Clear Sky Science · it
Accelerare la formulazione farmaceutica in supercritico tramite predizione interpretabile guidata dai dati della solubilità dei farmaci
Perché questo è importante per le medicine del futuro
Molti farmaci promettenti non arrivano mai ai pazienti perché semplicemente non si dissolvono abbastanza bene da essere assorbiti dall’organismo. Lo studio dietro questo articolo esplora come prevedere, al computer, quanto facilmente diversi farmaci si dissolvono in una forma speciale di anidride carbonica nota come fluido supercritico. Utilizzando strumenti moderni guidati dai dati, gli autori mirano a ridurre i costosi tentativi ed errori di laboratorio e ad accelerare il percorso dalla molecola al medicinale.
Un modo più pulito per produrre farmaci difficili da sciogliere
L’anidride carbonica supercritica si comporta sia come un liquido sia come un gas, conferendole una capacità insolita di trasportare e modellare le molecole dei farmaci. Può aiutare a creare particelle molto piccole, a caricare farmaci in sistemi di rilascio e farlo senza lasciare solventi tossici. Tuttavia, ogni farmaco risponde in modo diverso: variazioni di pressione, temperatura e della struttura stessa del farmaco possono alterare in modo significativo quanto di esso si scioglie. Misurare questi effetti per ogni nuovo composto in apparecchiature ad alta pressione è lento e costoso, perciò poter predire la solubilità a partire dai dati è estremamente interessante per gli scienziati della formulazione e i produttori di farmaci.
Costruire un motore di predizione intelligente
Per affrontare questa sfida, i ricercatori hanno raccolto 252 misure di alta qualità da esperimenti precedenti su sette farmaci molto diversi tra loro, che vanno da medicinali per ulcere ed epilessia fino ad antifungini e antivirali. Per ogni punto dati hanno registrato condizioni di base come temperatura e pressione, insieme a proprietà semplici del farmaco come massa molecolare e punto di fusione. Hanno poi addestrato diversi modelli di machine learning per apprendere il collegamento tra questi input e la quantità di ciascun farmaco disciolta nell’anidride carbonica supercritica. Sono stati utilizzati principalmente due tipi di modelli: la regressione con support vector, che cerca di tracciare una curva liscia attraverso i dati, e l’extreme gradient boosting, un metodo avanzato basato su alberi che combina molti piccoli alberi decisionali in un predittore potente.
Lasciare che algoritmi ispirati alla natura tarino i modelli
Scegliere i parametri interni di questi modelli, noti come iperparametri, può influenzare molto le loro prestazioni. Invece di indovinare o usare semplici ricerche a griglia, il team ha mutuato idee dal comportamento animale. Hanno applicato due metodi di ottimizzazione “bio-ispirati”, uno basato sul modo in cui le oche grigie cercano cibo e migrano, e un altro ispirato alle tattiche di sopravvivenza delle lucertole cornute. Questi algoritmi esplorano molte combinazioni di impostazioni del modello e si muovono gradualmente verso quelle che forniscono previsioni più accurate con il minor errore. Inquadrando il problema come multi-obiettivo, gli autori hanno bilanciato due obiettivi contemporaneamente: minimizzare l’errore di previsione e massimizzare la quota di variabilità dei dati che il modello spiega, tenendo anche d’occhio il tempo di calcolo.
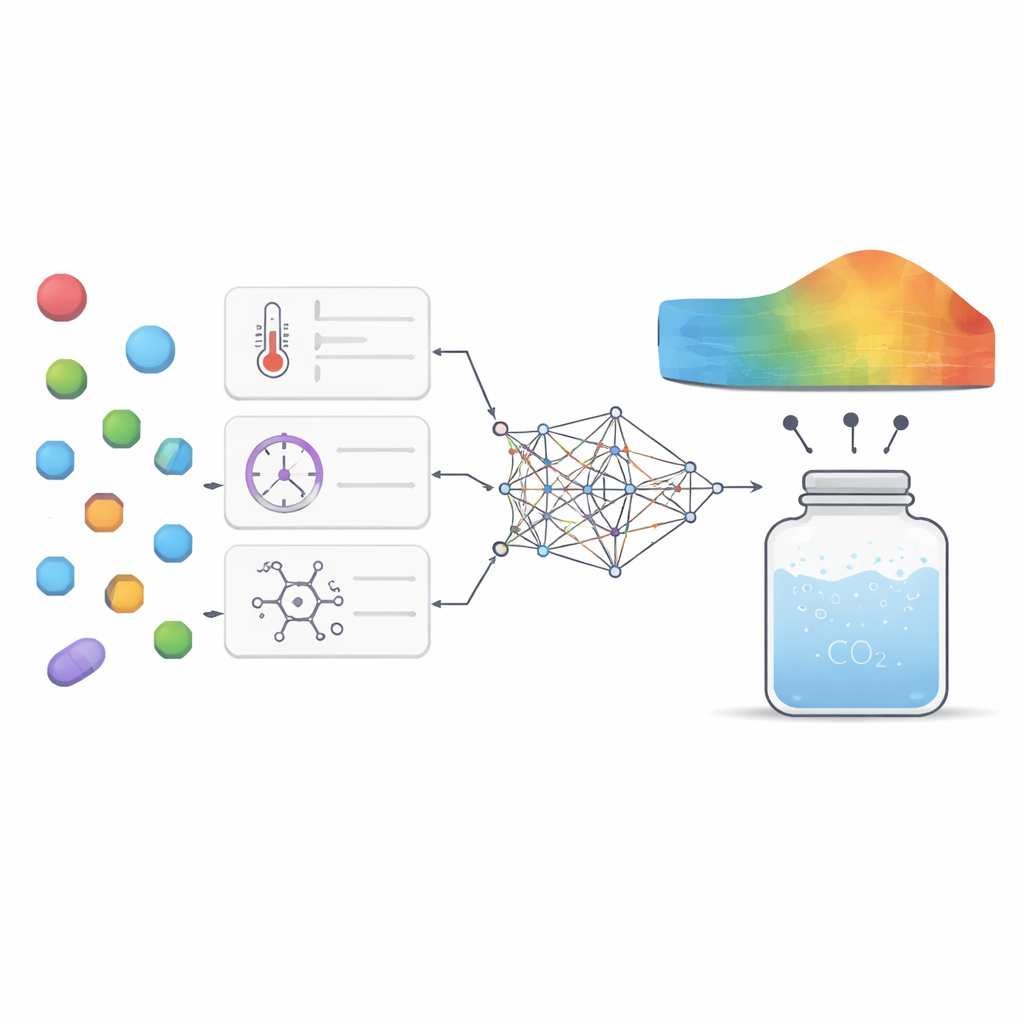
Capire quali leve contano di più
Oltre alla sola accuratezza, gli autori volevano che il modello offrisse intuizioni scientifiche invece di essere una misteriosa “scatola nera”. Hanno usato due strumenti di analisi complementari per chiedere quanto ciascun fattore di input abbia influenzato l’output del modello e come questi fattori interagiscano. Entrambe le tecniche hanno evidenziato la pressione e la massa molecolare come le leve più importanti: una pressione più alta generalmente aumentava la solubilità comprimendo più strettamente l’anidride carbonica, mentre le molecole più pesanti tendevano a dissolversi con più difficoltà. Temperatura e punto di fusione hanno avuto ruoli più sottili ma comunque significativi, principalmente tramite interazioni con la pressione e riflettendo quanto saldamente la struttura cristallina del farmaco tenga insieme le molecole. Il modello ha anche riprodotto schemi termodinamici noti, come il fatto che una variazione di temperatura può aumentare o diminuire l’effetto della pressione a seconda dell’intervallo considerato, rafforzando la fiducia che stesse catturando comportamenti fisici reali anziché memorizzare solo numeri.
Cosa significano i risultati per lo sviluppo dei farmaci
Il modello ibrido che ha dato le migliori prestazioni, che combinava l’approccio gradient boosting con l’ottimizzatore ispirato alla lucertola cornuta, ha ridotto l’errore di previsione di circa il 40 percento rispetto a un modello di riferimento non ottimizzato. Ha riprodotto fedelmente non solo i valori medi di solubilità osservati negli esperimenti, ma anche la loro dispersione e i casi rari di alta solubilità. Questo livello di accuratezza significa che il modello può funzionare come potente strumento di preselezione: i ricercatori possono esplorare intervalli di pressione e temperatura su un portatile prima di impegnarsi in esperimenti ad alta pressione, riducendo gli sforzi sprecati su candidati scadenti. Sebbene l’approccio dipenda ancora da un dataset modesto e da un insieme limitato di proprietà dei farmaci, e la versione più accurata richieda risorse computazionali rilevanti, il quadro mostra come l’apprendimento automatico interpretabile possa sia accelerare le formulazioni senza solventi sia approfondire la nostra comprensione del perché alcuni farmaci si sciolgono meglio di altri nell’anidride carbonica supercritica.
Citazione: Khafagy, ES., Lila, A.S.A. & Pishnamazi, M. Accelerating supercritical pharmaceutical formulation via interpretable data-driven prediction of drug solubility. Sci Rep 16, 11006 (2026). https://doi.org/10.1038/s41598-026-44161-9
Parole chiave: solubilità dei farmaci, anidride carbonica supercritica, apprendimento automatico, formulazione farmaceutica, modellizzazione guidata dai dati