Clear Sky Science · ru
Самостоятельное обучение выявляет новые белки, связанные с болезнями, в высокоразмерных протеомных данных человека
Подсказки в крови, скрытые на виду
Наша кровь полна белков, которые незаметно отражают происходящее в организме задолго до появления симптомов. Врачи уже используют несколько таких белков в анализах, но современные технологии позволяют измерять теперь тысячи показателей одновременно. В этом исследовании звучит простой вопрос с большими последствиями: если позволить компьютеру свободно исследовать эти обширные карты белков крови, не указывая, что искать, сможет ли он обнаружить новые связи с заболеваниями, о которых мы даже не подумали тестировать?
Дать данным самим высказаться
Большинство медицинских алгоритмов обучаются на чётких метках, таких как «здоров» или «имеет гипертензию». Такой подход силён, но может упускать неожиданные закономерности, особенно при наличии тысяч измерений на человека. Здесь исследователи идут противоположным путём: они используют «самостоятельное» (unsupervised) обучение, которое группирует людей исключительно по сходству их профилей белков крови, не зная, у кого какое заболевание. Команда работала с огромным ресурсом — UK Biobank, сосредоточившись на почти 53 000 участниках, у которых измеряли 2 923 различных белка. Их цель — выяснить, совпадут ли естественные группировки в этом океане чисел с реальными заболеваниями и укажут ли на новых подозреваемых среди белков.
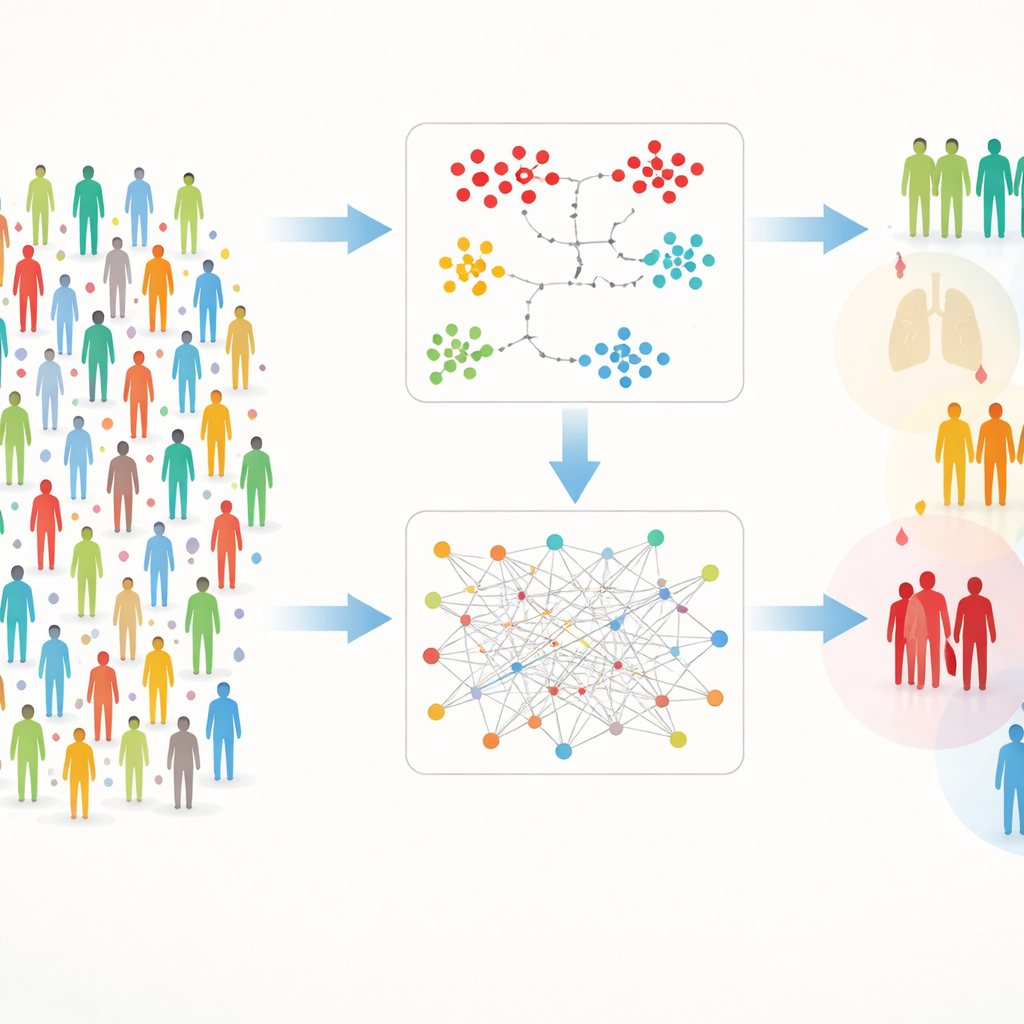
Два пути к обнаружению скрытых групп
Работа с такими богатыми данными сопряжена с практическими трудностями: иногда отсутствуют измерения, а огромное число белков может заглушить сигналы. Чтобы справиться с этим, авторы построили двухдорожечную структуру, которую назвали DIRAM/COD. Одна дорожка (DIRAM) разрезает данные, чтобы избежать пропусков, снижает размерность до двух измерений и затем ищет плотные «острова» похожих людей. Другая дорожка (DIRCOD) сначала аккуратно заполняет пропуски, затем использует метод поиска сообществ из теории сетей для выявления групп. Обе дорожки многократно уточнялись и в итоге дали 55 различных кластеров участников, чьи белковые «отпечатки» крови различаются значимым образом.
Кластеры, отражающие реальные болезни
Как только кластеры были определены, команда проверила распределение по возрасту, полу и, что важно, по медицинским диагнозам в рамках этих групп. Некоторые кластеры оказались обогащены серьёзными состояниями, такими как печёночная недостаточность, трансплантации и рак, что указывает на то, что их белковые подписи захватывают биологию тяжело больных пациентов. Авторы затем сосредоточились на трёх состояниях: целиакии, гипертензии и лейкемии. Они выясняли, какие белки обычно были необычно повышены или понижены в кластерах, где эти болезни встречались чаще. «Воссоздавая» группы, богатые этими болезнями, используя только эти белки и простые пороги, они показали, что эти белковые паттерны тесно коррелировали с шансами заболевания — даже при смешивании участников из всего исследования.
Новые подозреваемые белки и меняющиеся взаимосвязи
Этот подход сделал больше, чем подтвердил известных действующих лиц; он выделил новых кандидатов. Для гипертензии заметными оказались белки такие как UBE2L6, HNRNPUL1 и BECN1, все ранее связывавшиеся с проблемами сосудов или сердца в других работах. Для целиакии особенно важным оказался IGF2BP3, что согласуется с ранними указаниями на его роль в поддержании барьера кишечника, наряду с другими перспективными белками, такими как NRXN3 и CACNB1. В кластерах, связанных с лейкемией, несколько белков, включая LRCH4, WDR46, SERPINB1 и NUB1, показали изменённое поведение. Изменялись не только их уровни, но и то, как они повышались и понижались вместе, что намекает на перенастройку внутренних регуляторных систем организма при раке и аутоиммунных заболеваниях.
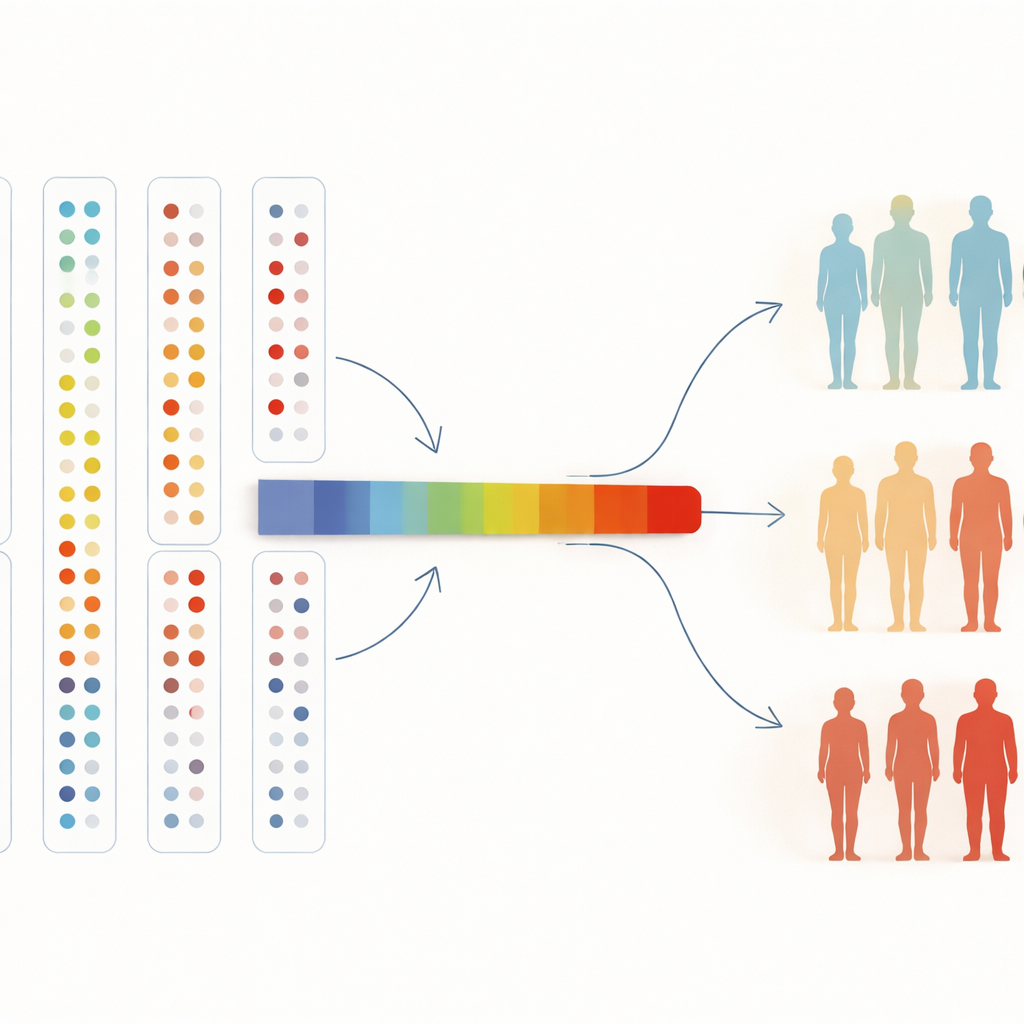
От карт крови к медицине будущего
Чтобы осмыслить множество белков одновременно, исследователи также сжали их в единую «ось», суммирующую общие изменения паттернов. По этой оси вероятность иметь гипертензию или целиакию возрастала плавно, и эта тенденция сохранялась даже при расширении анализа на всех участников исследования. Для неспециалиста главный вывод прост: позволив алгоритмам свободно сортировать людей на основе тысяч белков крови, мы можем найти естественные группы, связанные со здоровьем, подтвердить известные маркёры заболеваний и обнаружить новые. По мере того как биобанки вырастут до сотен тысяч человек и количество измеряемых белков увеличится, такого рода самостоятельное исследование может помочь врачам диагностировать болезни раньше, понять, почему одни люди болеют, а другие нет, и указать на новые цели для будущего лечения.
Цитирование: Bernard, E., Wang, Y., Chen, M. et al. Unsupervised learning reveals novel disease-associated proteins in high-dimensional human proteomic data. Sci Rep 16, 10185 (2026). https://doi.org/10.1038/s41598-026-41385-7
Ключевые слова: белки крови, самостоятельное обучение, биомаркеры, персонализированная медицина, риск заболевания