Clear Sky Science · pl
Przyspieszanie formułowania farmaceutycznego w warunkach nadkrytycznych dzięki interpretowalnej, opartej na danych prognozie rozpuszczalności leków
Dlaczego to ma znaczenie dla przyszłych leków
Wiele obiecujących leków nigdy nie trafia do pacjentów, ponieważ po prostu nie rozpuszczają się wystarczająco dobrze, by organizm mógł je przyswoić. Badanie opisane w tym artykule analizuje, jak prognozować komputerowo, jak łatwo różne leki rozpuszczają się w specjalnej postaci dwutlenku węgla znanej jako płyn nadkrytyczny. Wykorzystując nowoczesne narzędzia oparte na danych, autorzy dążą do ograniczenia kosztownych eksperymentów metodą prób i błędów w laboratorium oraz przyspieszenia drogi od cząsteczki do leku.
Czystszy sposób wytwarzania leków trudno rozpuszczalnych
Nadkrytyczny dwutlenek węgla zachowuje się jak ciecz i gaz jednocześnie, co daje mu nietypową zdolność do przenoszenia i modelowania cząsteczek leków. Może pomóc w tworzeniu mikropartikel, załadowaniu leków do nośników i robić to bez pozostawiania toksycznych rozpuszczalników. Jednak każdy lek reaguje inaczej: zmiany ciśnienia, temperatury i struktury samej cząsteczki mogą znacząco zmieniać jego rozpuszczalność. Mierzenie tych efektów dla każdego nowego związku w urządzeniach wysokociśnieniowych jest powolne i drogie, dlatego możliwość przewidywania rozpuszczalności na podstawie danych jest bardzo atrakcyjna dla naukowców zajmujących się formulacją i producentów leków.
Budowanie inteligentnego silnika predykcyjnego
Aby sprostać temu wyzwaniu, badacze zgromadzili 252 wysokiej jakości pomiary z wcześniejszych eksperymentów dotyczących siedmiu bardzo różnych leków, od środków na wrzody i leki przeciwpadaczkowe po leki przeciwgrzybicze i przeciwwirusowe. Dla każdego punktu danych zebrali podstawowe warunki, takie jak temperatura i ciśnienie, wraz z prostymi właściwościami leku, jak masa molowa i temperatura topnienia. Następnie wyszkolili kilka modeli uczenia maszynowego, aby nauczyć je związku między tymi wejściami a tym, ile danego leku rozpuszcza się w nadkrytycznym dwutlenku węgla. Użyto dwóch głównych typów modeli: regresji wektorów wspierających, która próbuje dopasować gładką krzywą do danych, oraz ekstremalnego wzmacniania gradientowego (XGBoost), zaawansowanej metody opartej na drzewach, która łączy wiele małych drzew decyzyjnych w jeden silny predyktor.
Pozwalając przyrodzie stroić modele za pomocą algorytmów wyszukiwania
Wybór wewnętrznych ustawień tych modeli, zwanych hiperparametrami, może w dużym stopniu wpłynąć na ich wydajność. Zamiast zgadywać lub stosować proste przeszukiwanie siatkowe, zespół zapożyczył pomysły z zachowań zwierząt. Zastosowali dwie „bioinspirowane” metody optymalizacji: jedną opartą na sposobie, w jaki gęgawy przeszukują pokarm i migrują, a drugą inspirowaną taktykami przetrwania jaszczurek z rogatką. Algorytmy te eksplorują wiele kombinacji ustawień modeli i stopniowo przesuwają się w kierunku tych, które dają najbardziej trafne prognozy przy najmniejszym błędzie. Ramy problemu potraktowano jako wielocele, dzięki czemu autorzy zbalansowali dwa cele jednocześnie: minimalizację błędu predykcji i maksymalizację wyjaśnionej zmienności danych, przy jednoczesnym uwzględnieniu czasu obliczeń.
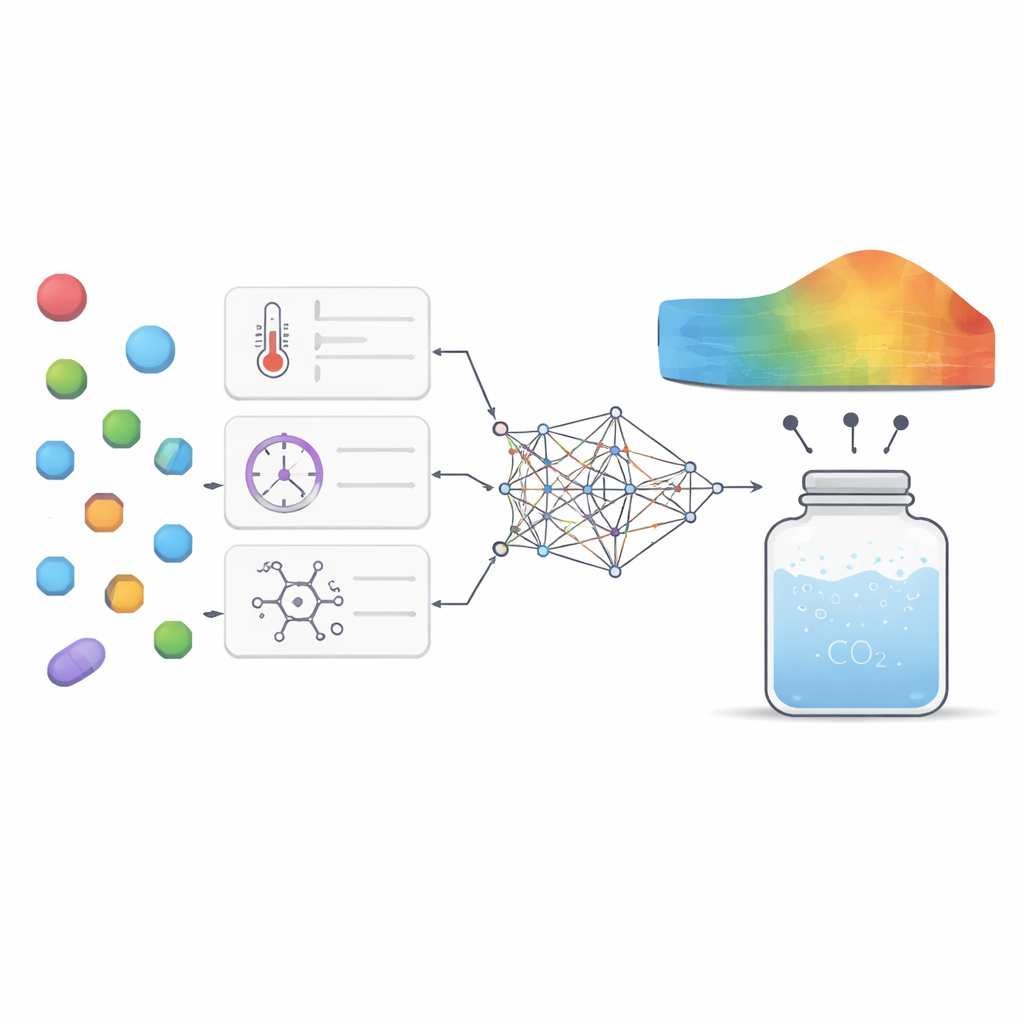
Widząc, które dźwignie mają największe znaczenie
Ponad samą dokładność autorzy chcieli, by model dostarczał wglądu naukowego, a nie był tajemniczą „czarną skrzynką”. Użyli dwóch komplementarnych narzędzi analitycznych, aby sprawdzić, jak mocno każdy czynnik wejściowy kształtuje wyjście modelu i jak te czynniki ze sobą oddziałują. Obie techniki wyróżniły ciśnienie i masę molową jako najważniejsze dźwignie: wyższe ciśnienie zwykle zwiększało rozpuszczalność przez bardziej zwarte upakowanie dwutlenku węgla, podczas gdy cięższe cząsteczki miały tendencję do gorszego rozpuszczania się. Temperatura i temperatura topnienia odgrywały subtelniejsze, lecz istotne role, głównie przez interakcje z ciśnieniem i odzwierciedlanie tego, jak mocno struktura krystaliczna leku trzyma razem cząsteczki. Model odtworzył również znane wzorce termodynamiczne, na przykład to, że zmiana temperatury może albo wzmacniać, albo osłabiać wpływ ciśnienia zależnie od zakresu, co daje pewność, że uchwycono rzeczywiste zachowanie fizyczne, a nie tylko zapamiętano liczby.
Co wyniki oznaczają dla rozwoju leków
Najlepiej działający model hybrydowy, łączący podejście wzmacniania gradientowego z optymalizatorem inspirowanym jaszczurką z rogatką, zmniejszył błąd predykcji o około 40 procent w porównaniu z nieostro dostrojoną bazą. Dopasowywał nie tylko średnie wartości rozpuszczalności obserwowane w eksperymentach, ale też ich rozrzut i rzadkie przypadki wysokiej rozpuszczalności. Taki poziom dokładności oznacza, że model może służyć jako potężne narzędzie preselekcyjne: badacze mogą badać zakresy ciśnienia i temperatury na laptopie, zanim zdecydują się na eksperymenty wysokociśnieniowe, zmniejszając stratę czasu na słabe kandydatury. Chociaż podejście nadal opiera się na umiarkowanym zbiorze danych i ograniczonym zestawie właściwości leków, a najdokładniejsza wersja jest wymagająca obliczeniowo, ramy te pokazują, jak interpretowalne uczenie maszynowe może zarówno przyspieszyć formułowanie bez użycia rozpuszczalników, jak i pogłębić nasze zrozumienie, dlaczego niektóre leki rozpuszczają się lepiej niż inne w nadkrytycznym dwutlenku węgla.
Cytowanie: Khafagy, ES., Lila, A.S.A. & Pishnamazi, M. Accelerating supercritical pharmaceutical formulation via interpretable data-driven prediction of drug solubility. Sci Rep 16, 11006 (2026). https://doi.org/10.1038/s41598-026-44161-9
Słowa kluczowe: rozpuszczalność leków, nadkrytyczny dwutlenek węgla, uczenie maszynowe, formulacja farmaceutyczna, modelowanie oparte na danych