Clear Sky Science · fr
Accélérer la formulation pharmaceutique supercritique via une prédiction interprétable et basée sur les données de la solubilité des médicaments
Pourquoi cela compte pour les médicaments de demain
Beaucoup de médicaments prometteurs n’atteignent jamais les patients parce qu’ils ne se dissolvent tout simplement pas assez pour être absorbés par l’organisme. L’étude à l’origine de cet article explore comment prédire, par ordinateur, la facilité avec laquelle différents médicaments se dissolvent dans une forme particulière de dioxyde de carbone connue sous le nom de fluide supercritique. En utilisant des outils modernes pilotés par les données, les auteurs cherchent à réduire les essais‑erreurs coûteux en laboratoire et à accélérer le parcours de la molécule au médicament.
Une méthode plus propre pour fabriquer des médicaments difficiles à dissoudre
Le dioxyde de carbone supercritique se comporte à la fois comme un liquide et comme un gaz, lui conférant une capacité inhabituelle à transporter et à modeler les molécules pharmaceutiques. Il peut aider à créer de minuscules particules, à charger des médicaments dans des systèmes d’administration, et ce, sans laisser de solvants toxiques. Cependant, chaque médicament réagit différemment : des variations de pression, de température et la structure même de la molécule peuvent modifier de façon spectaculaire la quantité qui se dissout. Mesurer ces effets pour chaque nouveau composé dans des appareils haute‑pression est lent et coûteux ; pouvoir prédire la solubilité à partir de données est donc très attractif pour les scientifiques de formulation et les industriels pharmaceutiques.
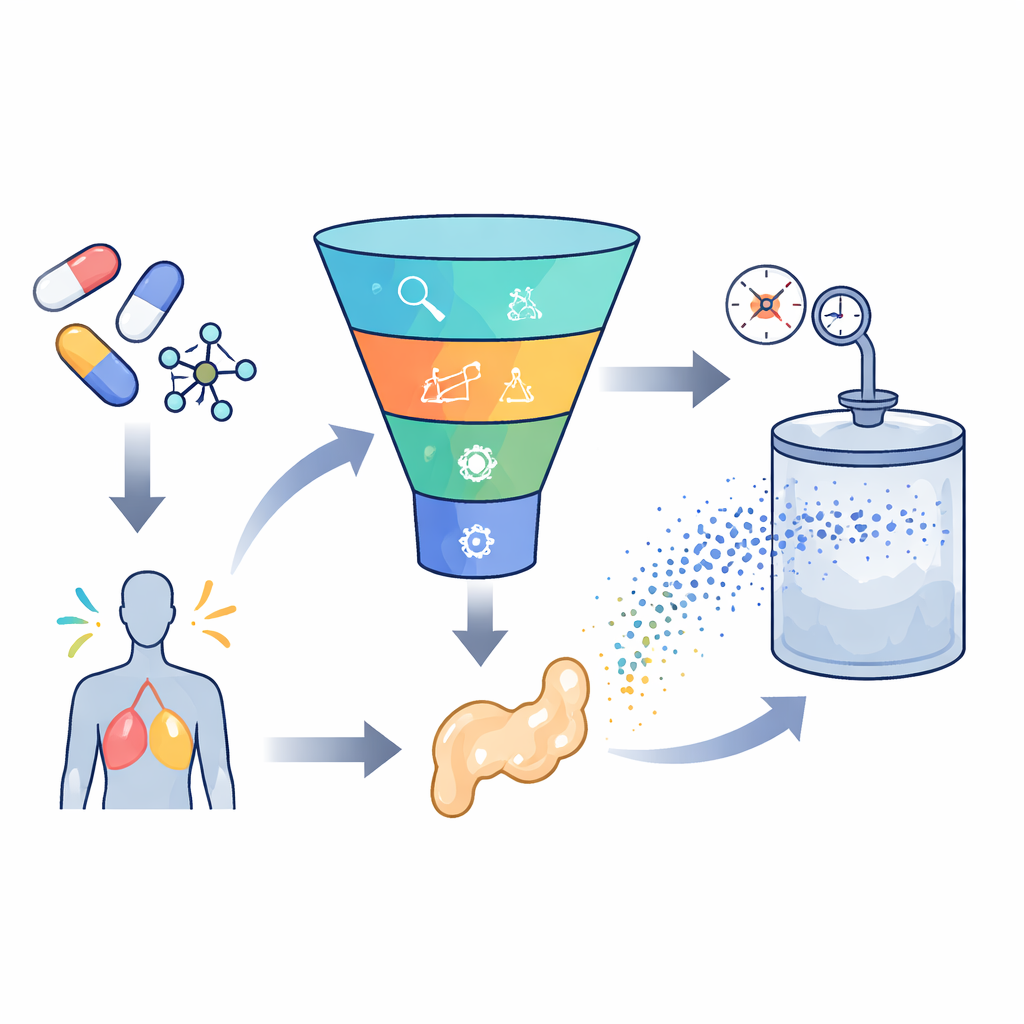
Construire un moteur de prédiction intelligent
Pour relever ce défi, les chercheurs ont rassemblé 252 mesures de haute qualité issues d’expériences antérieures sur sept médicaments très différents, allant de traitements contre les ulcères et l’épilepsie aux antifongiques et antiviraux. Pour chaque point de données, ils ont collecté des conditions de base telles que la température et la pression, ainsi que des propriétés simples du médicament comme la masse molaire et le point de fusion. Ils ont ensuite entraîné plusieurs modèles d’apprentissage automatique pour apprendre le lien entre ces entrées et la quantité de médicament dissous dans le dioxyde de carbone supercritique. Deux grands types de modèles ont été utilisés : la régression par vecteurs de support, qui tente de tracer une courbe lisse à travers les données, et le gradient boosting extrême, une méthode avancée à base d’arbres qui combine de nombreux petits arbres de décision en un prédicteur puissant.
Laisser des algorithmes de recherche inspirés par la nature régler les modèles
Le choix des paramètres internes de ces modèles, appelés hyperparamètres, peut grandement influencer leurs performances. Plutôt que de deviner ou d’employer de simples recherches en grille, l’équipe a emprunté des idées au comportement animal. Ils ont appliqué deux méthodes d’optimisation « bio‑inspirées », l’une basée sur la façon dont les oies cendrées recherchent de la nourriture et migrent, et l’autre inspirée des tactiques de survie des lézards cornus. Ces algorithmes explorent de nombreuses combinaisons de paramètres de modèle et convergent progressivement vers celles qui offrent les prédictions les plus précises avec la moindre erreur. En formulant cela comme un problème à objectifs multiples, les auteurs ont équilibré deux buts simultanément : minimiser l’erreur de prédiction et maximiser la part de la variance des données expliquée par le modèle, tout en surveillant également le temps de calcul.
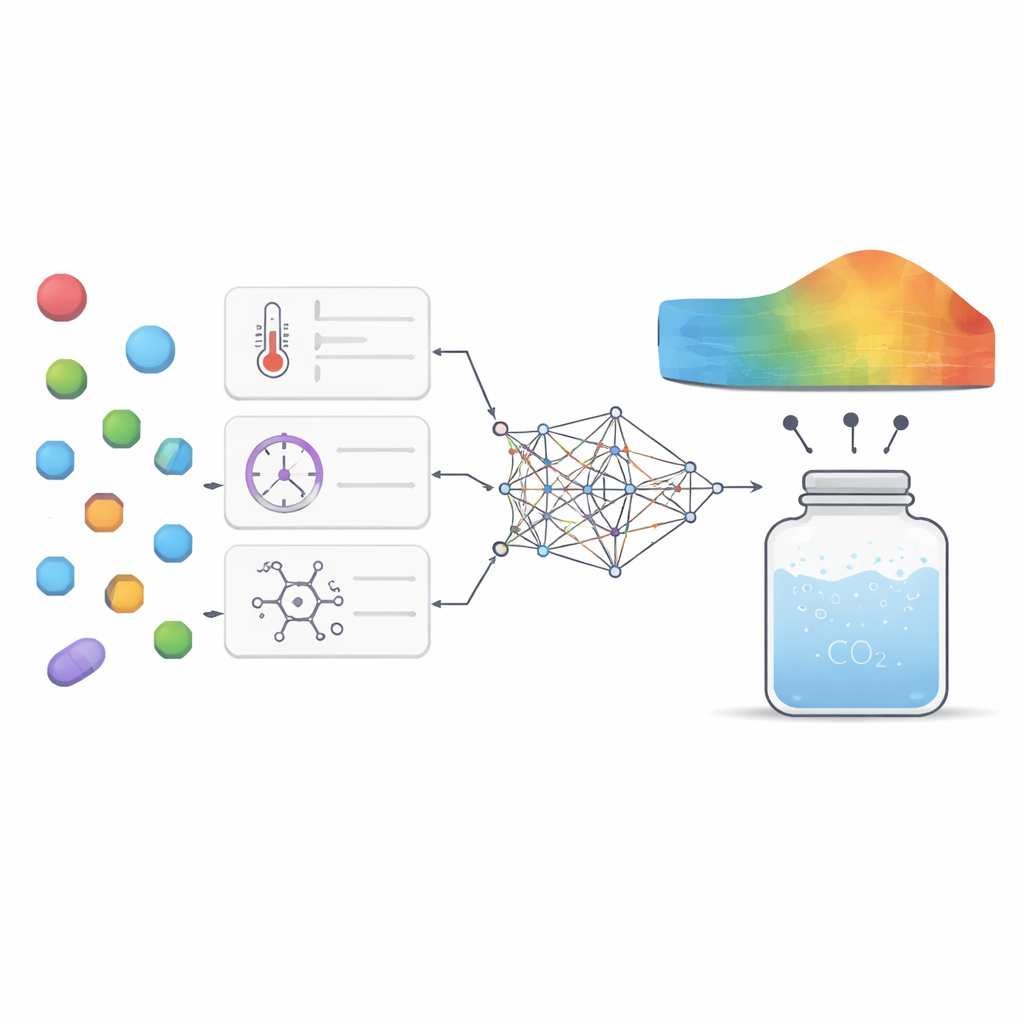
Identifier les leviers les plus influents
Au‑delà de la simple précision, les auteurs souhaitaient que le modèle fournisse un éclairage scientifique plutôt que d’être une « boîte noire » mystérieuse. Ils ont utilisé deux outils d’analyse complémentaires pour évaluer dans quelle mesure chaque facteur d’entrée influençait la sortie du modèle et comment ces facteurs interagissaient. Les deux techniques ont mis en évidence la pression et la masse molaire comme les leviers les plus importants : une pression plus élevée augmentait généralement la solubilité en compactant davantage le dioxyde de carbone, tandis que les molécules plus lourdes avaient tendance à se dissoudre moins facilement. La température et le point de fusion jouaient des rôles plus subtils mais néanmoins significatifs, principalement par leurs interactions avec la pression et en reflétant la cohésion de la structure cristalline du médicament. Le modèle a aussi reproduit des tendances thermodynamiques connues, comme le fait que la variation de température peut soit renforcer soit atténuer l’effet de la pression selon la plage considérée, ce qui donne confiance dans le fait qu’il capture un comportement physique réel plutôt que de se contenter de mémoriser des chiffres.
Ce que signifient les résultats pour le développement des médicaments
Le modèle hybride le plus performant, qui combinait l’approche de gradient boosting avec l’optimiseur inspiré du lézard cornu, a réduit l’erreur de prédiction d’environ 40 % par rapport à une référence non optimisée. Il a bien reproduit non seulement les valeurs moyennes de solubilité observées en expérience, mais aussi leur dispersion et les rares cas de solubilité élevée. Ce niveau de précision signifie que le modèle peut servir d’outil puissant de pré‑sélection : les chercheurs peuvent explorer des plages de pression et de température sur un ordinateur portable avant de s’engager dans des expériences haute‑pression, réduisant ainsi les efforts gaspillés sur des candidats peu prometteurs. Bien que l’approche dépende encore d’un jeu de données modeste et d’un ensemble limité de propriétés moléculaires, et que la version la plus précise soit gourmande en calcul, le cadre montre comment l’apprentissage automatique interprétable peut à la fois accélérer les formulations sans solvant et approfondir notre compréhension des raisons pour lesquelles certains médicaments se dissolvent mieux que d’autres dans le dioxyde de carbone supercritique.
Citation: Khafagy, ES., Lila, A.S.A. & Pishnamazi, M. Accelerating supercritical pharmaceutical formulation via interpretable data-driven prediction of drug solubility. Sci Rep 16, 11006 (2026). https://doi.org/10.1038/s41598-026-44161-9
Mots-clés: solubilité des médicaments, dioxyde de carbone supercritique, apprentissage automatique, formulation pharmaceutique, modélisation pilotée par les données