Clear Sky Science · sv
Påskyndad superkritisk läkemedelsformulering via tolkningsbar datadriven prediktion av läkemedelssubstansers löslighet
Varför detta är viktigt för framtidens läkemedel
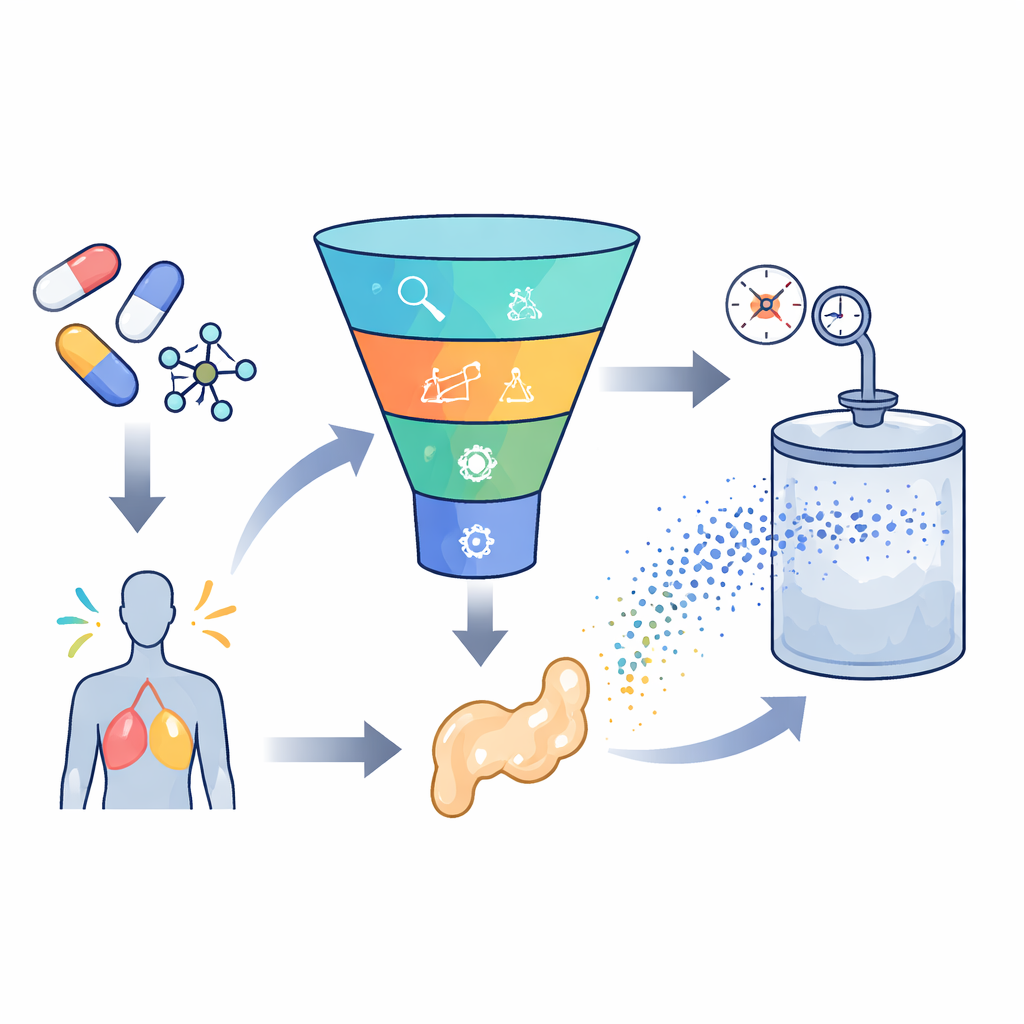
Många lovande läkemedel når aldrig patienterna eftersom de helt enkelt inte löser sig tillräckligt bra för att kroppen ska kunna ta upp dem. Studien som ligger till grund för den här artikeln undersöker hur man på dator kan förutsäga hur lätt olika läkemedel löser sig i en speciell form av koldioxid som kallas superkritisk vätska. Genom att använda moderna datadrivna verktyg syftar författarna till att minska kostsamma laboratoriebaserade försök och fel samt snabba på vägen från molekyl till medicin.
En renare metod för svårlösliga läkemedel
Superkritisk koldioxid beter sig som både vätska och gas, vilket ger den ovanlig förmåga att bära och forma läkemedelsmolekyler. Den kan hjälpa till att skapa mycket små partiklar, ladda läkemedel i leveranssystem och göra detta utan att lämna kvar giftiga lösningsmedel. Men varje läkemedel reagerar olika: förändringar i tryck, temperatur och läkemedlets egen struktur kan dramatiskt ändra hur mycket som löser sig. Att mäta dessa effekter för varje ny förening i högtrycksutrustning är långsamt och dyrt, så möjligheten att förutsäga löslighet utifrån data är mycket lockande för formuleringsexperter och läkemedelstillverkare.
Att bygga en smart prediktionsmotor
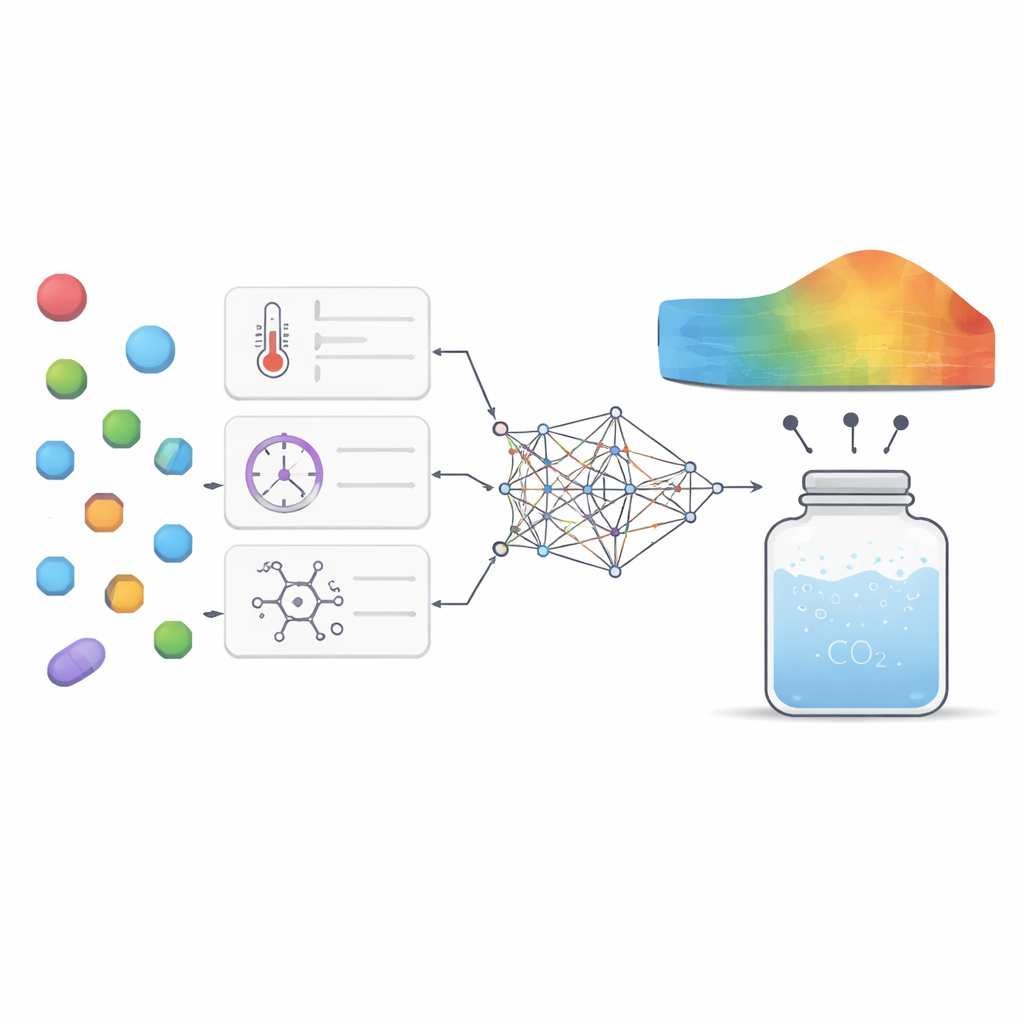
För att ta sig an denna utmaning samlade forskarna 252 högkvalitativa mätvärden från tidigare experiment på sju mycket olika läkemedel, från magsårs- och epilepsimediciner till svamp- och antivirala medel. För varje datapunkt registrerade de grundläggande förhållanden som temperatur och tryck, tillsammans med enkla läkemedelsegenskaper som molekylvikt och smältpunkt. De tränade sedan flera maskininlärningsmodeller för att lära sambandet mellan dessa ingångar och hur mycket av varje läkemedel som löstes i superkritisk koldioxid. Två huvudtyper av modeller användes: supportvektorregering, som försöker dra en jämn kurva genom data, och extreme gradient boosting, en avancerad trädbaserad metod som kombinerar många små beslutsträd till en stark prediktor.
Låt naturinspirerade sökalgoritmer finjustera modellerna
Att välja modellernas interna inställningar, så kallade hyperparametrar, kan i hög grad påverka hur väl de presterar. Istället för att gissa eller använda enkla rutnätsökningar lånade teamet idéer från djurens beteenden. De tillämpade två "bio-inspirerade" optimeringsmetoder, en baserad på hur grågåsar letar efter föda och migrerar, och en annan inspirerad av hornad ödlas överlevnadstaktiker. Dessa algoritmer utforskar många kombinationer av modellinställningar och rör sig gradvis mot de som ger de mest exakta prediktionerna med minst fel. Genom att formulera detta som ett multiobjektivt problem balanserade författarna två mål samtidigt: att minimera prediktionsfelet och maximera hur mycket av variationen i datan modellen förklarar, samtidigt som de hade ögonen på beräkningstid.
Att se vilka reglage som betyder mest
Utöver ren noggrannhet ville författarna att modellen skulle erbjuda vetenskaplig insikt snarare än vara en mystisk "svart låda". De använde två kompletterande analyssystem för att undersöka hur starkt varje indatafaktor påverkade modellens utdata och hur dessa faktorer interagerade. Båda teknikerna framhöll tryck och molekylvikt som de viktigaste reglagen: högre tryck ökade generellt lösligheten genom att packa koldioxiden tätare, medan tyngre molekyler tenderade att lösa sig sämre. Temperatur och smältpunkt spelade mer subtila men fortfarande betydelsefulla roller, huvudsakligen genom att de interagerade med trycket och speglade hur hårt läkemedlets kristallstruktur håller ihop. Modellen reproducerade också kända termodynamiska mönster, såsom hur temperaturförändring kan antingen förstärka eller försvaga tryckets effekt beroende på intervallet, vilket gav förtroende för att den fångade verkligt fysiskt beteende snarare än bara memorering av siffror.
Vad resultaten betyder för läkemedelsutveckling
Den bäst presterande hybrida modellen, som kombinerade gradient-boosting-metoden med hornad ödle-optimeraren, minskade prediktionsfelet med ungefär 40 procent jämfört med en otunad baslinje. Den matchade nära inte bara de genomsnittliga löslighetsvärdena observerade i experimenten, utan också deras spridning och sällsynta höga löslighetsfall. Denna nivå av noggrannhet innebär att modellen kan fungera som ett kraftfullt förhandsurvalsverktyg: forskare kan utforska tryck- och temperaturintervall på en laptop innan de åtar sig högtrycksexperiment, vilket minskar förlorad tid på dåliga kandidater. Även om tillvägagångssättet fortfarande är beroende av en måttlig datamängd och en begränsad uppsättning läkemedelsegenskaper, och den mest exakta versionen är beräkningskrävande, visar ramverket hur tolkningsbar maskininlärning både kan påskynda lösningsmedelsfria formuleringar och fördjupa vår förståelse för varför vissa läkemedel löser sig bättre än andra i superkritisk koldioxid.
Citering: Khafagy, ES., Lila, A.S.A. & Pishnamazi, M. Accelerating supercritical pharmaceutical formulation via interpretable data-driven prediction of drug solubility. Sci Rep 16, 11006 (2026). https://doi.org/10.1038/s41598-026-44161-9
Nyckelord: läkemedelslöslighet, superkritisk koldioxid, maskininlärning, läkemedelsformulering, datadriven modellering