Clear Sky Science · fr
WMambaFuse : un réseau de fusion d’images infrarouge et visible basé sur la wavelet mamba
Une vision nocturne plus nette pour un monde bruyant
Lorsque des caméras observent la même scène en lumière visible et en infrarouge, chaque vue révèle des vérités différentes : l’une montre des détails nets et des couleurs, l’autre met en évidence la chaleur et des objets cachés dans l’obscurité. Cet article présente WMambaFuse, une nouvelle méthode de vision par ordinateur qui fusionne ces deux perspectives en une seule image plus claire. L’objectif est simple mais puissant : aider les humains et les machines à mieux voir la nuit, par mauvais temps et dans des environnements complexes en combinant le meilleur des deux types d’images.
Pourquoi deux yeux valent mieux qu’un
Les caméras en lumière visible capturent de fines textures, des contours précis et des couleurs naturelles, mais elles échouent en faible luminosité, dans le brouillard ou face à l’éblouissement. Les caméras infrarouges font l’inverse : elles détectent la chaleur et peuvent révéler des personnes, des véhicules ou du matériel dans l’obscurité, mais leurs images sont souvent floues et manquent de détails. Fusionner ces deux sources promet le meilleur des deux mondes, mais l’équilibre est délicat. Beaucoup de systèmes antérieurs se focalisent soit sur le mélange au niveau des pixels dans le plan image, soit travaillent uniquement dans le domaine fréquentiel, où les images sont décomposées en formes grossières et motifs fins. En pratique, les approches limitées à un seul domaine tendent à sacrifier soit la structure globale soit les détails délicats, entraînant des contours perdus, des textures estompées ou des résultats instables dans des scènes complexes.
Un moteur en trois parties pour mieux voir
WMambaFuse relève ce défi avec une architecture en couches soigneusement pensée : un encodeur, un module de fusion et un décodeur. L’encodeur utilise un transformeur « fenêtré » moderne pour examiner la scène à plusieurs échelles, capturant à la fois la texture de près et le contexte plus large. Considérez-le comme une interface intelligente qui apprend à représenter les caractéristiques importantes de chaque image d’entrée sans règles écrites à la main. Le décodeur reconstruit ensuite l’image fusionnée finale en s’appuyant sur une structure récurrente, ce qui aide à maintenir la cohérence des caractéristiques entre les échelles et évite la perte de détails au fur et à mesure que l’information traverse le réseau. Ensemble, ces deux parties agissent comme un œil et un cerveau hautement entraînés qui préparent et rebâtissent l’information visuelle.
Mêler espace et détail en même temps
L’innovation centrale réside dans le module de fusion, qui sépare explicitement le « où se trouvent les choses » du « niveau de détail ». Une branche, appelée module d’attention spatiale, examine directement les caractéristiques d’image et décide quelles régions des entrées infrarouge et visible méritent davantage d’emphase. Elle apprend à mettre en évidence des cibles thermiques brillantes, comme des personnes ou des véhicules, tout en préservant les textures fines de la vue visible. La deuxième branche opère dans le domaine fréquentiel, en scindant les caractéristiques d’image en une couche de base lisse et plusieurs couches de contours et de textures selon des directions horizontales, verticales et diagonales. Ici, un nouveau mécanisme Wavelet-Mamba fait passer ces bandes de détail directionnel à travers un modèle d’état simplifié capable de suivre efficacement des motifs à longue portée, renforçant les contours importants sans submerger l’image de bruit.
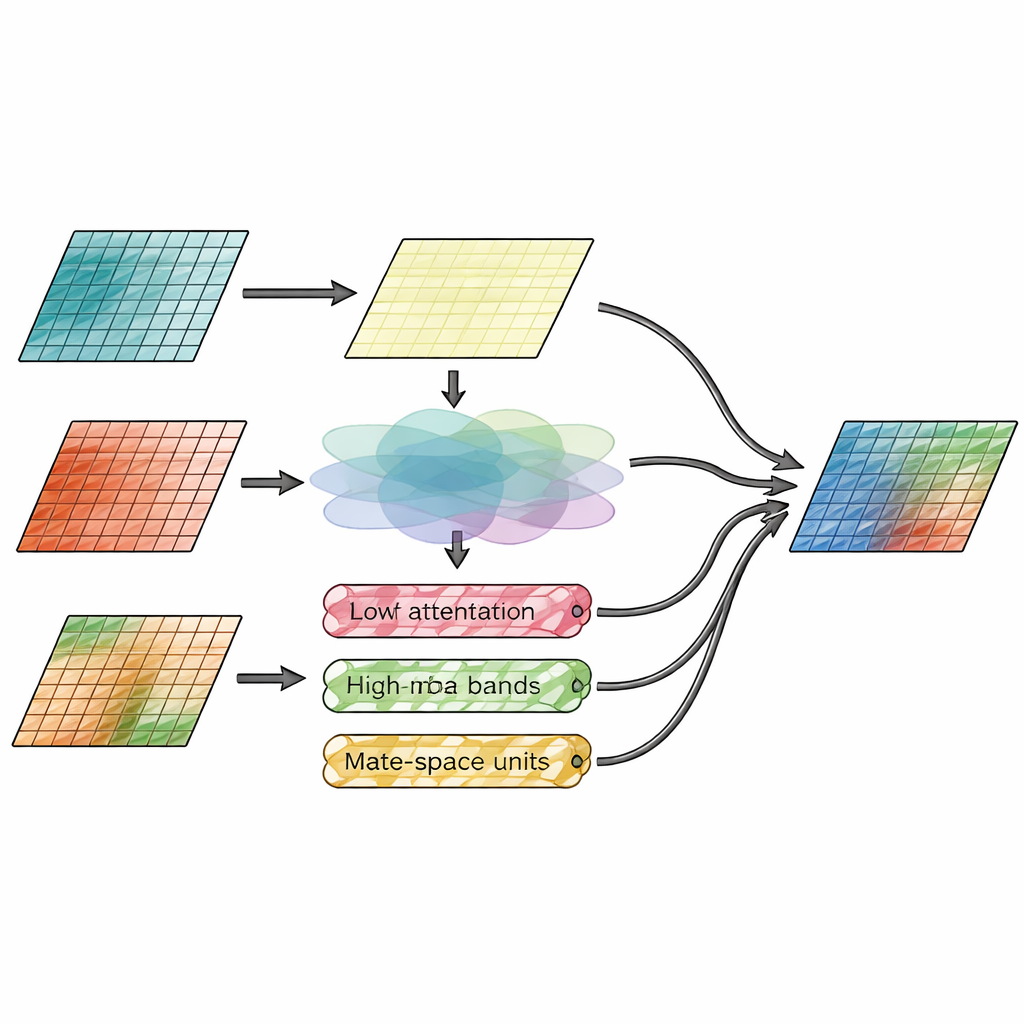
Mettre la méthode à l’épreuve
Pour évaluer l’utilité de ce dispositif, les auteurs ont entraîné l’encodeur-décodeur sur un grand jeu d’images généraliste puis ont entraîné le module de fusion sur des scènes appariées infrarouge–visible. Ils ont testé WMambaFuse sur trois bancs d’essai publics couvrant des scènes militaires, des routes et des environnements du quotidien, et l’ont comparé à neuf méthodes de fusion de premier plan, y compris des auto-encodeurs classiques, des réseaux convolutifs, des transformeurs et des modèles antérieurs de type Mamba. Sur un large éventail de mesures — information globale, contraste, netteté des contours et similarité structurelle par rapport aux sources — la nouvelle méthode a systématiquement égalé ou surpassé ses concurrentes. Les exemples visuels montrent des contours plus nets, des cibles thermiques plus lumineuses et plus complètes, et de meilleures textures d’arrière-plan préservées, même dans des situations nocturnes et de faible luminosité difficiles.
Des images fusionnées plus claires pour des tâches réelles
Concrètement, WMambaFuse apprend quand faire confiance aux motifs thermiques et quand privilégier le détail visible, et le fait à la fois dans le plan image et dans les couches fréquentielles cachées qui encodent contours et textures. Le résultat est une image fusionnée unique plus facile à interpréter pour un humain et plus fiable pour des tâches en aval comme la détection ou le suivi de cibles. Bien que les auteurs notent que des conditions extrêmes, comme un brouillard dense ou une pluie intense, posent encore des questions ouvertes, leurs expériences montrent que ce design spatial–fréquentiel, soutenu par la modélisation d’état moderne, constitue une avancée robuste pour des machines qui doivent voir clairement dans l’obscurité.
Citation: Wang, J., Si, Y., Chen, Y. et al. WMambaFuse: an infrared and visible image fusion network based on wavelet mamba. Sci Rep 16, 14113 (2026). https://doi.org/10.1038/s41598-026-44374-y
Mots-clés: fusion infrarouge visible, imagerie vision nocturne, fusion d’images basée sur les ondelettes, modèles d’état pour la vision, vision par ordinateur multimodale