Clear Sky Science · zh
通过可解释的数据驱动药物溶解度预测加速超临界药物制剂开发
这对未来药物意味着什么
许多有前景的药物最终无法进入临床应用,因为它们在体内的溶解度不足以被吸收。本文所述研究探讨了如何在计算机上预测不同药物在一种被称为超临界流体的特殊二氧化碳中溶解的难易程度。通过使用现代的数据驱动工具,作者旨在减少代价高昂的实验室反复试验,加快从分子到药物的转化过程。
一种更洁净的难溶药物制备方法
超临界二氧化碳同时表现出液体和气体的特性,使其在携带和构型调整药物分子方面具有独特能力。它可以帮助制备微小颗粒、将药物装载到给药系统中,并且不会留下有毒溶剂。然而,不同药物的反应各不相同:压力、温度以及药物本身的结构变化都会显著影响其溶解度。对每一种新化合物在高压设备中测量这些效应既缓慢又昂贵,因此能够从数据中预测溶解度对制剂科学家和制药商极具吸引力。
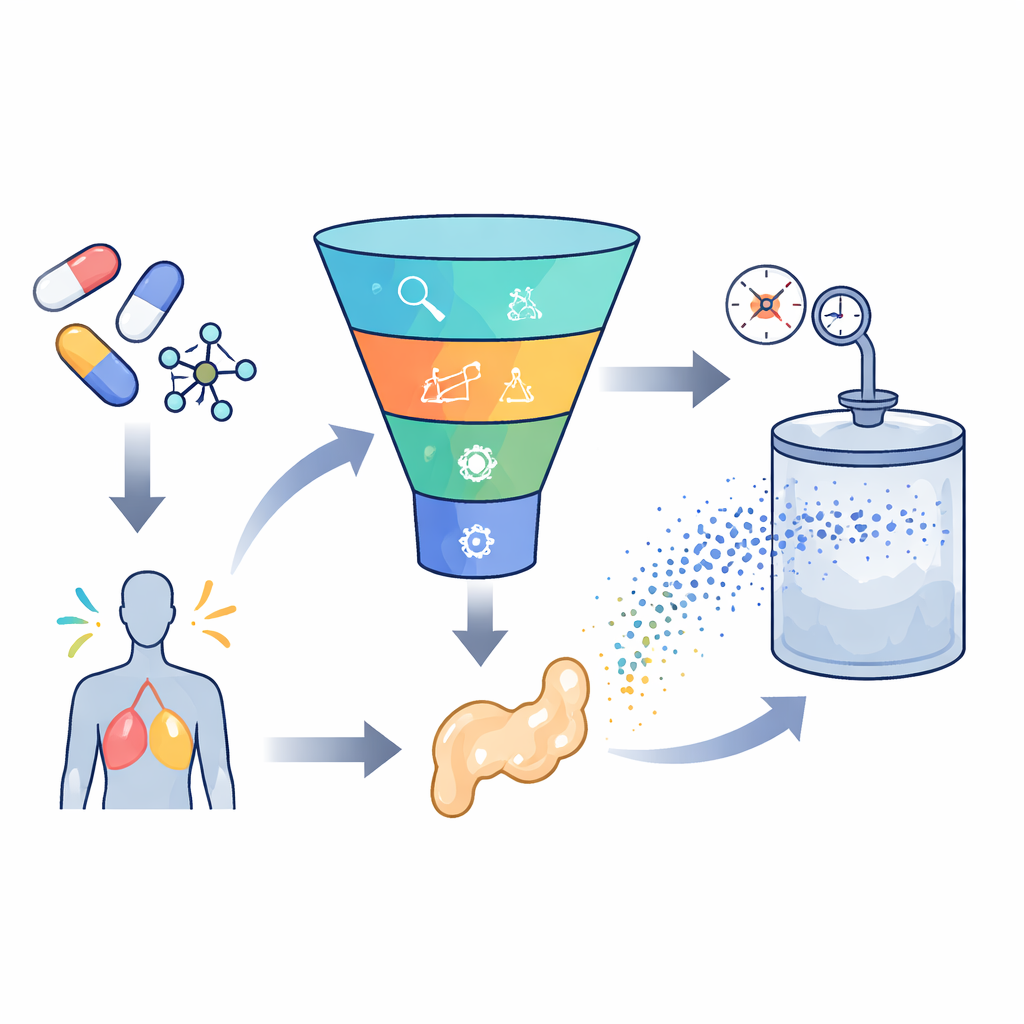
构建智能预测引擎
为了解决这一挑战,研究人员收集了来自先前实验的252条高质量测量数据,涉及七种非常不同的药物,涵盖胃溃疡和癫痫药物以及抗真菌和抗病毒药物等。对于每个数据点,他们记录了诸如温度和压力等基本条件,以及分子量、熔点等简单的药物属性。随后他们训练了几种机器学习模型,以学习这些输入与药物在超临界二氧化碳中溶解量之间的关系。使用的两类主要模型为:支持向量回归,它试图在数据间拟合一条平滑曲线;以及极端梯度提升(XGBoost),这是一种基于树的高级方法,将许多小决策树组合成一个强预测器。
让仿生搜索算法调优模型
选择这些模型的内部设置(称为超参数)会显著影响模型的性能。研究团队没有采用盲猜或简单的网格搜索,而是借鉴了动物行为学的思想。他们应用了两种“仿生”优化方法,一种基于灰雁的觅食和迁徙行为,另一种受角蜥等生存策略启发。这些算法探索大量模型设置组合,并逐步朝向那些能以最小误差给出最准确预测的组合移动。通过将问题表述为多目标优化,作者在最小化预测误差和最大化模型对数据变异解释能力这两个目标之间取得平衡,同时兼顾计算时间。
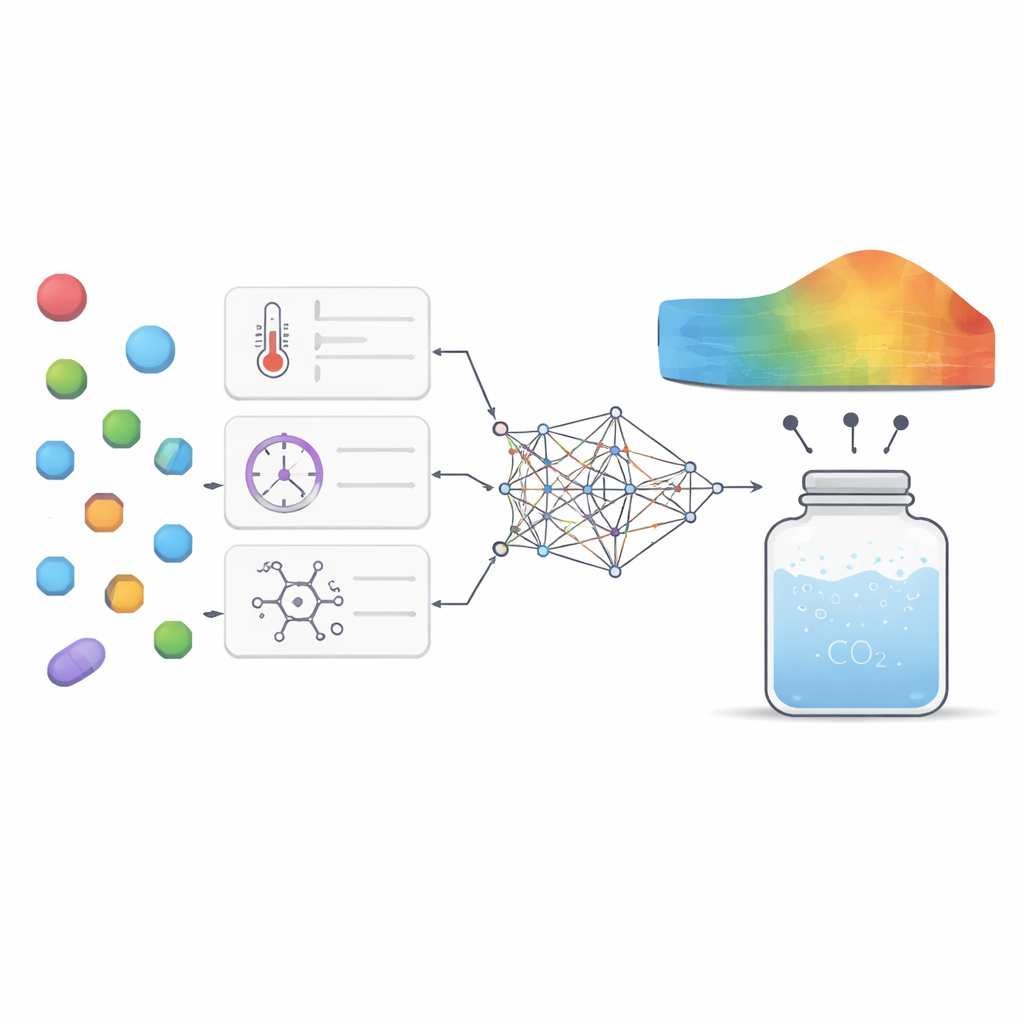
看清哪些因素最关键
除了原始精度之外,作者希望模型能提供科学见解,而不是成为一个神秘的“黑箱”。他们使用了两种互补的分析工具来评估每个输入因素对模型输出来说的重要程度以及这些因素之间的相互作用。两种技术都突出了压力和分子量是最重要的杠杆:较高的压力通常通过更紧密地压缩二氧化碳来提高溶解度,而分子量较大的分子倾向于较难溶解。温度和熔点的影响更为微妙但仍有意义,主要通过与压力的相互作用以及反映药物晶体结构结合紧密程度来体现。模型还再现了已知的热力学模式,例如温度变化在不同范围内会增强或削弱压力效应,这增加了对模型捕捉真实物理行为而非仅仅记忆数值的信心。
这些结果对药物开发意味着什么
表现最好的混合模型将梯度提升方法与角蜥优化器相结合,与未经调优的基线模型相比将预测误差大约降低了40%。它不仅接近实验观测到的平均溶解度值,还能匹配其分布和少见的高溶解度情况。这一精度水平意味着该模型可以作为强大的预筛选工具:研究人员可以在笔记本电脑上先探索压力和温度范围,随后再决定是否进行高压实验,从而减少在不合适候选上浪费的精力。尽管该方法仍依赖于有限的数据集和有限的药物属性集合,且最精确的版本计算量较大,但这一框架展示了可解释的机器学习如何既加速无溶剂制剂流程,又加深我们对为何某些药物在超临界二氧化碳中更易溶解的理解。
引用: Khafagy, ES., Lila, A.S.A. & Pishnamazi, M. Accelerating supercritical pharmaceutical formulation via interpretable data-driven prediction of drug solubility. Sci Rep 16, 11006 (2026). https://doi.org/10.1038/s41598-026-44161-9
关键词: 药物溶解度, 超临界二氧化碳, 机器学习, 药物制剂, 数据驱动建模