Clear Sky Science · zh
无监督学习在高维人类蛋白质组数据中揭示新的疾病相关蛋白
肉眼看不见的血液线索
我们的血液中充满了能在我们感觉不适之前就静默反映体内状况的蛋白质。临床上已有少数蛋白被用作检测指标,但现代技术现在可以同时测量成千上万种蛋白。本研究提出了一个简单且意义重大的问题:如果让计算机在不事先指明目标的情况下自由探索这些海量的血液蛋白图谱,它能否发现我们甚至未曾想到要检测的新的疾病关联?
让数据自己发声
大多数医学算法是用“健康”或“有高血压”等明确标签来训练的。这种方法很有力,但在面对每人数千项测量时,可能会错过意外模式。这里,研究者走相反的路线:他们使用“无监督”学习,仅根据血液蛋白模式的相似性将人群分组,而不知晓谁患有何种疾病。团队利用了一个巨大的资源——英国生物样本库(UK Biobank),聚焦于近53,000名接受了2,923种蛋白检测的参与者。目标是检验这片数字海洋中的自然分组是否与现实世界的疾病相吻合,并揭示新的蛋白候选者。
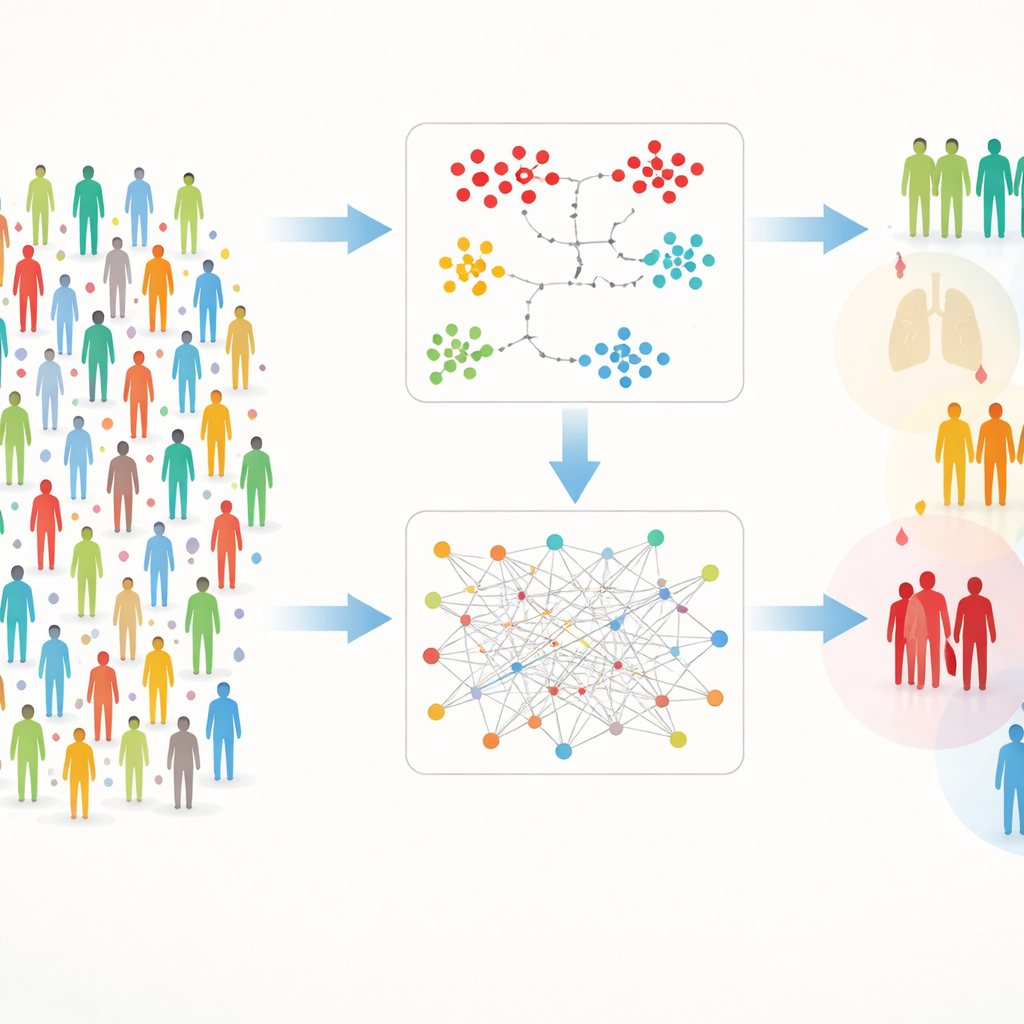
两条路径寻找隐匿群组
处理如此丰富的数据会遇到实际困难:测量值有时缺失,蛋白数量之多也可能掩盖信号。为了解决这些问题,作者构建了一个双轨框架,称为 DIRAM/COD。一路(DIRAM)通过切分数据以避免缺失值,将复杂性降维到二维,然后寻找密集的“岛屿”式相似人群;另一条路(DIRCOD)则先用谨慎的估算填补缺失值,再利用借鉴自网络科学的社区发现方法识别群组。两条路线反复精炼,最终得出55个不同的簇,这些簇在血液蛋白指纹上存在有意义的差异。
与真实疾病相映的簇
簇确定后,团队检查了年龄、性别以及关键的医疗诊断在各簇中的分布。某些簇在器官衰竭、移植和癌症等严重疾病上表现出富集,表明其蛋白签名捕捉到了重病患者的生物学特征。作者随后聚焦三种疾病:乳糜泻、高血压和白血病。他们考察哪些蛋白在这些疾病更常见的簇中倾向于异常升高或降低。通过仅使用这些蛋白和简单阈值“重建”富含疾病的群组,研究表明这些蛋白模式能够强烈反映疾病风险——即便将参与者混合来自整个研究人群中亦然。
新的蛋白嫌疑与关系重构
这种方法不仅确认了已知的角色,还凸显了新的候选蛋白。对于高血压,诸如 UBE2L6、HNRNPUL1 和 BECN1 等蛋白脱颖而出,它们在其他研究中曾与血管或心脏问题相关。对于乳糜泻,IGF2BP3 显得尤为重要,这与早期提示其有助于维持肠道屏障的证据一致,另有 NRXN3 和 CACNB1 等有前景的蛋白。在与白血病相关的簇中,多种蛋白(包括 LRCH4、WDR46、SERPINB1 和 NUB1)表现出改变。不仅它们的丰度不同,它们之间共同升降的方式也发生变化,暗示在癌症和自身免疫疾病中体内调控网络发生了重构。
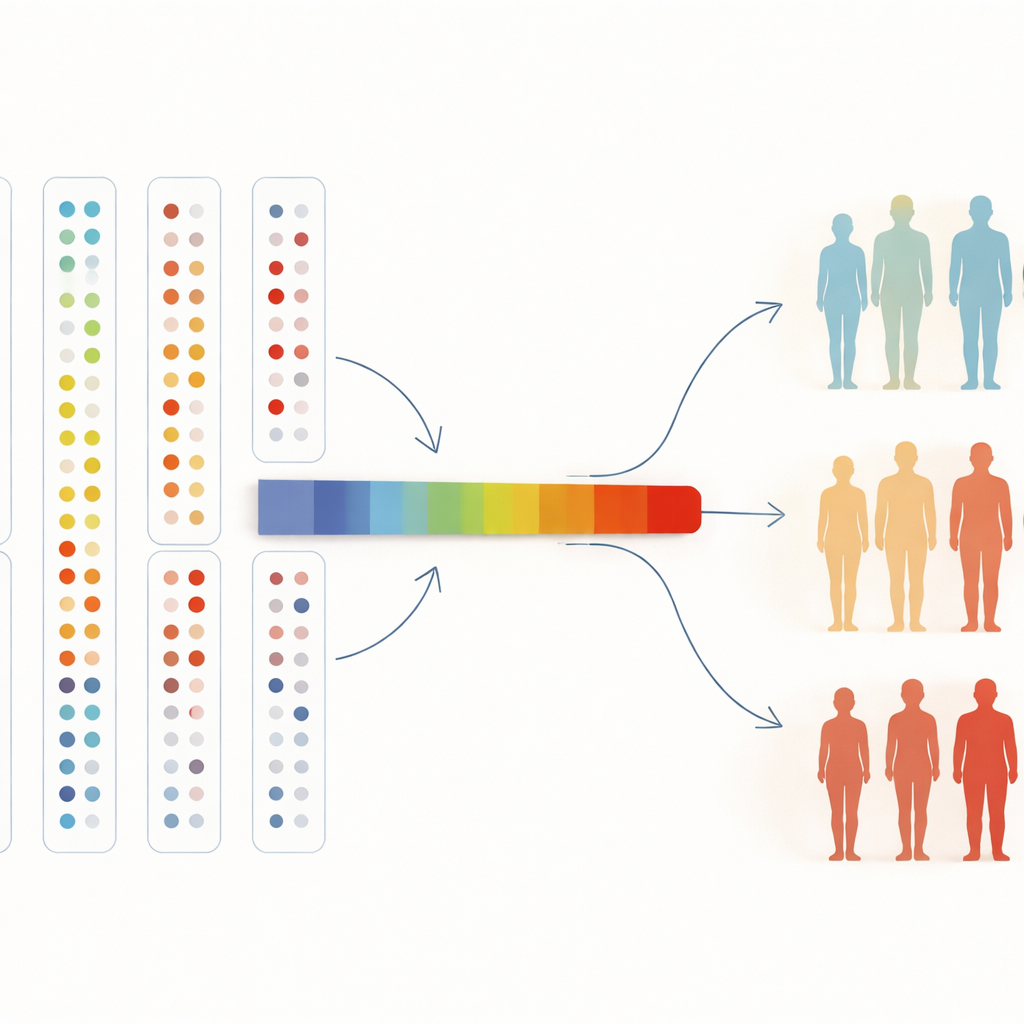
从血液图谱走向未来医学
为了同时理解大量蛋白,研究者还将它们压缩到单一“轴”上,用以总结总体模式变化。沿着这条轴,高血压或乳糜泻的患病几率稳步上升,这一趋势在将分析推广到全体研究参与者时仍然成立。对于非专业读者来说,结论很直接:通过让算法基于成千上万种血液蛋白自由地对人群进行排序,我们可以发现自然形成的健康相关群体、验证已知的疾病标志,并发现新的标志。随着生物样本库扩展到数十万甚至更多参与者和更多蛋白,这类无监督探索有望帮助医生更早发现疾病、理解为何有人患病而他人不患,以及指引未来治疗的新靶点。
引用: Bernard, E., Wang, Y., Chen, M. et al. Unsupervised learning reveals novel disease-associated proteins in high-dimensional human proteomic data. Sci Rep 16, 10185 (2026). https://doi.org/10.1038/s41598-026-41385-7
关键词: 血液蛋白, 无监督学习, 生物标志物, 精准医学, 疾病风险