Clear Sky Science · it
L’apprendimento non supervisionato rivela nuove proteine associate a malattie in dati proteomici umani ad alta dimensionalità
Indizi nel sangue nascosti in bella vista
Il nostro sangue è pieno di proteine che riflettono silenziosamente ciò che accade dentro il corpo molto prima che ci sentiamo male. I medici già usano una manciata di queste proteine come test, ma la tecnologia moderna può misurarne migliaia contemporaneamente. Questo studio pone una domanda semplice ma dalle grandi implicazioni: se lasciamo che un computer esplori liberamente queste vaste mappe proteiche del sangue senza dirgli cosa cercare, può scoprire nuovi legami con le malattie che non avevamo nemmeno pensato di testare?
Lasciare che i dati parlino da soli
La maggior parte degli algoritmi medici è addestrata con etichette chiare come “sano” o “ha ipertensione”. Questo approccio è potente ma può perdere schemi inattesi, soprattutto quando ci si trova di fronte a migliaia di misure per persona. Qui i ricercatori adottano la strada opposta: usano l’apprendimento “non supervisionato”, che raggruppa le persone esclusivamente in base alla somiglianza dei loro profili proteici nel sangue, senza sapere chi ha quale malattia. Il team ha lavorato con una risorsa enorme, l’UK Biobank, concentrandosi su quasi 53.000 partecipanti il cui sangue era stato testato per 2.923 diverse proteine. L’obiettivo era verificare se i raggruppamenti naturali in questo oceano di numeri si allineassero con malattie reali e rivelassero nuovi sospetti tra le proteine.
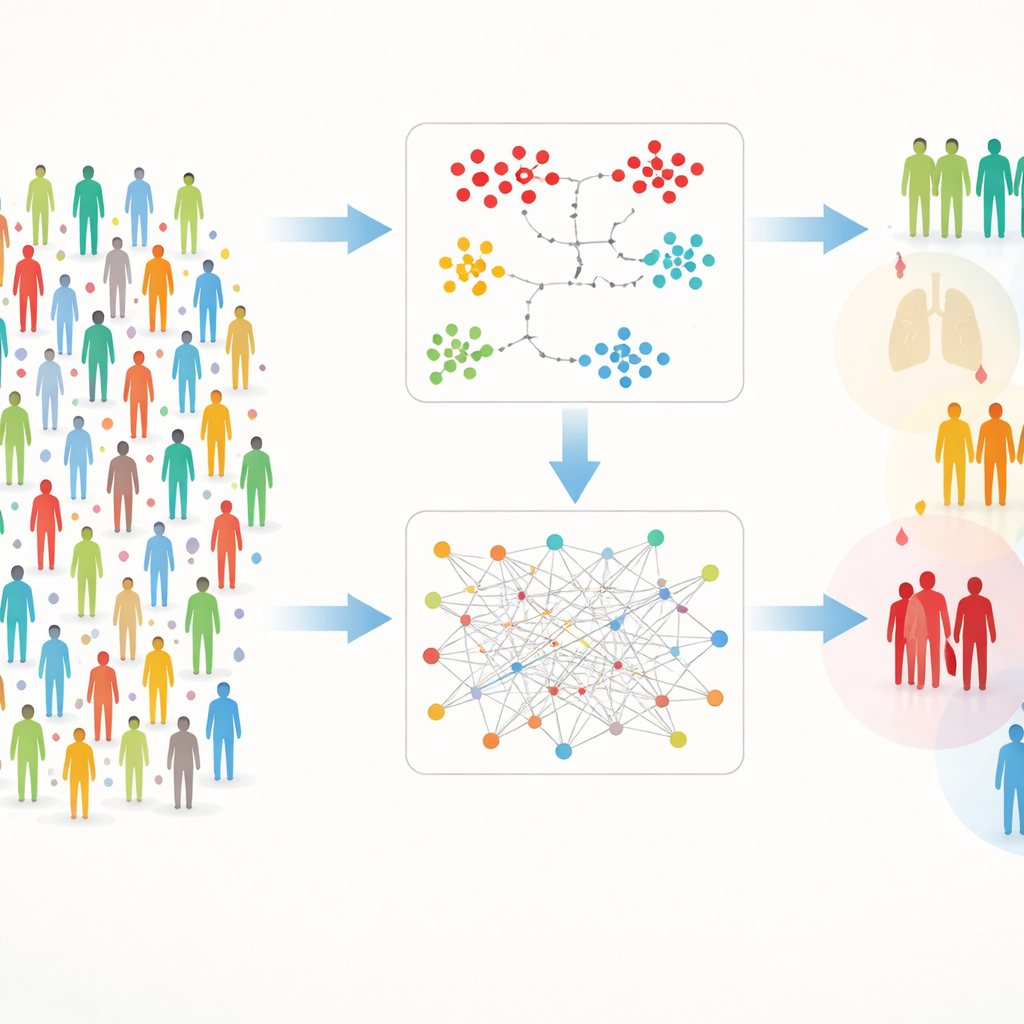
Due strade per trovare gruppi nascosti
Lavorare con dati così ricchi comporta ostacoli pratici: a volte mancano misure e il semplice numero di proteine può sommergere i segnali. Per affrontare questo problema, gli autori hanno costruito un framework a doppio binario che chiamano DIRAM/COD. Un binario (DIRAM) suddivide i dati per evitare valori mancanti, riduce la complessità a due dimensioni e poi cerca “isole” dense di persone simili. L’altro binario (DIRCOD) riempie prima i valori mancanti con stime attente, quindi utilizza un metodo di individuazione di comunità preso in prestito dalla scienza delle reti per rilevare i gruppi. Entrambi i percorsi vengono ripetutamente raffinati, portando infine a 55 cluster distinti di partecipanti i cui profili proteici nel sangue differiscono in modi significativi.
Cluster che rispecchiano malattie reali
Una volta definiti i cluster, il team ha verificato come età, sesso e, soprattutto, le diagnosi mediche fossero distribuite tra essi. Alcuni cluster risultavano arricchiti di condizioni gravi come insufficienza d’organo, trapianti e cancro, suggerendo che le loro firme proteiche catturavano la biologia di pazienti molto malati. Gli autori si sono poi concentrati su tre condizioni: celiachia, ipertensione e leucemia. Hanno esaminato quali proteine tendevano a essere insolitamente alte o basse nei cluster in cui queste malattie erano più comuni. “Ricreando” gruppi ricchi di malattia usando solo quelle proteine e soglie semplici, hanno dimostrato che questi schemi proteici seguivano strettamente le probabilità di malattia—anche mescolando partecipanti provenienti da tutto lo studio.
Nuovi sospetti proteici e relazioni che cambiano
Questo approccio ha fatto più che confermare attori noti; ha messo in luce nuovi candidati. Per l’ipertensione sono emerse proteine come UBE2L6, HNRNPUL1 e BECN1, tutte precedentemente collegate a problemi vascolari o cardiaci in altri studi. Per la celiachia, IGF2BP3 è risultata particolarmente importante, coerente con indizi precedenti che suggeriscono un ruolo nel mantenimento della barriera intestinale, insieme ad altre proteine promettenti come NRXN3 e CACNB1. Nei cluster correlati alla leucemia, diverse proteine, tra cui LRCH4, WDR46, SERPINB1 e NUB1, hanno mostrato comportamenti alterati. Non solo i loro livelli differivano, ma anche il modo in cui aumentavano o diminuivano insieme è cambiato, suggerendo una riorganizzazione dei sistemi di controllo interni del corpo nel cancro e nelle malattie autoimmuni.
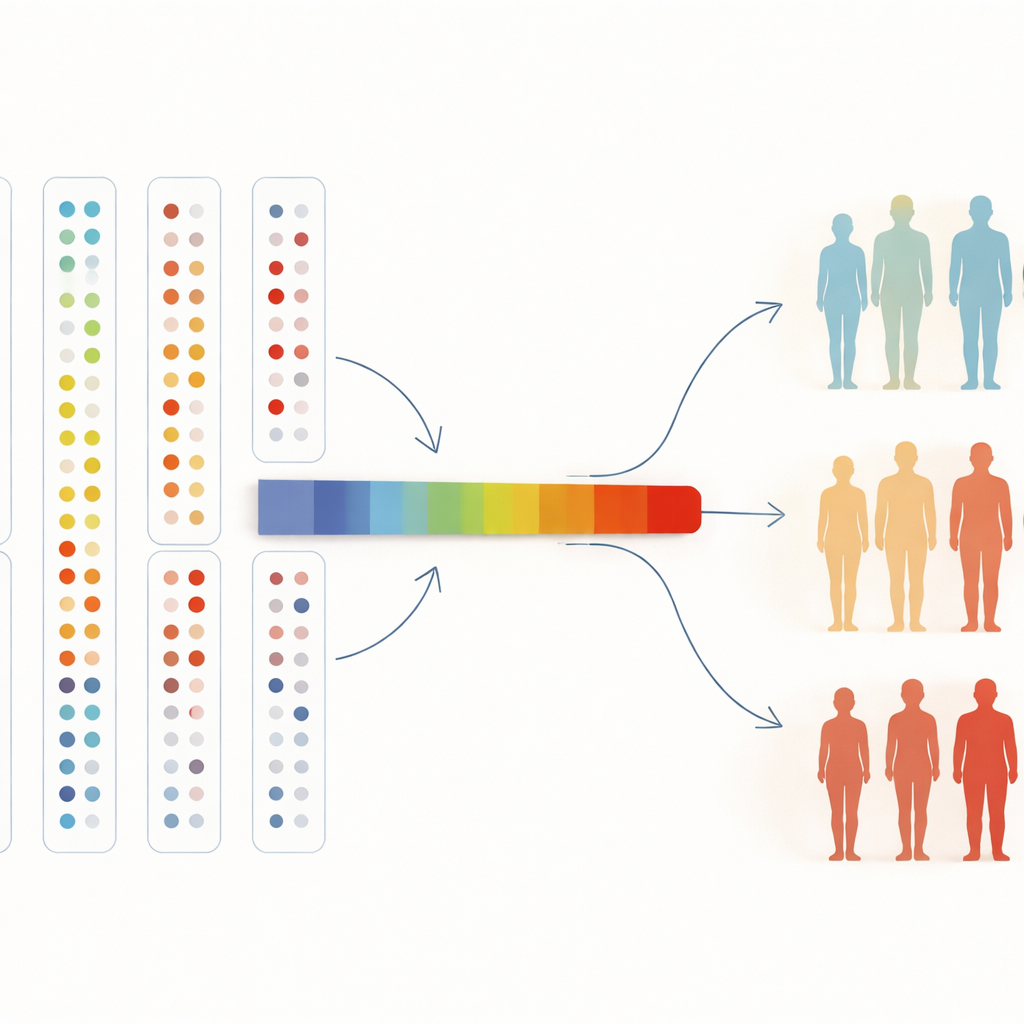
Dalle mappe del sangue alla medicina del futuro
Per interpretare molte proteine contemporaneamente, i ricercatori le hanno anche compresse in un unico “asse” che riassume i cambiamenti del profilo complessivo. Lungo questo asse, le probabilità di avere ipertensione o celiachia aumentavano progressivamente, e questa tendenza è rimasta valida anche estendendo l’analisi a tutti i partecipanti dello studio. Per chi non è specialista, la conclusione è semplice: lasciando che gli algoritmi ordinino liberamente le persone in base a migliaia di proteine del sangue, possiamo trovare gruppi naturali legati alla salute, confermare marcatori di malattia noti e scoprirne di nuovi. Man mano che le biobanche cresceranno fino a centinaia di migliaia di persone e ancora più proteine saranno misurate, questo tipo di esplorazione non supervisionata potrebbe aiutare i medici a rilevare le malattie prima, capire perché alcune persone si ammalano e altre no e indicare nuovi bersagli per futuri trattamenti.
Citazione: Bernard, E., Wang, Y., Chen, M. et al. Unsupervised learning reveals novel disease-associated proteins in high-dimensional human proteomic data. Sci Rep 16, 10185 (2026). https://doi.org/10.1038/s41598-026-41385-7
Parole chiave: proteine del sangue, apprendimento non supervisionato, biomarcatori, medicina di precisione, rischio di malattia