Clear Sky Science · nl
Het versnellen van superkritische farmaceutische formulering via interpreteerbare data-gedreven voorspelling van medicijnoplosbaarheid
Waarom dit ertoe doet voor toekomstige medicijnen
Veel veelbelovende medicijnen bereiken patiënten niet omdat ze simpelweg niet goed genoeg oplossen om door het lichaam te worden opgenomen. De studie achter dit artikel onderzoekt hoe je op een computer kunt voorspellen hoe gemakkelijk verschillende geneesmiddelen oplossen in een speciale vorm van kooldioxide, bekend als een superkritisch fluïdum. Door moderne data-gedreven hulpmiddelen te gebruiken, proberen de auteurs dure laboratoriumproeven met proberen-en-fouten te verminderen en de weg van molecuul naar medicijn te versnellen.
Een schonere manier om moeilijk oplosbare geneesmiddelen te maken
Superkritisch kooldioxide gedraagt zich zowel als een vloeistof als een gas, wat het een ongebruikelijke capaciteit geeft om geneesmiddelmoleculen te vervoeren en te vormen. Het kan helpen bij het creëren van zeer kleine deeltjes, het laden van geneesmiddelen in afgiftesystemen, en dat alles zonder residuen van toxische oplosmiddelen achter te laten. Elk geneesmiddel reageert echter anders: veranderingen in druk, temperatuur en de structuur van het geneesmiddel zelf kunnen dramatisch beïnvloeden hoeveel ervan oplost. Het meten van deze effecten voor elk nieuw bestanddeel in hogedrukapparatuur is traag en kostbaar, dus het kunnen voorspellen van oplosbaarheid op basis van data is erg aantrekkelijk voor formulatiewetenschappers en geneesmiddelenfabrikanten.
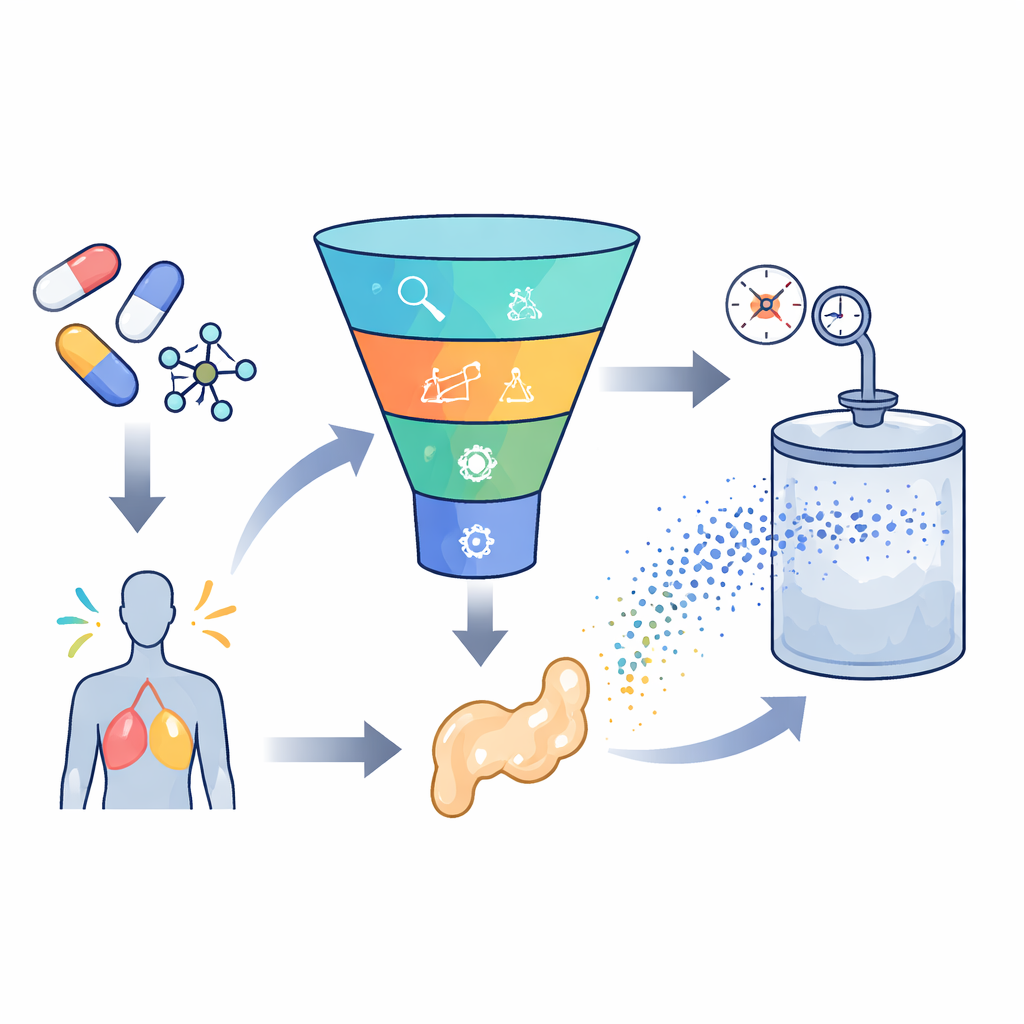
Het bouwen van een slim voorspellingsmechanisme
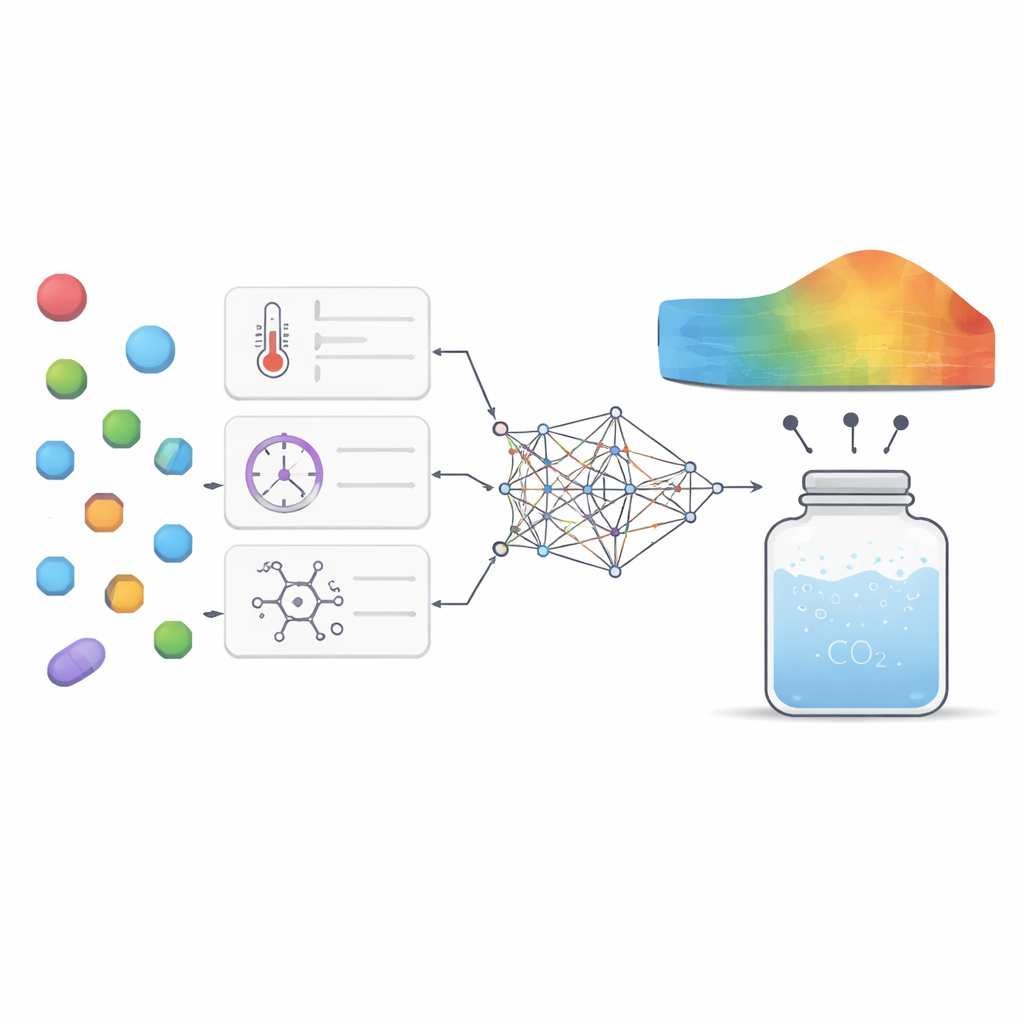
Om deze uitdaging aan te pakken verzamelden de onderzoekers 252 hoogwaardige metingen uit eerdere experimenten met zeven zeer verschillende geneesmiddelen, variërend van middelen tegen zweren en epilepsie tot antischimmelmiddelen en antivirale middelen. Voor elk datapunt noteerden ze basiscondities zoals temperatuur en druk, samen met eenvoudige geneesmiddeleigenschappen zoals molaire massa en smeltpunt. Vervolgens trainden ze meerdere machine-learningmodellen om het verband te leren tussen deze invoerwaarden en hoeveel van elk geneesmiddel oploste in superkritisch kooldioxide. Er werden twee hoofdtypen modellen gebruikt: support vector regression, dat probeert een vloeiende kromme door de data te trekken, en extreme gradient boosting, een geavanceerde boomgebaseerde methode die veel kleine beslissingsbomen combineert tot één sterke voorspeller.
Natuurlijke zoekalgoritmen laten de modellen afstemmen
Het kiezen van de interne instellingen van deze modellen, bekend als hyperparameters, kan sterk beïnvloeden hoe goed ze presteren. In plaats van te gissen of eenvoudige rasterzoektochten te gebruiken, leende het team ideeën uit gedrag van dieren. Ze pasten twee "bio-geïnspireerde" optimalisatiemethoden toe: één gebaseerd op hoe grauwe ganzen foerageren en migreren, en een andere geïnspireerd door overlevingstactieken van hoorndraken. Deze algoritmen verkennen vele combinaties van modelinstellingen en bewegen geleidelijk naar diegene die de nauwkeurigste voorspellingen met de minste fout opleveren. Door dit als een multi-objectief probleem te formuleren, wogen de auteurs twee doelen tegelijk af: het minimaliseren van voorspelfout en het maximaliseren van het verklaarde deel van de variatie in de data, terwijl ze ook rekening hielden met rekentijd.
Zien welke knoppen het meest van belang zijn
Naast ruwe nauwkeurigheid wilden de auteurs dat het model wetenschappelijke inzichten biedt in plaats van een mysterieuze "black box" te zijn. Ze gebruikten twee complementaire analysetools om te onderzoeken hoe sterk elke invoervariabele het modeluitvoer beïnvloedde en hoe die factoren met elkaar interageren. Beide technieken benadrukten druk en molaire massa als de belangrijkste knoppen: hogere druk vergrootte over het algemeen de oplosbaarheid door kooldioxide dichter te pakken, terwijl zwaardere moleculen meestal minder gemakkelijk oplossen. Temperatuur en smeltpunt speelden subtielere maar nog steeds betekenisvolle rollen, voornamelijk door interacties met druk en door te reflecteren hoe stevig de kristalstructuur van het geneesmiddel bij elkaar gehouden wordt. Het model reproduceerde ook bekende thermodynamische patronen, zoals hoe temperatuurveranderingen het effect van druk kunnen versterken of verzwakken afhankelijk van het bereik, wat vertrouwen geeft dat het echte fysische gedragingen vastlegt in plaats van alleen maar cijfers te memoriseren.
Wat de resultaten betekenen voor geneesmiddelenontwikkeling
Het best presterende hybride model, dat de gradient-boostingbenadering combineerde met de hoorndraakoptimalisator, verlaagde de voorspelfout met ongeveer 40 procent vergeleken met een niet-getunede basislijn. Het kwam niet alleen goed overeen met de gemiddelde oplosbaarheidswaarden die in experimenten werden waargenomen, maar ook met hun spreiding en zeldzame gevallen van hoge oplosbaarheid. Dit niveau van nauwkeurigheid betekent dat het model kan dienen als een krachtig pre-screening-instrument: onderzoekers kunnen druk- en temperatuurbereiken op een laptop verkennen voordat ze zich committeren aan hogedrukexperimenten, waardoor verspilde inspanning op slechte kandidaten wordt verminderd. Hoewel de aanpak nog steeds afhangt van een bescheiden dataset en een beperkte set geneesmiddeleigenschappen, en de meest nauwkeurige versie veel rekenkracht vraagt, toont het kader aan hoe interpreteerbare machine learning zowel formuleringen zonder oplosmiddelen kan versnellen als ons begrip kan verdiepen waarom sommige geneesmiddelen beter oplossen dan andere in superkritisch kooldioxide.
Bronvermelding: Khafagy, ES., Lila, A.S.A. & Pishnamazi, M. Accelerating supercritical pharmaceutical formulation via interpretable data-driven prediction of drug solubility. Sci Rep 16, 11006 (2026). https://doi.org/10.1038/s41598-026-44161-9
Trefwoorden: oplosbaarheid van geneesmiddelen, superkritisch kooldioxide, machine learning, farmaceutische formulering, data-gedreven modellering