Clear Sky Science · pl
WMambaFuse: sieć do fuzji obrazów w podczerwieni i widzialnych oparta na fali Mamba
Wyraźniejsza widoczność nocna dla hałaśliwego świata
Kiedy kamery rejestrują tę samą scenę w świetle widzialnym i w podczerwieni, każda perspektywa odsłania inne prawdy: jedna ukazuje drobne detale i kolory, druga uwydatnia ciepło i ukryte obiekty w ciemności. W artykule wprowadzono WMambaFuse — nową metodę wizji komputerowej, która łączy te dwie perspektywy w jeden, jaśniejszy obraz. Cel jest prosty, lecz istotny: pomóc ludziom i maszynom widzieć bardziej niezawodnie w nocy, przy złej pogodzie i w złożonych środowiskach, łącząc to, co najlepsze w obu typach obrazów.
Dlaczego dwoje oczu jest lepsze niż jedno
Kamera w świetle widzialnym rejestruje drobne tekstury, ostre krawędzie i naturalne barwy, ale słabnie przy słabym oświetleniu, we mgle czy przy olśnieniu. Kamery w podczerwieni robią odwrotnie: wykrywają ciepło i potrafią ujawnić ludzi, pojazdy czy urządzenia w ciemności, lecz ich obrazy często są rozmyte i pozbawione detali. Fuzja tych dwóch źródeł obiecuje najlepsze z obu światów, ale to delikatna równowaga. Wiele wcześniejszych systemów skupiało się albo na mieszaniu na poziomie pikseli w płaszczyźnie obrazu, albo pracowało wyłącznie w domenie częstotliwości, gdzie obrazy rozkłada się na grube kształty i drobne wzory. W praktyce podejścia ograniczone do jednej domeny mają tendencję do poświęcania albo globalnej struktury, albo subtelnych detali, prowadząc do utraty krawędzi, wypłowiałych tekstur lub niestabilnych wyników w złożonych scenach.
Trójstopniowy silnik do widzenia więcej
WMambaFuse stawia czoła temu wyzwaniu za pomocą przemyślanej, warstwowej konstrukcji: enkodera, modułu fuzji i dekodera. Enkoder wykorzystuje nowoczesny „okienkowy” transformer, aby analizować scenę na wielu skalach, wychwytując zarówno detale z bliska, jak i szerszy kontekst. Można to traktować jak inteligentny front-end, który uczy się reprezentować istotne cechy każdego obrazu wejściowego bez ręcznie pisanych reguł. Dekoder następnie rekonstruuje ostateczny obraz z fuzji, używając struktury rekurencyjnej, co pomaga zachować spójność cech pomiędzy skalami i unikać utraty detali podczas przepływu informacji przez sieć. Razem te dwie części działają jak wytrenowane oko i mózg, które przygotowują i odbudowują informacje wizualne.
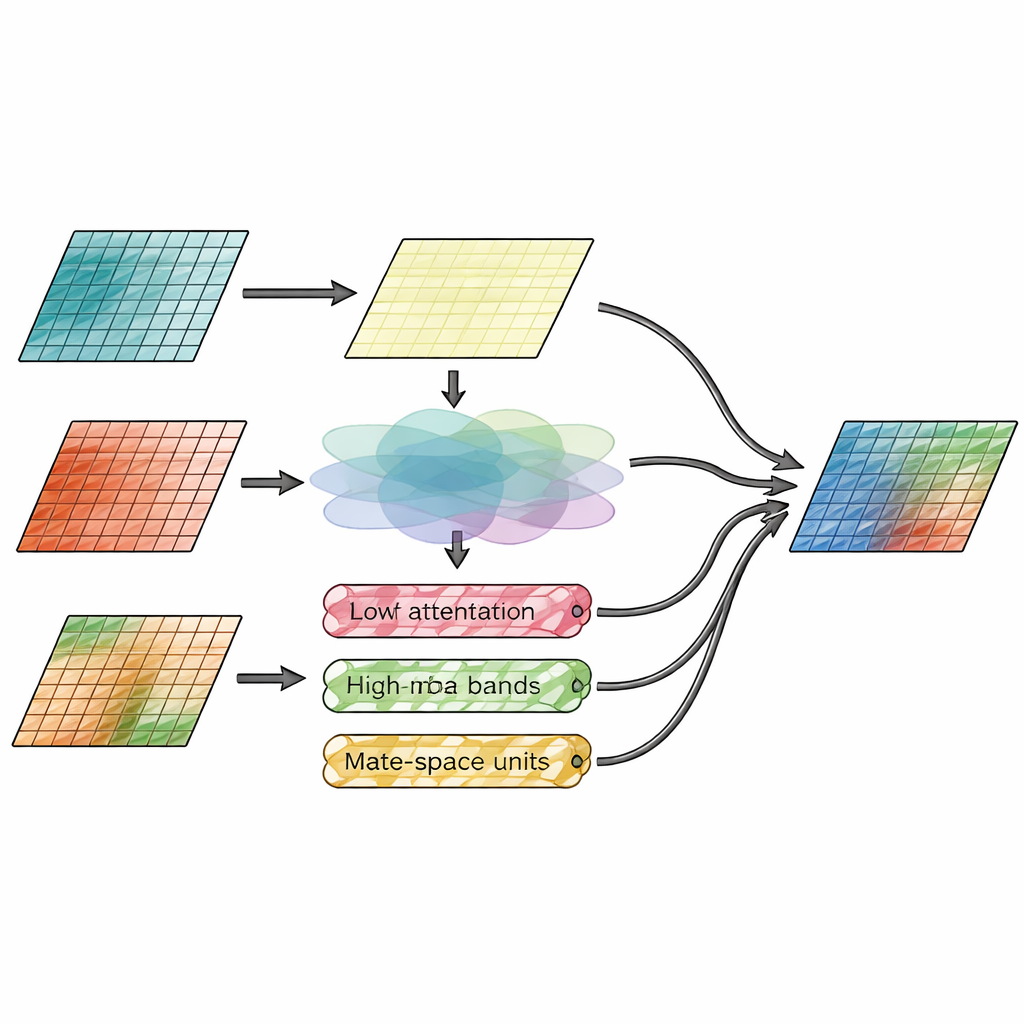
Łączenie przestrzeni i detalu jednocześnie
Kluczowa innowacja leży w module fuzji, który wyraźnie rozdziela „gdzie coś się znajduje” od „jak szczegółowe to jest”. Jeden filar, zwany modułem uwagi przestrzennej, patrzy bezpośrednio na cechy obrazu i decyduje, które regiony z wejść podczerwonych i widzialnych zasługują na większe wyróżnienie. Uczy się podkreślać jasne cele termalne, takie jak ludzie czy pojazdy, a jednocześnie zachowywać drobne tekstury z obrazu widzialnego. Drugi filar działa w domenie częstotliwości, rozdzielając cechy obrazu na gładką warstwę bazową oraz kilka warstw krawędzi i tekstur w kierunkach poziomych, pionowych i diagonalnych. Tam nowy mechanizm Wavelet‑Mamba przekazuje te kierunkowe pasma detali przez uproszczony model przestrzeni stanu, który potrafi efektywnie śledzić długozasięgowe wzory, wzmacniając ważne krawędzie bez zalewania obrazu szumem.
Próba w terenie
Aby ocenić, czy ta konstrukcja rzeczywiście pomaga, autorzy wytrenowali enkoder‑dekoder na dużym, uniwersalnym zbiorze obrazów, a następnie wytrenowali moduł fuzji na sparowanych scenach podczerwień–widzialne. Przetestowali WMambaFuse na trzech publicznych benchmarkach obejmujących sceny militarne, drogi i środowiska codzienne, i porównali go z dziewięcioma wiodącymi metodami fuzji, w tym opartymi na klasycznych autoenkoderach, sieciach konwolucyjnych, transformerach oraz wcześniejszych modelach w stylu Mamba. W szerokim zakresie miar — ogólnej informacji, kontrastu, ostrości krawędzi i podobieństwa strukturalnego do źródeł — nowa metoda konsekwentnie dorównywała lub przewyższała konkurencję. Przykłady wizualne pokazują wyraźniejsze kontury, jaśniejsze i bardziej kompletne cele termalne oraz lepiej zachowane tekstury tła, nawet w trudnych warunkach nocnych i przy słabym oświetleniu.
Czystsze obrazy z fuzji do zadań w świecie realnym
Mówiąc prościej, WMambaFuse uczy się, kiedy ufać wzorcom cieplnym, a kiedy zaufać detalom widzialnym, i robi to zarówno w płaszczyźnie obrazu, jak i w ukrytych warstwach częstotliwości kodujących krawędzie i tekstury. Wynikiem jest pojedynczy obraz z fuzji, który jest łatwiejszy do interpretacji dla ludzi i bardziej niezawodny dla zadań dalszego przetwarzania, takich jak wykrywanie lub śledzenie celów. Choć autorzy zauważają, że ekstremalne warunki, takie jak gęsta mgła czy intensywny deszcz, wciąż pozostawiają pytania otwarte, ich eksperymenty pokazują, że to przestrzenno‑częstotliwościowe podejście, wsparte nowoczesnym modelowaniem przestrzeni stanu, stanowi solidny krok naprzód dla maszyn, które muszą widzieć wyraźnie w ciemności.
Cytowanie: Wang, J., Si, Y., Chen, Y. et al. WMambaFuse: an infrared and visible image fusion network based on wavelet mamba. Sci Rep 16, 14113 (2026). https://doi.org/10.1038/s41598-026-44374-y
Słowa kluczowe: fuzja podczerwień‑widzialne, obrazowanie noktowizyjne, fuzja obrazów oparta na falkach, modele widzenia w przestrzeni stanu, multimodalna wizja komputerowa