 (2026). https://doi.org/10.1038/s41598-026-44374-y
Trefwoorden: infrarood zichtbaar fusie, nachtzichtbeeldvorming, wavelet-gebaseerde beeldfusie, state-space visiemodellen, multimodale computervisie