Clear Sky Science · en
WMambaFuse: an infrared and visible image fusion network based on wavelet mamba
Sharper Night Vision for a Noisy World
When cameras look at the same scene in normal light and in infrared, each view reveals different truths: one shows crisp detail and color, the other highlights heat and hidden objects in the dark. This paper introduces WMambaFuse, a new computer-vision method that blends these two perspectives into a single, clearer picture. The goal is simple but powerful: help people and machines see more reliably at night, in bad weather, and in complex environments by combining the best of both kinds of images.
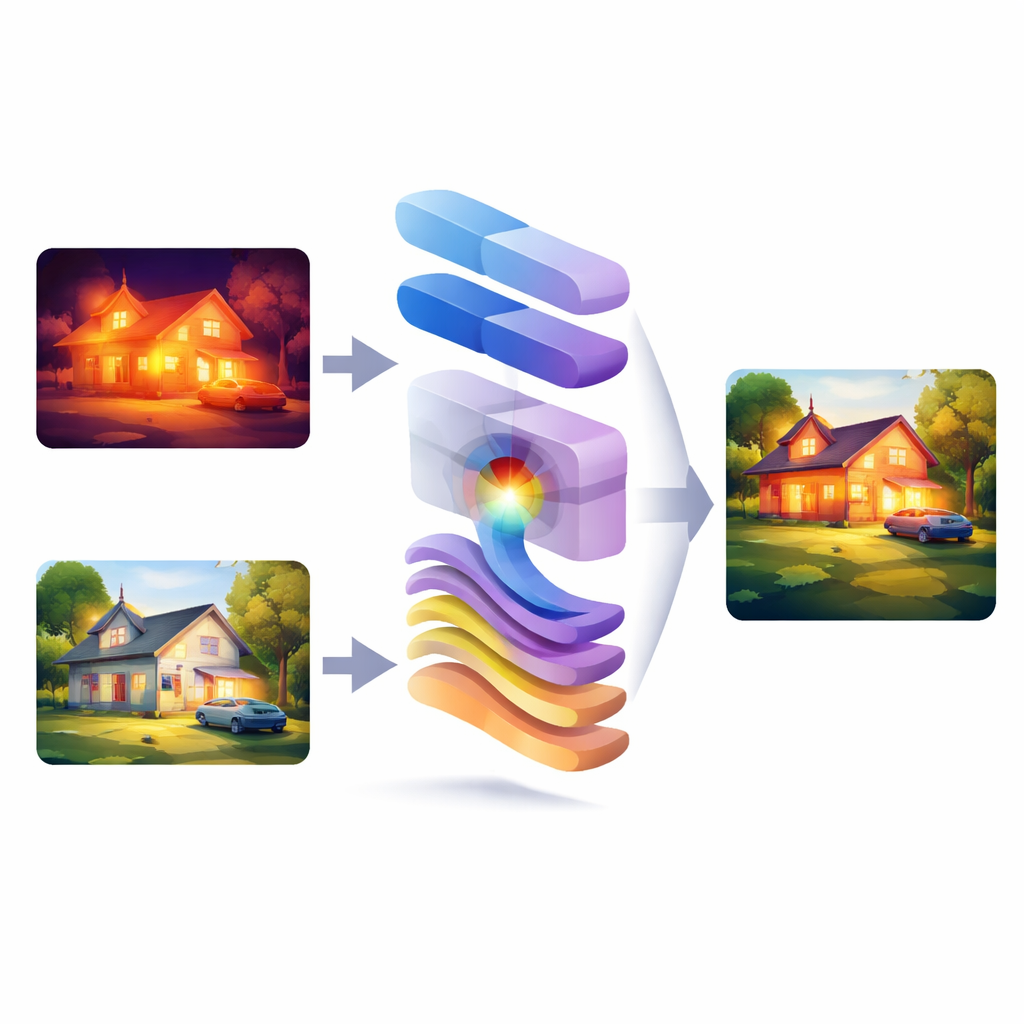
Why Two Eyes Are Better Than One
Visible-light cameras capture fine textures, sharp edges, and natural colors, but they falter in low light, fog, or glare. Infrared cameras do the opposite: they sense heat and can reveal people, vehicles, or equipment in darkness, yet their images often look blurry and lack detail. Fusing these two sources promises the best of both worlds, but it is a tricky balance. Many earlier systems either focus on pixel-level mixing in the image plane or work purely in the frequency domain, where images are broken into coarse shapes and fine patterns. In practice, approaches that stay only in one domain tend to sacrifice either global structure or delicate details, leading to lost edges, washed-out textures, or unstable results in complex scenes.
A Three-Part Engine for Seeing More
WMambaFuse tackles this challenge with a carefully layered design: an encoder, a fusion module, and a decoder. The encoder uses a modern “windowed” transformer to look at the scene at multiple scales, capturing both close-up texture and broader context. Think of it as a smart front end that learns how to represent the important features of each input image without hand-written rules. The decoder then reconstructs the final fused image using a recurrent structure, which helps keep features consistent across scales and avoids losing details as information flows through the network. Together, these two parts act like a highly trained eye and brain that prepare and rebuild the visual information.
Blending Space and Detail at the Same Time
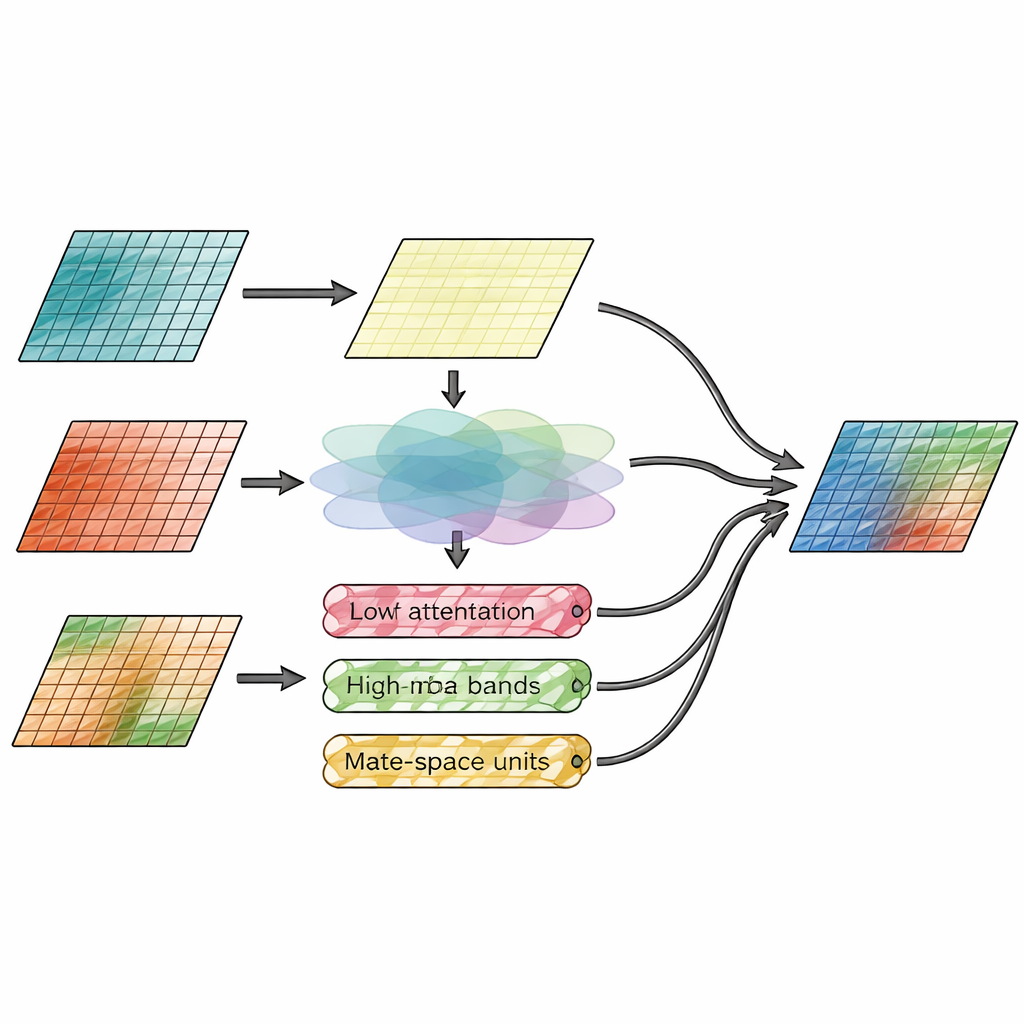
The core innovation lies in the fusion module, which explicitly separates “where things are” from “how detailed they are.” One branch, called the spatial attention module, looks directly at the image features and decides which regions from infrared and visible inputs deserve more emphasis. It learns to highlight bright thermal targets, like people or vehicles, while also preserving fine textures from the visible view. The second branch works in the frequency domain, splitting image features into a smooth base layer and several edge and texture layers along horizontal, vertical, and diagonal directions. Here, a new Wavelet-Mamba mechanism passes these directional detail bands through a streamlined state-space model that can track long-range patterns efficiently, enhancing important edges without overwhelming the image with noise.
Putting the Method to the Test
To judge whether this design truly helps, the authors trained the encoder-decoder on a large, general-purpose image set and then trained the fusion module on paired infrared–visible scenes. They tested WMambaFuse on three public benchmarks covering military scenes, roads, and everyday environments, and compared it with nine leading fusion methods, including those based on classic autoencoders, convolutional networks, transformers, and earlier Mamba-style models. Across a wide range of measures—overall information, contrast, edge sharpness, and structural similarity to the sources—the new method consistently matched or beat competitors. Visual examples show clearer outlines, brighter and more complete thermal targets, and better-preserved background textures, even in challenging night and low-light situations.
Clearer Fused Images for Real-World Tasks
In plain terms, WMambaFuse learns when to trust heat patterns and when to trust visible detail, and it does so both in the image plane and in the hidden frequency layers that encode edges and textures. The result is a single fused image that is easier for humans to interpret and more reliable for downstream tasks like target detection or tracking. While the authors note that extreme conditions, such as heavy fog or intense rain, still pose open questions, their experiments show that this spatial–frequency design, powered by modern state-space modeling, offers a robust step forward for machines that need to see clearly in the dark.
Citation: Wang, J., Si, Y., Chen, Y. et al. WMambaFuse: an infrared and visible image fusion network based on wavelet mamba. Sci Rep 16, 14113 (2026). https://doi.org/10.1038/s41598-026-44374-y
Keywords: infrared visible fusion, night vision imaging, wavelet-based image fusion, state space vision models, multimodal computer vision