Clear Sky Science · de
Unüberwachtes Lernen entdeckt neuartige krankheitsassoziierte Proteine in hochdimensionalen humanen Proteomdaten
Im Blut verborgene Hinweise in aller Deutlichkeit
Unser Blut ist voller Proteine, die lange bevor wir uns krank fühlen, still widerspiegeln, was in unserem Körper vor sich geht. Ärztinnen und Ärzte verwenden bereits eine Handvoll dieser Proteine als Tests, doch moderne Techniken können jetzt Tausende gleichzeitig messen. Die vorliegende Studie stellt eine einfache Frage mit großen Folgen: Wenn wir einen Computer frei in diesen riesigen Landkarten von Blutproteinen suchen lassen, ohne ihm vorzuschreiben, wonach er suchen soll, kann er dann neue Verknüpfungen zu Krankheiten entdecken, an die wir nicht einmal gedacht haben zu testen?
Die Daten selbst zu Wort kommen lassen
Die meisten medizinischen Algorithmen werden mit klaren Labels wie „gesund“ oder „hat Hypertonie“ trainiert. Dieser Ansatz ist mächtig, kann aber unerwartete Muster übersehen, besonders wenn Tausende Messwerte pro Person vorliegen. Die Forschenden wählen hier den umgekehrten Weg: Sie verwenden unüberwachtes Lernen, das Menschen rein nach Ähnlichkeit ihrer Blutproteinmuster gruppiert, ohne zu wissen, wer welche Erkrankung hat. Das Team arbeitete mit einer riesigen Ressource, der UK Biobank, und konzentrierte sich auf fast 53.000 Teilnehmende, bei denen 2.923 verschiedene Proteine im Blut gemessen wurden. Ihr Ziel war zu prüfen, ob natürliche Gruppierungen in diesem Zahlenmeer mit realen Krankheiten übereinstimmen und neue Verdächtige unter den Proteinen aufdecken würden.
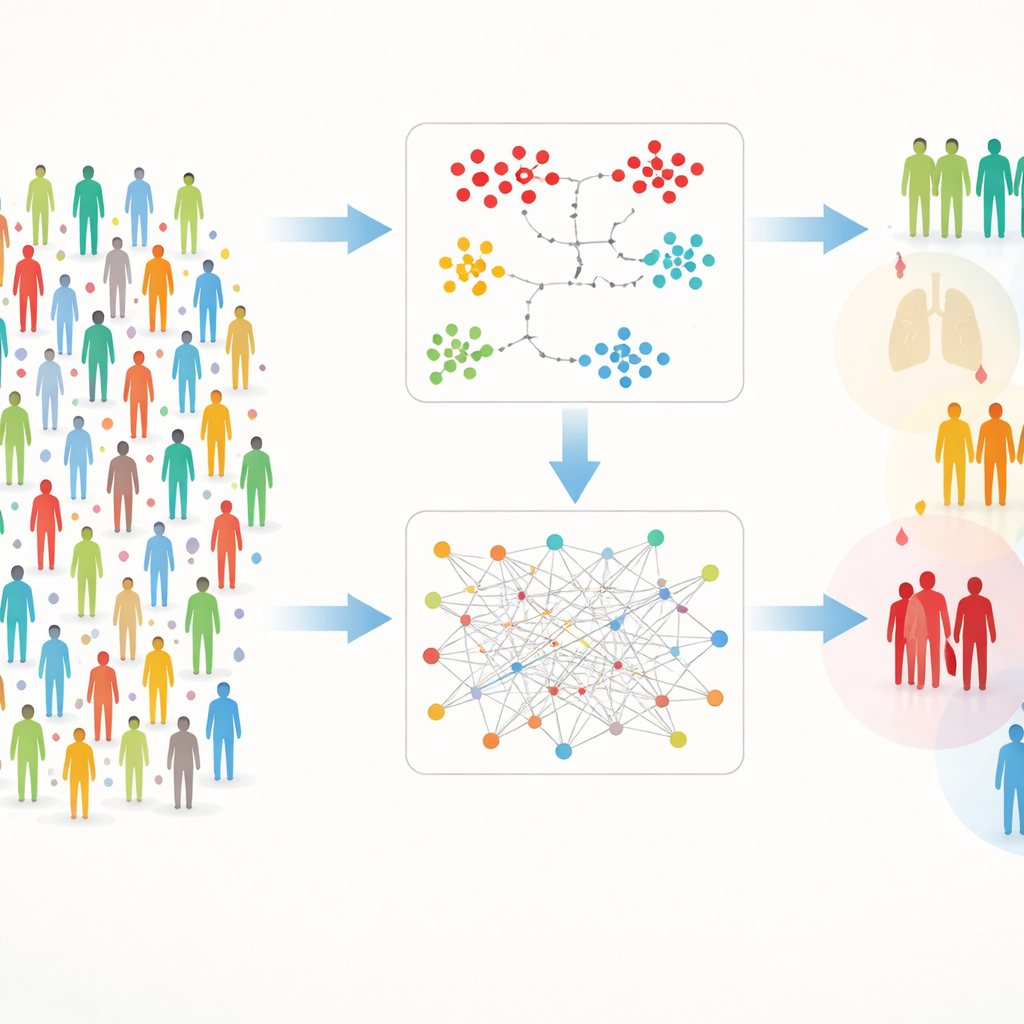
Zwei Wege, versteckte Gruppen zu finden
Mit so reichen Daten zu arbeiten bringt praktische Hürden mit sich: Messwerte fehlen gelegentlich, und die schiere Zahl der Proteine kann Signale übertönen. Um dem zu begegnen, entwickelten die Autorinnen und Autoren einen zweigleisigen Rahmen, den sie DIRAM/COD nennen. Ein Pfad (DIRAM) teilt die Daten, um fehlende Werte zu vermeiden, reduziert die Komplexität auf zwei Dimensionen und sucht dann nach dichten „Inseln“ ähnlicher Personen. Der andere Pfad (DIRCOD) füllt zunächst fehlende Werte mit sorgfältigen Schätzungen auf und nutzt anschließend eine aus der Netzwerkwissenschaft entliehene Community-Erkennung, um Gruppen zu identifizieren. Beide Pfade wurden wiederholt verfeinert und führten schließlich zu 55 unterscheidbaren Clustern von Teilnehmenden, deren Blutprotein-Fingerabdrücke sich in sinnvollen Weisen unterscheiden.
Cluster, die reale Krankheiten widerspiegeln
Sobald die Cluster definiert waren, prüfte das Team, wie Alter, Geschlecht und vor allem medizinische Diagnosen darin verteilt waren. Bestimmte Cluster zeigten eine Anreicherung für schwere Zustände wie Organversagen, Transplantationen und Krebs, was darauf hindeutet, dass ihre Proteinsignaturen die Biologie sehr kranker Patientinnen und Patienten erfassten. Die Autorinnen und Autoren zoomten anschließend auf drei Erkrankungen: Zöliakie, Hypertonie und Leukämie. Sie fragten, welche Proteine in den Clustern, in denen diese Krankheiten häufiger vorkamen, ungewöhnlich hoch oder niedrig waren. Indem sie krankheitsreiche Gruppen allein anhand dieser Proteine und einfacher Schwellenwerte „rekonstruierten“, zeigten sie, dass diese Proteinmuster die Krankheitswahrscheinlichkeit stark abbildeten — selbst wenn Teilnehmende aus der gesamten Studie gemischt wurden.
Neue Proteinverdächtige und veränderte Zusammenhänge
Dieser Ansatz bestätigte mehr als nur bekannte Akteure; er rückte neue Kandidaten ins Rampenlicht. Bei Hypertonie hoben sich Proteine wie UBE2L6, HNRNPUL1 und BECN1 hervor, die zuvor bereits mit Gefäß- oder Herzproblemen in Verbindung gebracht worden waren. Bei Zöliakie erwies sich IGF2BP3 als besonders wichtig, was zu früheren Hinweisen passt, dass es zur Erhaltung der Darmbarriere beiträgt, zusammen mit weiteren vielversprechenden Proteinen wie NRXN3 und CACNB1. In leukämieassoziierten Clustern zeigten mehrere Proteine, darunter LRCH4, WDR46, SERPINB1 und NUB1, verändertes Verhalten. Nicht nur ihre Konzentrationen unterschieden sich, sondern auch die Art, wie sie gemeinsam anstiegen und abfielen — ein Hinweis auf eine Umverdrahtung der inneren Kontrollsysteme des Körpers bei Krebs und Autoimmunerkrankungen.
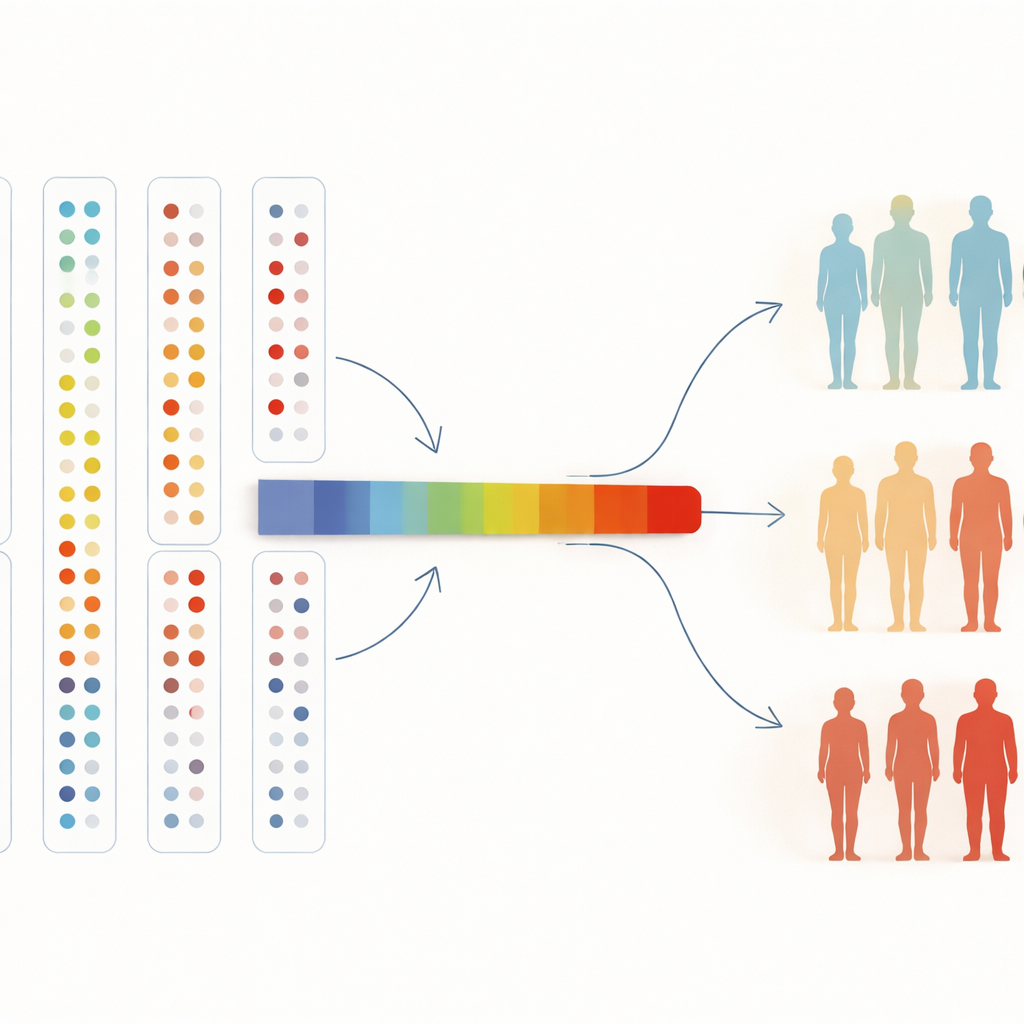
Von Blutkarten zur Medizin der Zukunft
Um viele Proteine gleichzeitig verständlich zu machen, komprimierten die Forschenden sie außerdem auf eine einzelne „Achse“, die die allgemeinen Musteränderungen zusammenfasst. Entlang dieser Achse stiegen die Chancen, Hypertonie oder Zöliakie zu haben, stetig an; dieser Trend hielt auch, als sie die Analyse auf alle Studienteilnehmenden ausweiteten. Für Nicht-Fachleute ist die Schlussfolgerung einfach: Indem Algorithmen Menschen anhand von Tausenden Blutproteinen frei sortieren, können wir natürliche gesundheitsbezogene Gruppen finden, bekannte Krankheitsmarker bestätigen und neue aufspüren. Wenn Biobanken auf Hunderttausende von Menschen und noch mehr Proteine wachsen, könnte diese Art unüberwachter Exploration Ärztinnen und Ärzten helfen, Krankheiten früher zu erkennen, zu verstehen, warum manche Menschen krank werden und andere nicht, und auf neue Ziele für zukünftige Therapien hinweisen.
Zitation: Bernard, E., Wang, Y., Chen, M. et al. Unsupervised learning reveals novel disease-associated proteins in high-dimensional human proteomic data. Sci Rep 16, 10185 (2026). https://doi.org/10.1038/s41598-026-41385-7
Schlüsselwörter: Blutproteine, unüberwachtes Lernen, Biomarker, Präzisionsmedizin, Krankheitsrisiko